







1.英文文档词频统计
英文文档词频以英文原著爱丽丝梦游仙境为例,统计每个词在整部小说中出现的频率,并按词频从大到小进行排序。由于整本书所包含单词较多,为了便于展示,只输出词频大于10的单词。
代码如下所示:
# -*- coding: utf-8 -*-
"""
Created on Thu Jun 15 21:13:17 2017
@author: zch
"""
import string
#读取英文原著alice
path = 'E:/Python/data/NLP/alice.txt'
with open(path,'r',encoding= 'utf-8') as text:
#将所有的英文字母转换成小写
words = [raw_word.strip(string.punctuation).lower() for raw_word in text.read().split()]
#转换成集合形式
words_index = set(words)
#使用字典统计词频
counts_dict = {index:words.count(index) for index in words_index}
#按照词频从高到低排序
for word in sorted(counts_dict,key=lambda x: counts_dict[x],reverse=True):
if counts_dict[word] > 10:
print('{} -- {} times'.format(word,counts_dict[word]))
输出结果如下图所示:
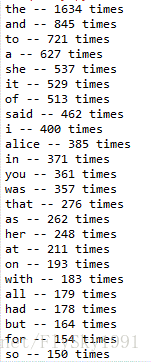
可以看到,在书中出现频次最高的十个单词依次为:”the“、“and”、“to”、“a”、”she“、”it“、“of”、“said”、”i“、”alice“。















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









