







1 ERNIE-ViL(百度,2021.3.,aaai)
ERNIE-ViL是一个知识增强视觉-语言预训练模型,首次将场景图知识融入到多模态预训练中。
1.1 模型适用场景
ERNIE-ViL结合了从场景图中获得的结构化知识来学习视觉语言的联合表示,能够在视觉和语言之间建立详细的语义连接(对象、对象的属性和对象之间的关系)。
- 任务:适合于跨模态任务,如Visual Commonsense Reasoning(视觉常识推理)、Visual Question Answering(视觉问答)、Grounding Referring Expressions(看图识物)、Image Retrieval & Text Retrieval(图片检索&文本检索)
1.2 模型训练数据
- 数量:300万+80万。
- 来源:公开数据集。Conceptual Captions (CC) 数据集和SBU Captions (SBU)数据集,CC数据集包含330万图片-说明对,SBU数据集包含100万图片-描述对。由于链接断裂,CC数据集中的300万及SBU数据集中的80万对可用。
- 类型:图片-文本对。
- 训练资源及耗时:在8个V100 GPU上进行batch size为512的700k步的预训练。
1.3 模型架构及优化

- 输入:输入为一个句子和一张图片。对输入句子采用WordPiece方法转换为token,再将word embedding、segment embedding、position embedding相加。对输入图片,首先利用Faster R-CNN作为目标检测器检测图片区域,再将池化特征作为区域特征并为每个区域编码位置特征,并为每个区域编码位置特征
- 视觉-语言编码器:采用双流跨模态Transformer来联合模型的模态内和模态间表征。ERNIE-ViL包含两个并行的Transformer编码器,分别对图像和文本进行编码,并通过跨模态自注意力分别生成图像embedding和文本embedding。
- 场景图预测:ERNIE-ViL利用场景图解析器从句子中解析出场景图,从对场景图中获得的结构化知识加深跨模态的语义连接,即根据从文本中解析出的场景图,构造物体预测任务、属性预测任务和关系预测任务。

- 对视觉模态和交叉模态分别采用mask预测和图像-文本匹配,并将这些任务的loss相加。对于mask预测,随机mask15%的token,30%的场景图节点和15%的图像区域进行预测;对于图像-文本匹配,为每个文本随机选择一条图片,形成负图文对。


1.4 模型优缺点
- 优点:在跨模态预训练中,从场景图中获得的结构化知识得到了改进。
- 缺点:构造训练数据集较为复杂和不灵活。
2 CLIP(opai,2021.4.,ICML)
CLIP是一个基于无监督学习到的迁移性能好的的视觉网络。
代码和模型:https://github.com/OpenAI/CLIP
2.1模型适用场景
- 任务:适用于包含图像数据的任务,如OCR、视频中的行为识别、地理定位和细粒度对象分类等。
2.2 模型训练数据
- 数量:4亿对(图像、文本)。
- 来源:网络上收集的数据。
- 类型:图像-文本对。
- 训练资源及耗时:训练的最大的ResNet模型在592个V100 GPU上训练了18天,而训练的最大的 256个V100 GPU上训练了12天。
2.3 模型架构及优化

- 自然语言监督:CLIP的核心方法是从自然语言包含的监督学习中学习感知。通过监督学习不仅只是学习表征,还将该表征连接到语言,从而实现灵活的zero-shot迁移。
- 创建一个足够大的数据集:构建了一个新的数据集,包含4亿对(图像、文本)对,这些数据来自互联网。该数据集与GPT-2所用的WebText数据集具有相似的总字数。
- 预训练方法:为了提升计算效率,CLIP利用对比学习在给定一个有N对(图像,文本)对的批处理时,预测N*N对(图像,文本)对中哪一种实际发生。具体的,通过联合训练图像编码器和文本编码器,最大化N个正确(图像,文本)对embedding的余弦相似度,最小化N^2-N个错误(图像,文本)对embedding的余弦相似度。此外,CLIP利用一个线性映射将每个编码器的表征映射到多模态嵌入空间。
- 选择模型:
- 图像编码器分别选择ResNet-50和Vision Transformer (ViT)对图像进行编码。
- 文本编码器选择Transformer,利用字节对编码(BPE)及49152的词汇表大小对文本进行转化。

2.4 模型优缺点
- 优点:1)进行下游任务时,只需要提供和图上的概念对应的文本描述,就可以进行zero-shot transfer。2)CLIP可以很好地转换到大多数任务中,并且能与完全监督的baseline相竞争,而不需要任何数据集特定的训练。
- 缺点:1)CLIP与基于ResNet-50特征的简单线性baseline相比,性能具有竞争力,但在大多数这些数据集中,这些baseline远远低于总体技术水平。2)CLIP的zero-shot性能在一些任务中仍然很弱。例如,对于不太可能包含在CLIP预训练数据集中的新任务,如对照片中最近的汽车的距离进行分类,CLIP的性能几乎是随机的。
3 M6(阿里达摩院,2021.5.,ACM)
M6模型规模扩大到100亿个和1000亿个参数,是目前最大的中文预训练模型。
3.1 模型适用场景
- 任务:模型适用于单模态及多模态的理解和生成场景,具体的,有VQA(视觉问答)、image captioning(图片说明)、image-text matching(图像-文本匹配)、图像生成等。
3.2 模型训练数据
- 数量:1.9TB图像和292GB文本(是目前最大的中文预训练数据集,但数据未公开)。
- 来源:来源于百科全书,爬虫网页,社区问答,论坛,产品描述等。数据的覆盖范围广泛,如科学、娱乐、体育、政治、生活常识等。
- 类型:图像-文本对、纯文本数据。
- 训练资源及耗时:基于自研的Whale分布式训练框架,在128个NVIDIA A100上M6-100B预训练速度达到1440个样本/秒(对于序列长度为272的样本)。


3.3模型架构及优化
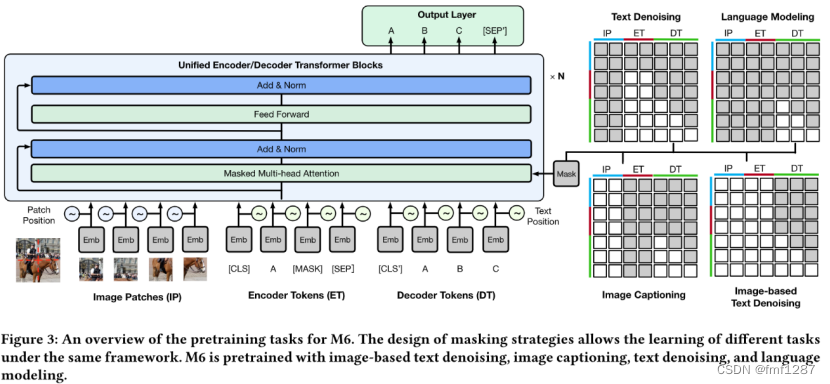
- 规模:10亿-100亿参数量。
- 输入
- 团队对电商图像数据抽样分析发现90%的图像包含的对象小于5个,且重叠度高,因此M6将图像分割成小块,然后使用经过训练好的ResNet-50提取二维小块的特征,再根据它们的位置将这些表征排列成一个序列。
- 类似于BERT,对输入的单词序列应用WordPiece和mask并映射为embedding。
- 统一编码器-解码器:将图像embedding和文本embedding合并为跨模态embedding,送入Transformer进行特征提取,最后添加了一个输出层用于单词预测。
- 预训练方法
- 文本到文本的转换:基于15%的比例,用一个掩码来mask连续的文本,模型学习解码整个序列。
- 图像到文本的转换:输入图像特征序列,将被mask部分的文本置空,模型学习对相应文本进行解码。
- 多模态到文本的转换:基于输入图像信息和带有噪声的文本预测被mask的部分文本。
- 扩展到100亿个和1000亿个参数:对100亿参数的版本,简单地通过超参数调优放大模型,即增加了隐藏状态的层数,并采用混合精度训练和activation checkpointing来节省内存。对1000亿参数的版本,基于Whale分布式训练框架实现GPU并行训练,并将Mixture-of-Experts(混合专家)与M6相结合,即每个FFN层为一个专家,多个FFN层并行,每个token只发给一小部分专家,MoE的输出是所选专家的线性组合。




3.4 模型优缺点
- 优点:能够处理多模态信息,进行单模态和跨模态的理解和生成,在下游任务上具备良好的通用性和卓越性能。模型资源要求相对较低,资源消耗仅为GPT-3的1%。
- 缺点:针对下游任务需要针对性进行架构和数据处理,并非一体化模型。
4 FLAVA(facebook,2022.3.)
4.1 模型适用场景
- 任务:适合于视觉任务、语言任务以及跨模态和多模态的视觉和语言任务。
4.2 模型训练数据
- 数量:7000万图像-文本对。
- 来源:从公开可用的图像-文本数据来源构建了一个语料库,去除非英文和单词数小于2的样本。
- 类型:图像-文本对。

4.3 模型架构及优化

- 模型架构
- 图像编码器:采用ViT架构,给定一个输入图像,将其缩放为固定的尺寸并将图像分割为patches,这些patches被线性嵌入并输入至Transformer。
- 文本编码器:给定一个文本输入片段,对齐进行tokenize并嵌入成一个词向量列表,然后应用Transformer将词向量编码为隐藏向量。
- 多模态编码器:使用一个单独的Transformer来融合图像和文本的隐藏状态,即在投影后的单模型图像和文本表示上应用交叉注意力,并融合两个模态。
- 应用于下游任务:能够直接应用在多模态或者单模态任务上。对于视觉识别任务,会在视觉编码器的单模态输出上应用分类头。类似地,对于语言理解和多模型推理任务,在文本编码器的输出或者多模态编码器输出上应用分类头。
- 多模态预训练目标
- 全局对比(GC)损失:对比损失函数类似于CLIP,给定一个batch的图像和文本,最大化正确匹配的文本和图像的cosine相似度,最小化其他不匹配的对。
- mask多模态建模(MMM):引入了一个mask多模态建模MMM预训练目标函数,该目标函数同时会遮蔽图像的patches和文本的tokens,同时预测输入图像和文本的被mask部分。
- 图像文本匹配(ITM):添加了一个图像-文本损失函数
- 单模态预训练目标
- mask图像建模(MIM):使用BEiT中的矩阵块masking图像的一部分patches并且从其他patches中重构他们。
- mask语言建模(MLM):输入的15%的tokens被mask,预测被mask的tokens。
- 使用单模态预训练初始化编码器:使用MIM或者DINO目标函数在纯图像数据集上训练图像编码器,之后单模态和多模态数据集同时训练。然后,使用单模态预训练的编码器来初始化整个FLAVA模型。
- 单模态和多模态联合训练:在图像编码器和文本编码器单模态预训练完后,继续在三种类型的数据集上使用循环抽样来联合训练整个FLAVA,在图像数据上应用单模态MIM,在文本数据上应用单模态MLM。

4.4 模型优缺点
- 优点:所用的数据集比最近的类似模型小了几个数量级,但仍然获得了更好的性能。
- 缺点:像所有的自然数据一样,所用的公开数据集有bias,可能会影响模型,需要进一步的研究来识别和减少潜在的有害偏见。
5 OFA(阿里达摩院,2022.6.,ICML)
OFA是一个实现了架构、模态、任务统一的多模态预训练模型。
代码及模型:https://github.com/OFA-Sys/OFA.
5.1 模型适用场景
- 任务:OFA是一个通用统一的模型,能够实现架构、模态、任务的统一,处理视觉-语言任务、仅视觉任务和仅语言任务。具体的,有image caption(图片说明)、visual question answering(视觉问答)、visual grounding(视觉定位)、visual entailment(视觉蕴含)、image classification(图像分类)、image generation(图像生成)、language understanding(语言理解)、language generation(文本生成)等。
5.2 模型训练数据
- 数量:预训练仅需要20M(2000万)公开的图像-文本对。
- 来源:为了便于复现,都为公开数据。
- 类型:图像-文本对、图像数据、文本数据。

5.3 模型架构及优化

- 规模:3300万-9.4亿参数量。
- I/O
- 为了简化数据预处理流程,利用ResNet模块对图像信息进行特征提取得到图像表征,并利用BPE(字节对编码)将文本转化为subword sequence,嵌入到特征中,并与图像表征进行拼接。
- 为了实现I/O统一,将文本、图像、坐标都融入到一个统一的词表中。对于图像,利用图像量化将图像输出进行离散化表示,并加入到词表中。由于模型的预训练任务包括grounded captioning,visual grouding以及object detection需要处理坐标信息,OFA将连续的坐标信息转化成离散化的表征(即提取对象的标签和边界框,边界框被离散化为整数作为位置标记<x1,y1,x2,y2>,标签为单词,可用BPE标记表示)。
- 架构:将任务均表达为序列到序列的模式,利用Transformer的编码器、解码器进行预训练、精调,均使用生成范式进行训练。
- 任务和模式,为了学习跨模态表征,设计了5个任务:
- visual grounding (VG),根据输入图像和指令"文本xt描述的是哪个区域?"生成指定区域位置的位置标记<x1,y1,x2,y2>。
- grounded captioning (GC),VG任务的反向,根据输入图像和指令"区域<x1,y1,x2,y2>描述了什么?"生成描述。
- image-text matching (ITM),对图像-文本对是否匹配进行判别。
- image captioning (IC),根据输入图像和指令"该图像描述了什么"生成说明文字。
- visual question answering (VQA),根据图像和问题生成正确回答。
- 为了学习单模态表征,设计了2个视觉任务和1个语言任务:
- 图像填充。
- 目标检测。
- 文本填充。
- OFA将多模态和多任务统一到一个单一的模型中,可以执行自然语言、视觉、跨模态的任务。给定输入x,指令s,输出y后,优化交叉熵:




5.4 模型优缺点
- 优点:1)将多模态任务表达为序列到序列生成的形式,实现了架构、模态和任务的统一,不需要针对任务设计特定的模型层。2)与仅处理单一类型数据(如,仅处理跨模态数据)的多模态模型相比,可以处理更多的单模态、跨模态任务,在单模态任务上与SOTA单模态模型性能相当,在视觉-语言任务上取得了SOTA表现。3)在zero-shot学习上能够取得不错的表现,另外,OFA也可以有效地迁移到未见过的任务和未见过的领域。4)仅需要2000万公开图像-文本对进行训练,训练简单。
- 缺点:模型的性能与指令的设计高度敏感,应当尽可能从大量的候选指令中寻找合适的指令模板,对手动提示或模型参数的轻微更改可能会极大地影响模型性能。
6 BEiT-3(微软,2022.8.,ICLR)
BEiT-3是将图像视为一种外语,用于视觉、视觉-语言任务的预训练多模态模型。
6.1 模型适用场景
- 任务:适用于视觉任务、视觉-语言任务,如object detection (目标检测),semantic segmentation (图像分割),image classification (图像分类),visual reasoning (视觉推理),visual question answering (视觉问答),image captioning (图片说明), cross-modal retrieval (跨模态信息检索)。
6.2 模型训练数据
- 数量:多模态数据有1500万图像和2100万图像-文本对,单模态数据中有1400万图像和160GB文本。
- 来源:公开数据集。
- 类型:单模态和多模态数据。

6.3 模型架构及优化

核心思想是将图像建模为一种外语,这样我们就可以对图像、文本和图像-文本对进行统一的遮蔽“语言”建模。
- 规模:19亿参数。
- 骨干网络——多路Transformer:利用多路Transformer对不同模态进行编码,每个Transformer由一个共享的自注意力模块和一个用于不同模态的FFN池(即模态专家)。BEiT中包含40层多路Transformer。
- 预训练任务——mask数据建模:在多模态数据和单模态数据上通过一个统一的mask数据建模训练BEiT-3。对文本,随机mask单模态文本中的15%和图像文本对中文本的50%。对图像,利用块mask策略对图像中的40%的像素块进行mask。训练BEiT以恢复被mask的标记。

6.4 模型优缺点
- 优点:方法简单有效,有效地建模不同的视觉和视觉-语言任务,可以进行通用建模。利用自监督学习,更符合未来趋势。
- 缺点:未能证明在纯语言任务上获得良好的效果(论文团队正在引入音频、多语言等,以促进跨语言和跨模态的转换)。
7 PaLI(google,2022.9.)
PaLI是一个多语言、多任务通用的视觉语言模型。
7.1 模型适用场景
- 任务:适用于多语言和图像理解场景,能够处理单模态和多模态任务,如Image Captioning(图片描述)、Visual Question Answering(视觉问答)、Language-understanding(语言理解任务)、Zero-shot Image Classification(zero shot图片分类)。
7.2 模型训练数据
- 数量:100亿。
- 来源:WebLI数据集,包含超过100种语言的100亿图像-文本。
- 类型:多语言的图像-文本对。
- 训练资源及耗时:最大的PaLI-17B模型使用1024个GCP-TPUv4芯片预训练了7天。
7.3 模型架构及优化

- 规模:30-170亿参数
- 视觉部分:引入预训练过的ViT(Vision Transformer),即将图片二维向量处理为一维向量送入Transformer进行特征提取。分别训练两个ViT,一个带有inception crop augmentation,另一个不带,最后取平均。
- 语言部分:引入预训练过的mT5作为语言模型主干,经过编码器和解码器得到输出。
- 预训练任务:
- MLM任务,随机mask15%的token再预测。
- Split Captioning任务,将每个文本切分成两部分<cap1>和<cap2> ,输入加入prompt:Generate the alt_text in <lang> at <pos>: <cap1>: <extra_id_0>”,目标是输出<cap2>。
- caption任务和OCR任务,输入加入prompt:“Generate the alt_text in <lang> at 0: <extra_id_0>”和“Generate the ocr_text in <lang>”,目标是输出说明或OCR结果。
- 英语和多语言的VQA和VQG任务,输入加入prompt:Answer in EN: [question] <extra_id_0>”,目标是输出回答/问题。
- Object-Aware (OA) VQA任务,输入加入prompt:1)让模型列出物体,prompt是“List the objects present: <extra_id_0>”。2)判断单个物体是否存在,prompt就是“Is <objectk> in the image? <extra_id_0>”。3)判断多个物体是否存在,prompt就是“Is <object1>, ..., <objectN> in the image? <extra_id_0>”。4)从一堆物体里面判断哪些物体存在,prompt就是“Which of <object1>, ..., <objectN> are in the image? <extra_id_0> ”。
- 目标检测任务,prompt的前缀是“detect”,目标是输出界框坐标和物体标签。

7.4 模型优缺点
- 优点:能够处理多语言、多模态的任务。
- 缺点:1)由于大多数源数据没有复杂的注释,模型可能不能非常彻底地描述一个具有许多对象的复杂场景。2)当再仅包含英文的数据上进行微调时,多语言的能力将丢失,理想情况下应需要多语言数据集上微调。
















 904
904











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









