







用状态机进行文件字符分析的程序设计
1、 问题描述
设计C++ 类,使其能够统计文本文件中字符个数,在终端中显示结果,并将结果保存到指定的文件中。需要统计的字符有: a 、英文字母总数 b 、英文单词总数从 c 、中文字符总数(包括标点符号) d 、行总数 e 、其他字符总数(包括英文标点、空白符等)。
2、 问题分析
从问题描述中可以看到,我们所要做的就是将一篇文章(txt 格式,字符格式为 ANSI )中出现的中英文字符出现的次数进行统计。而一篇文本文件中出现的字符种类和顺序没有规律,如何对当前读取的字符的种类进行判断并转入到相应的统计状态成为了问题的关键。
但是,我们知道对于英文字母其ASCII 码范围在 65 ~ 90 和 97 ~ 122 两个区间,而英文单词的判断就是在相邻两个非英文字母之间夹着一串英文字母,所以我们可以在读取了第一个非英文字母后判断下一个读取的是否为英文字母,如果是便转入英文字符的处理状态,其中可同时对字母个数进行统计,在读到非英文字符时退出该状态,并将英文单词数加 1 ,然后转入“状态转换中心”进行状态转换的判断。
同理,对于中文字符的处理,也同上所述。但是由于中文字符占两个字节,而且各个编码格式中中文字符的编码范围不一致,所以处理起来比较麻烦,但是原理是一致的。在本例中仅对ANSI 格式的编码进行处理,所以中文字符每个字节的范围为 0x80 ~ 0xff ,不过在实际操作中发现有些中文字符还是被漏掉了,应该是中文字符的编码范围并没有全部包括进去的原因。
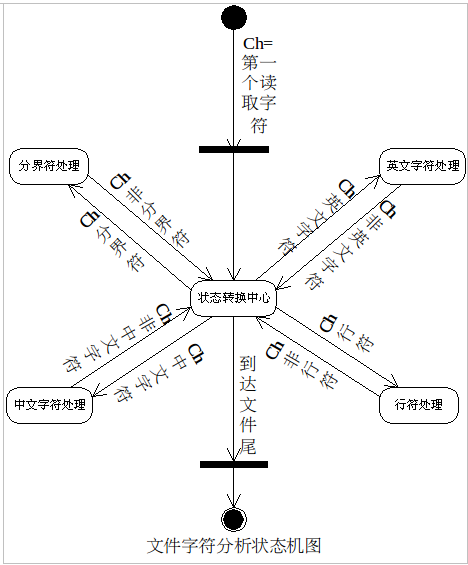
其他的字符处理没有什么难处,所以在此就不多述了。具体的见状态转换图吧。
3、 程序设计
首先,为类定义一个状态,如:
typedef enum{CHN,WORD,LIN,BOUND,PREPRO}SticState;
其中,CHN 表示“中文字符处理”状态, WORD 表示“英文字符处理”状态, LIN 表示“行符处理”状态, BOUND 表示“分界符处理”状态, PREPRO (预处理)就是“状态转换中心”。
字符统计程序如下:
file.get(ch);
SticState state=PREPRO;
while(1)
{
switch(state)
{
case CHN:
do{
if(ch!=中文字符 ) break ;
chnum++;
}while(file.get(ch));
state=PREPRO;
break;
case WORD:
do{
if(ch!=英文字符 ) break;
engnum++;
}while(file.get(ch));
wordnum++;
state=PREPRO;
break;
case LIN:
do{
if(ch!=行符 ) break;
linenum++;
}while(file.get(ch));
state=PREPRO;
break;
case BOUND:
do{
if( ch!=分界符 ) break;
boundnum++;
}while(file.get(ch));
state=PREPRO;
break;
case PREPRO:
if(到文件尾 )
{
if(当前非行符 ) linenum++;// 对文件结尾的处理,可能会有最后一行没有回 //车的情况
return;
}
else if(ch=分界符 ) state=BOUND;
else if(ch=英文字符 ) state=WORD;
else if(ch=中文字符 ) state=CHN;
else if(ch=行符 ) state=LIN;
break;
default:
cout<<"未知状态错误 !"<<endl;
break;
}
}
4、 总结
本程序采用状态机的思想完成了设计要求,虽然不尽完美,但是我们也能从中学到如何用状态机的思想来比较轻松的完成程序设计。从本例可以看出,通过状态机的思想可以使程序变得简单、清晰、明了。所以,我们应该充分利用好这一有利的工具为我们的程序设计增添光彩!
源码下载地址:http://download.csdn.net/source/1797902
另附状态机学习的文章一篇:
系统程序员成长计划-文本处理(INI解析器)















 2109
2109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









