









统计学习方法-k近邻
k近邻方法是一种惰性学习算法,可以用于回归和分类,它的主要思想是投票机制,对于一个测试实例 x j x_j xj, 我们在有标签的训练数据集上找到和最相近的k个数据,用他们的label进行投票,分类问题则进行表决投票,回归问题使用加权平均或者直接平均的方法。
算法和模型
由于这个模型很容易理解,我们直接给出kNN分类模型其算法伪代码:
输入:训练数据
T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x N , y n ) } T=\{(x_1,y_1),(x_2,y_2),...,(x_N,y_n)\} T={(x1,y1),(x2,y2),...,(xN,yn)}
其中 x i ∈ R n x_i \in R^n xi∈Rn,是实例的特征向量, y i ∈ Y = { c 1 , c 2 , . . . , c K } y_i \in Y = \{c_1,c_2,...,c_K\} yi∈Y={c1,c2,...,cK},表示类别,
输出: 实例x所属的类别
- 根据跟定的距离度量的方法,在T中找到和x最邻近的k个点,记作x的邻域, N k ( x ) N_k(x) Nk(x)
- 在 N k ( x ) N_k(x) Nk(x)中使用多数表决规则,绝对x的类别y:
y = a r g m a x c j ∑ x i ∈ N k ( x ) I ( y i = c j ) y=argmax_{c_j} \sum_{x_i \in N_k(x)}I(y_i=c_j) y=argmaxcjxi∈Nk(x)∑I(yi=cj)- 对于回归问题,得到y
y = 1 k ∑ x i ∈ N k ( x ) y i y= \frac{1}{k} \sum_{x_i \in N_k(x)}y_i y=k1xi∈Nk(x)∑yi
其中 i = 1 , 2 , . . . , N ; j = 1 , 2 , . . . , K i=1,2,...,N; j=1,2,...,K i=1,2,...,N;j=1,2,...,K.
从上述算法中,我们可以看到,kNN没有显示的训练和学习模型的过程,这是一个惰性的学习方法,主要有两个点需要我们关注,一个是距离的度量,另一个是超参数k值的选择,接下来我们就来考虑这两个问题。
距离的度量
我们刚才提到KNN的一个关键点就是如何度量距离,对于两个向量 ( x i , x j ) (x_i, x_j) (xi,xj),一般使用 L p L_p Lp距离进行计算。
假设特征空间 X X X是n维实数向量空间 R n R^n Rn, 其中, x i , x j ∈ X x_i,x_j \in X xi,xj∈X,
x i = ( x i ( 1 ) , x i ( 2 ) , . . . , x i ( n ) ) , x j = ( x j ( 1 ) , x j ( 2 ) , . . . , x j ( n ) ) x_i=(x_i^{(1)},x_i^{(2)},...,x_i^{(n)}),x_j=(x_j^{(1)},x_j^{(2)},...,x_j^{(n)}) xi=(xi(1),xi(2),...,xi(n)),xj=(xj(1),xj(2),...,xj(n)), 则 x i , x j x_i,x_j xi,xj的L_p距离定义为:
L p ( x i , x j ) = ( ∑ l = 1 n ∣ x i ( l ) − x j ( l ) ∣ p ) 1 p L_p(x_i,x_j) = \left( \sum_{l=1}^{n}|x_i^{(l)}-x_j^{(l)}|^p \right) ^ {\frac{1}{p}} Lp(xi,xj)=(l=1∑n∣xi(l)−xj(l)∣p)p1
这里的 p ≥ 1 p \geq 1 p≥1. 当p=2时候,称为欧氏距离(Euclidean distance), 有
L 2 ( x i , x j ) = ( ∑ l = 1 n ∣ x i ( l ) − x j ( l ) ∣ 2 ) 1 2 L_2(x_i,x_j) = \left( \sum_{l=1}^{n}|x_i^{(l)}-x_j^{(l)}|^2 \right) ^ {\frac{1}{2}} L2(xi,xj)=(l=1∑n∣xi(l)−xj(l)∣2)21
当p=1时候,称为曼哈顿距离(Manhattan distance), 有
L 1 ( x i , x j ) = ∑ l = 1 n ∣ x i ( l ) − x j ( l ) ∣ L_1(x_i,x_j) = \sum_{l=1}^{n}|x_i^{(l)}-x_j^{(l)}| L1(xi,xj)=l=1∑n∣xi(l)−xj(l)∣
当 p = ∞ p=\infty p=∞时候,称为极大距离(infty distance), 表示各个坐标的距离最大值, 有
L p ( x i , x j ) = max l n ∣ x i ( l ) − x j ( l ) ∣ L_p(x_i,x_j) = \max_{l}{n}|x_i^{(l)}-x_j^{(l)}| Lp(xi,xj)=lmaxn∣xi(l)−xj(l)∣
使用距离计算的时候,我们一般使用欧氏距离,一般情况下都是将数据转化成实数向量的形式,使用距离度量方式,找到最近的k个值,进行投票打分.
k值的选择
kNN中的k是一个超参数,需要我们进行指定,一般情况下这个k和数据有很大关系,都是交叉验证进行选择,但是建议使用交叉验证的时候, k ∈ [ 2 , 20 ] k \in [2,20] k∈[2,20], 使用交叉验证得到一个很好的k值。
k值还可以表示我们的模型复杂度,当k值越小意味着模型复杂度表达,更容易过拟合,(用极少树的样例来绝对这个预测的结果,很容易产生偏见,这就是过拟合)。我们有这样一句话,k值越多学习的估计误差越小,但是学习的近似误差就会增大.
如何理解这句,估计误差表示最后的结果,k值大,集百家所长,更可能得到准确的值,表示估计的准确,则误差就小;但是我们的估计的时候,在学习过程中,使用最相近的k个实例进行估计,每一个值都会和预测的x有一个近似误差,k越大则误差的总和就越大。
这里我们提一句,多数表决等价于经验风险最小化。这个证明也很简单,这里就不给出了,有兴趣的请看: 《统计学习方法》第40页 分类决策规则. 多说一句,既然要求误差,那就写出误差损失函数,剩下的就是公式恒等变化了.
kd 树
kNN,从上述算法中,我们可以看到主要是从训练数据中,知道k个相近实例,但是每次都要便利这个数据集合,主要的问题就是速度慢. 这时候就出现了加速查找的数据结构,其中之一就是kd 树.
构造kd 树
kd树是一种对k维空间中的实例店进行存储以便能够进行快速检索的数据结构. kd树是一个二叉树,表示对k维空间的一个划分. 构造kd树就是不断用垂直于坐标轴的超平面 (一般用每一个维度的中位数来表示) 将k维空间划分,构成一系列的k维超矩形区域.
伪代码: (from wikipedia)
function kdtree (list of points pointList, int depth)
{
// Select axis based on depth so that axis cycles through all valid values
var int axis := depth mod k;
// Sort point list and choose median as pivot element
select median by axis from pointList;
// Create node and construct subtree
node.location := median;
node.leftChild := kdtree(points in pointList before median, depth+1);
node.rightChild := kdtree(points in pointList after median, depth+1);
return node;
}
基于kd树查找最近邻
构造kd树的目的就是快速查找最近邻和k近邻,这里我们给出二维的列子,这里例子来自与书中和
wiki百科,我尝试说明百这几张图的运行原理.
数据 T = {(2,3), (5,4), (9,6), (4,7), (8,1), (7,2)}
构造kd树,二叉树和空间角度的划分图,再次注意每一次用的这个维度对应的所有这个空间中的中位数.根据x维度有{2,4,5,7,8,9}: 中位数是7,因此(7,2)作为根节点,x < 7,在左子树,其他在右子树。依次递归构造左右子树,下一次根据维度y,之后根据维度x. 注意这里的k是维度,n 可能大学k,故要每次对k取余数. (这个k不是kNN中的k). 
二叉树划分图下面的空间划分图,表示空间上的显示格式. 其实整体的搜索是在这个空间上进行的.

空间划分图
下面用一个gif图来表示搜索最近邻的过程,简单来说就是一句话,根据构造过程,从头到尾左右二分,在这个过程中记录下来最近的点。从这个图中,我们可以看到,我们目标实例target用四角星表示,
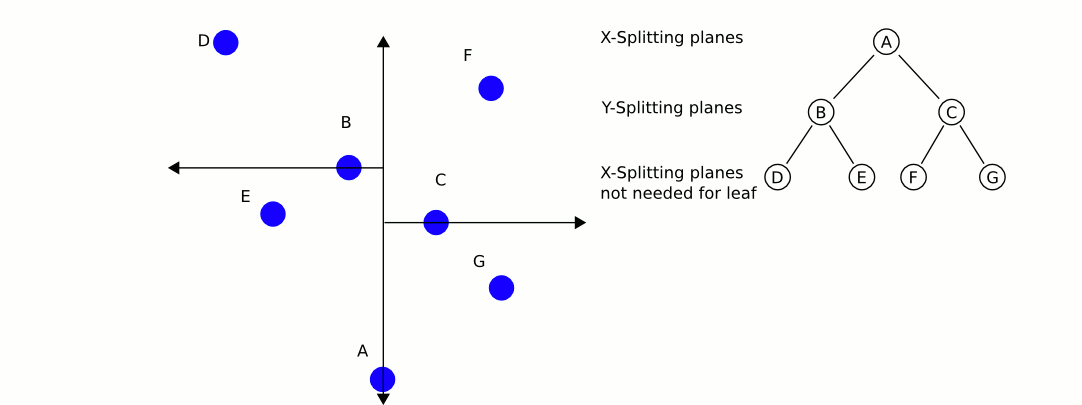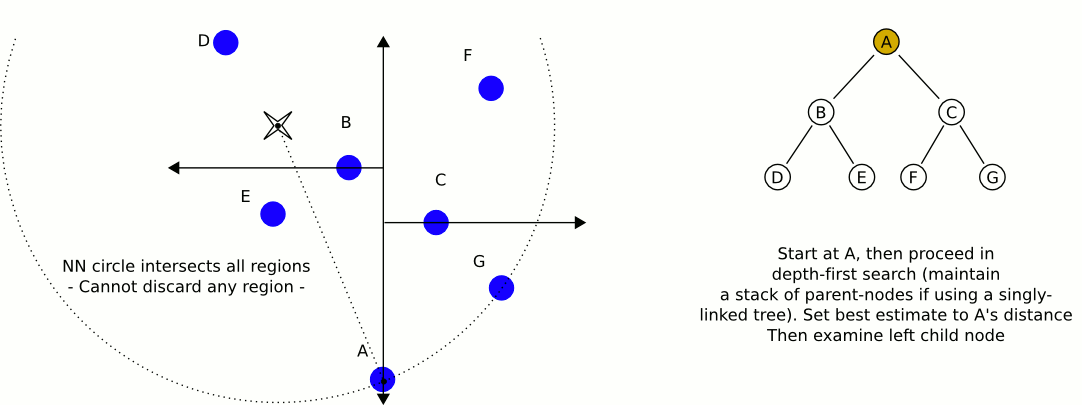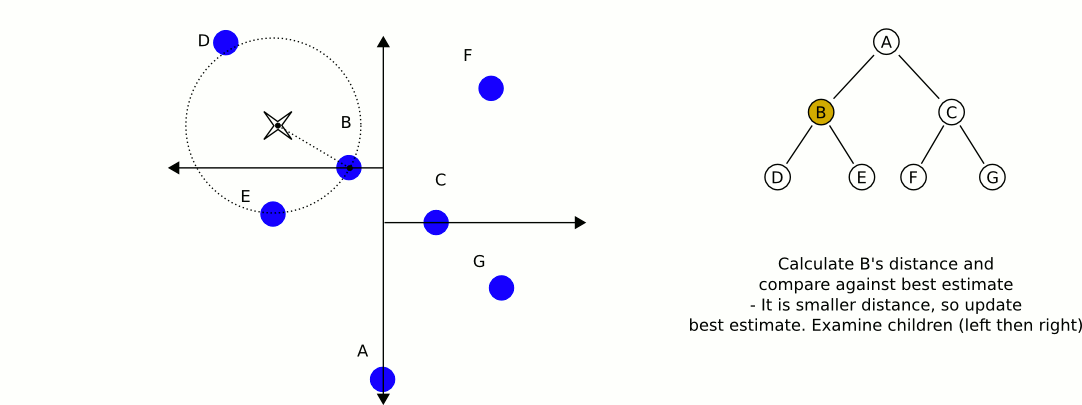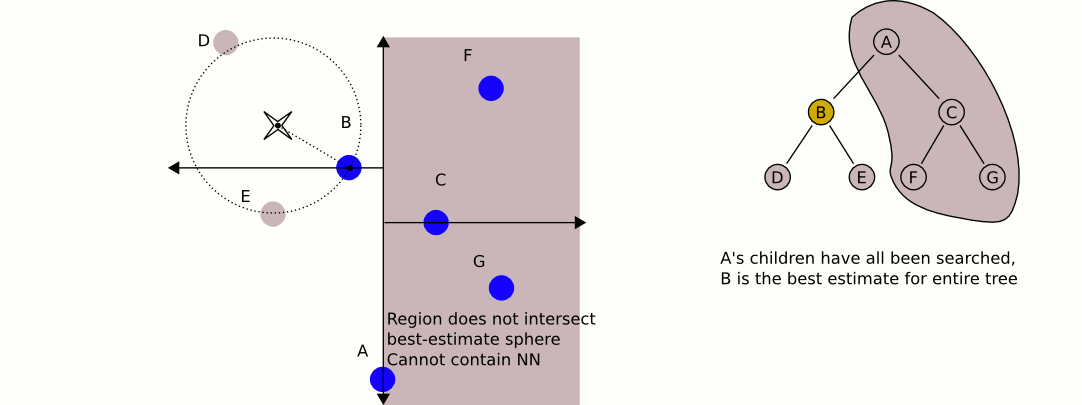
空间划分图
- 二叉树搜索,依次到叶子节点D,路劲是A - B - D. 这个过程中最近的点是B,作为最有候选集合.
- 我们以target为圆心,target到B的距离为半径,画圆,我们发现,B的另外的部分与圆相交,这表示,可能存在更近的候选点在另半部分,如果不存在相交,此时的候选点B就是最近点。
- 如果存在和其他空间相交,则将搜索空间上升为其父节点,用target和其父节点距离作圆,如果依然和其他空间相交,继续回溯搜索,直到不想交或者全部搜索完毕找到候选点.
- 上面介绍的是最近邻查找,如何查找k近邻?
- 使用各最大堆数据结果,维护k大小的最大堆,从根节点开始如果堆的大小不足k,就候选集如果
- 如果大小为k,就比较堆顶元素和当前元素的距离大小,如果当前小于堆顶距离就进行替换,
- 之后以堆顶元素为中心,就编程了找最近邻问题。最后返回结果
总结
kNN简单好用,但是最主要的是这个思想,多数投票加权平均。kd树只是一种加速的方法,还有kd平衡树,ball tree等,这也是一种思想,并不是准则。KNN和kd tree的代码稍后便到。
注:生活如此,问题不打。喵~















 3502
3502











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









