









目录
一、赛题描述
赛事链接:https://www.datafountain.cn/competitions/351
1.1 赛题背景
- 在高端制造领域,随着数字化转型的深入推进,越来越多的数据可以被用来分析和学习,进而实现制造过程中重要决策和控制环节的智能化,例如生产质量管理。从数据驱动的方法来看,生产质量管理通常需要完成质量影响因素挖掘及质量预测、质量控制优化等环节,本赛题将关注于第一个环节,基于对潜在的相关参数及历史生产数据的分析,完成质量相关因素的确认和最终质量符合率的预测。在实际生产中,该环节的结果将是后续控制优化的重要依据。
1.2 赛题任务
- 由于在实际生产中,同一组工艺参数设定下生产的工件会出现多种质检结果,所以我们针对各组工艺参数定义其质检标准符合率,即为该组工艺参数生产的工件的质检结果分别符合优、良、合格与不合格四类指标的比率。相比预测各个工件的质检结果,预测该质检标准符合率会更具有实际意义。
本赛题要求参赛者对给定的工艺参数组合所生产工件的质检标准符合率进行预测。
1.3 数据说明
- 【数据简介DATA BACKGROUD】
在此任务中,以某典型工件生产过程为例,我们将提供给参赛者一系列工艺参数,以及在相应工艺参数下所生产工件的质量数据。该数据来源于某工厂采集的真实数据,已做脱敏处理。
(1)训练数据将提供:
A:工艺参数(如设备加工参数)
B:工件的质量数据
C:工件所符合的质检指标
(2)测试数据将提供:
A:工艺参数(如设备加工参数)
【数据说明DATA DESCRIPTION】
(1)初赛训练数据集文件名称为first_round_training_data.csv,csv格式,其中包含21个字段,6000行,含A,B,C三类数据,具体信息如下:
| 字段类型 | 字段名 | 数据类型 | 取值范围 | 字段解释 |
|---|---|---|---|---|
| A | Parameter1 | Float | (0,3.9e+09] | 工艺参数1 |
| A | Parameter2 | Float | (0,1.4e+09] | 工艺参数2 |
| A | Parameter3 | Float | (0,2.9e+09] | 工艺参数3 |
| A | Parameter4 | Float | (0,3.7e+08] | 工艺参数4 |
| A | Parameter5 | Float | (0,70] | 工艺参数5 |
| A | Parameter6 | Float | (0,43] | 工艺参数6 |
| A | Parameter7 | Float | (0,2.4e+04] | 工艺参数7 |
| A | Parameter8 | Float | (0,7.6e+04] | 工艺参数8 |
| A | Parameter9 | Float | (0,6.1e+08] | 工艺参数9 |
| A | Parameter10 | Float | (0,1.5e+04] | 工艺参数10 |
| B | Attribute1 | Float | (0,1.2e+07] | 工件属性1 |
| B | Attribute2 | Float | (0,3.2e+08] | 工件属性2 |
| B | Attribute3 | Float | (0,5.1e+09] | 工件属性3 |
| B | Attribute4 | Float | (0,6.3e+07] | 工件属性4 |
| B | Attribute4 | Float | (0,6.4e+09] | 工件属性5 |
| B | Attribute4 | Float | (0,2.6e+07] | 工件属性6 |
| B | Attribute4 | Float | (0,8.5e+09] | 工件属性7 |
| B | Attribute4 | Float | (0,5.6e+10] | 工件属性8 |
| B | Attribute4 | Float | (0,1.8e+12] | 工件属性9 |
| B | Attribute4 | Float | (0,2.0e+11] | 工件属性10 |
| C | Quality_label | Categorical | {Fail, Pass, Good, Excellent} | 工件所符合的质检指标,包括四类,其中Fail: 质检不合格;Pass:质检合格;Good:质检结果为良;Excellent:质检结果为优。 |
(2)初赛测试数据集文件名称为first_round_testing_data.csv,包含11个字段,仅提供A类数据,具体信息如下:
| 字段类型 | 字段名 | 数据类型 | 取值范围 | 字段解释 |
|---|---|---|---|---|
| ID | Group | Int | 0,1,2,……,N-1 | 测试集工件数据点所对应的工艺参数组别。 |
| A | Parameter1 | Float | (0,3.9e+09] | 工艺参数1 |
| A | Parameter2 | Float | (0,1.4e+09] | 工艺参数2 |
| A | Parameter3 | Float | (0,2.9e+09] | 工艺参数3 |
| A | Parameter4 | Float | (0,3.7e+08] | 工艺参数4 |
| A | Parameter5 | Float | (0,70] | 工艺参数5 |
| A | Parameter6 | Float | (0,43] | 工艺参数6 |
| A | Parameter7 | Float | (0,2.4e+04] | 工艺参数7 |
| A | Parameter8 | Float | (0,7.6e+04] | 工艺参数8 |
| A | Parameter9 | Float | (0,6.1e+08] | 工艺参数9 |
| A | Parameter10 | Float | (0,1.5e+04] | 工艺参数10 |
要求参赛者基于A类数据计算出各组工艺参数的工件质检标准符合率。
1.4 提交示例 SUBMITTED SAMPLE
- 初赛阶段提交csv文件的示例参见example_result.csv。
1.5 评测标准GRADING
本次竞赛初赛评价指标使用MAE系数。
平均绝对差值是用来衡量模型预测结果对标准结果的接近程度一种衡量方法。计算方法如下:
其中predi为预测样本,yi 为真实样本。MAE的值越小,说明预测数据与真实数据越接近。
最终结果为:
最终结果越接近1分数越高.
二、数据导入
2.1 导库
# 导库
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score,log_loss
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import GridSearchCV
import warnings
warnings.filterwarnings('ignore')
2.2 数据读取
# 数据读取
train_data = pd.read_csv('.../first_round_training_data.csv')
test_data = pd.read_csv('.../first_round_testing_data.csv')
submit = pd.read_csv('.../submit_example.csv')
2.3 数据观察
print(train_data.describe())
print(test_data.describe())



train_data.head(10)

三、数据预处理
3.1 标签处理
对Quality_label 进行数值处理
# 对Quality_label 进行数值处理
# {Fail, Pass, Good, Excellent}
dic = {'Excellent': '0', 'Good': '1', 'Pass': '2', 'Fail': '3'}
train_data['Quality_label'] = train_data["Quality_label"].map(dic)
3.2 检查缺失值
# 缺失值检查
print(train_data.isnull().sum())

3.3 数值分析
由于matplotlib在绘图时,出现中文显示问题,使用如下代码进行修改
#解决matplotlib绘图中文显示问题
plt.rcParams['font.sans-serif'] = ['SimHei']
# plt.rcParams['font.sans-serif'] = ['KaiTi'] # 指定默认字体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
对数据进行连续性和离散型分析
# 连续性和离散型分析
col_name = train_data.columns
Notdlts_count = []
for i in col_name:
# 计算非重复值的个数 drop_duplicates:去除重复值
Notdlts = len(train_data[i].drop_duplicates())/6000
Notdlts_count.append(Notdlts)
plt.figure(figsize=(20,5))
plt.plot(col_name, Notdlts_count, c='r')
plt.title('计算非重复值的占比') # 标题
plt.xlabel('字段名') # x轴 的轴名
plt.ylabel('非重复数据在全数据上的占比') # y轴 的轴名
plt.xticks(rotation=90) # 旋转 x轴的刻度
for x,y in zip(col_name,Notdlts_count):
plt.text(x,y,'%.3f' % y,fontdict={'fontsize':15}) #对图像每个点进行标注具体比例
plt.show()

由图可知,Parameter 5 - 10 基本为离散特征,而 Attribute 4 - 10 有可能是离散特征, 其余均为连续特征
3.4 数据划分
根据数值分析得出的结论,Parameter 5 - 10 基本为离散特征。 Attribute 4 - 10 有可能是离散特征,但是在test中无可用数据,后期可以对train数据集进行训练,从而得出test数据集中的Attribute,加大特征,从而可以将A和B列全部考虑,并进行筛选特征,我猜测,这样操作或许可以提高score。
# 数据划分
data = train_data.append(test_data)
feature_name = ['Parameter{0}'.format(i) for i in range(5, 11)]
tr_index = ~data['Quality_label'].isnull()
X_train = data[tr_index][feature_name].reset_index(drop=True)
y = data[tr_index]['Quality_label'].reset_index(drop=True).astype(int)
X_test = data[~tr_index][feature_name].reset_index(drop=True)
生成(6000,4)的0矩阵,为下面的结果保存做准备
print(X_train.shape,X_test.shape) # (6000, 6) (6000, 6)
# oof = np.zeros((X_train.shape[0],4)) # (6000,4)
pred = np.zeros((X_test.shape[0],4)) # (6000,4)
4、模型训练
本文选择如下模型进行训练:
1.SVC
2.GradientBoostingClassifier
3.CatboostClassifier
下面在模型训练时候,有以下几个不解之处,已给出对应回答。
选择predict_proba 而不是predict的原因
predict是训练后返回预测结果,是标签值。
predict_proba返回的是一个 n 行 k 列的数组, 第 i 行 第 j 列上的数值是模型预测 第 i个预测样本为某个标签的概率,并且每一行的概率和为1。
np.eye(4)返回的是一个四维的数组(N,M),对角线的地方为1,其余的地方为0.用于映射Quality_label对应的标签
pandas.get_dummies(data, prefix=None, prefix_sep=’_’, dummy_na=False,columns=None, sparse=False, drop_first=False, dtype=None)
pandas 中的get_dummies 方法主要用于对类别型特征做 One-Hot 编码(独热编码)
4.1 SVC
# SVC线上有效得分:0.48324507000 分
def svc(X_train, y, X_test):
model = SVC(probability=True)
model.fit(X_train,y)
pred = model.predict_proba(X_test)
MAE = 1/(1 + np.sum(np.absolute(np.eye(4)[y] - pred))/480)
svc_score = 1/(1+10*MAE)
print('log_loss',log_loss(pd.get_dummies(y).values, pred))
print('svc_ac',accuracy_score(y, np.argmax(pred,axis=1)))
print('MAE',1/(1 + np.sum(np.absolute(np.eye(4)[y] - pred))/480))
print('svc_score',1/(1+10*MAE))
print('--------------------------------')
return model
4.2 GradientBoostingClassifier
# gdbt线上有效得分:0.46390095000 分
def gdbt():
model =GradientBoostingClassifier()
model.fit(X_train,y)
# oof = model.predict_proba(X_test)
# prediction = model.predict_proba(X_test)
pred = model.predict_proba(X_test)
MAE = 1/(1 + np.sum(np.absolute(np.eye(4)[y] - pred))/480)
gdbt_score = 1/(1+10*MAE)
print('log_loss',log_loss(pd.get_dummies(y).values, pred))
print('gbdt_ac',accuracy_score(y,np.argmax(pred,axis = 1)))
print('MAE',1/(1 + np.sum(np.absolute(np.eye(4)[y] - pred))/480))
print('gdbt_score',1/(1+10*MAE))
print('--------------------------------')
return model
4.3 CatBoostClassifier
# cbt 线上有效得分:0.46392205000分
def cbt():
model = CatBoostClassifier()
model.fit(X_train,y)
pred = model.predict_proba(X_test)
MAE = 1/(1 + np.sum(np.absolute(np.eye(4)[y] - pred))/480)
gdbt_then_score = 1/(1+10*MAE)
print('log_loss',log_loss(pd.get_dummies(y).values, pred))
print('cbt_ac',accuracy_score(y,np.argmax(pred,axis = 1)))
print('MAE',1/(1 + np.sum(np.absolute(np.eye(4)[y] - pred))/480))
print('cbt_score',1/(1+10*MAE))
print('--------------------------------')
return model
4.4 结果显示
if __name__ == '__main__':
svc(X_train, y, X_test)
svc_then()
gdbt()
gdbt_then()
cbt()
cbt_then()
model_mix()



通过三组数据,可以发现,在未调参之前的,线下:SVC的Score> GradientBoostingClassifier 的Score>CatBoostClassifier的Score。
至此,思考是否通过调参和模型融合会对得分有所提高。
5、调参
5.1 SVC调参
5.1.1 参数调节:
# SVC 调参
# 调参发现C调整结果反而降低,索性不对C进行调参
# 初始参数
# SVC(C=1.0,kernel='rbf',degree=3,gamma='scale')
# params = {'C': 1.0, 'kernel': 'rbf', 'gamma': 'auto'}
# kernel : {'linear', 'poly', 'rbf', 'sigmoid', 'precomputed'},gamma : {'scale', 'auto'}
svc_then_params = { 'gamma': 'auto'}
# params_then_grid = { 'gamma': 'auto'}
# params_grid = { 'gamma': 'auto'}
# param_grid = {'gamma' :['scale','auto']}
# m = GridSearchCV(SVC(),params_grid)
# m.fit(X_train,y)
# print("该参数下得到的最佳得分为:{}".format(m.best_score_))
# print("最佳参数为:{}".format(m.best_params_))
5.1.2 SVC新模型
# svc_then线上有效得分:分
def svc_then():
model =SVC(probability=True,**svc_then_params)
model.fit(X_train,y)
# oof = model.predict_proba(X_test)
# prediction = model.predict_proba(X_test)
pred = model.predict_proba(X_test)
MAE = 1/(1 + np.sum(np.absolute(np.eye(4)[y] - pred))/480)
gdbt_then_score = 1/(1+10*MAE)
print('log_loss',log_loss(pd.get_dummies(y).values, pred))
print('svc_then_ac',accuracy_score(y,np.argmax(pred,axis = 1)))
print('MAE',1/(1 + np.sum(np.absolute(np.eye(4)[y] - pred))/480))
print('svc_then_score',1/(1+10*MAE))
print('--------------------------------')
return model
5.2 GradientBoostingClassifier调参
5.2.1 参数调节:
# gdbt调参
#
# c初始参数
# params = {'learning_rate': 0.1, 'n_estimators': 10, 'min_samples_split': 300, 'min_samples_leaf': 20, 'max_depth': 8,
# 'max_features':'sqrt', 'subsample': 0.8 }
# 内部节点再划分所需最小样本数min_samples_split、叶子节点最少样本数min_samples_leaf、决策树最大深度max_depth
# 最大特征数max_features、不放回抽样subsample 推荐在[0.5, 0.8]之间,默认是1.0,即不使用子采样
gdbt_then_params = {'learning_rate': 0.1, 'n_estimators': 52, 'min_samples_split':809, 'min_samples_leaf': 70, 'max_depth': 5,
'max_features':'sqrt', 'subsample': 0.8 }
# param_grid = {#'n_estimators':range(1,100,1),
# #'max_depth':range(5,14,1),
# #'min_samples_split':range(10,1000,100)}
# #'min_samples_split':range(800,825,1),
# #'min_samples_leaf': range(10,100,10)}
# #'max_features':('sqrt','log2'),
# #'subsample':range(0.5,0.8,0.05)}
# m = GridSearchCV(GradientBoostingClassifier(),param_grid)
# m.fit(X_train,y)
# print("该参数下得到的最佳得分为:{}".format(m.best_score_))
# print("最佳参数为:{}".format(m.best_params_))
5.2.2 GradientBoostingClassifier新模型
# gdbt_then线上有效得分:0.46390095000分
def gdbt_then():
model =GradientBoostingClassifier(**gdbt_then_params)
model.fit(X_train,y)
# oof = model.predict_proba(X_test)
# prediction = model.predict_proba(X_test)
pred = model.predict_proba(X_test)
MAE = 1/(1 + np.sum(np.absolute(np.eye(4)[y] - pred))/480)
gdbt_then_score = 1/(1+10*MAE)
print('log_loss',log_loss(pd.get_dummies(y).values, pred))
print('gbdt_then_ac',accuracy_score(y,np.argmax(pred,axis = 1)))
print('MAE',1/(1 + np.sum(np.absolute(np.eye(4)[y] - pred))/480))
print('gdbt_then_score',1/(1+10*MAE))
print('--------------------------------')
return model
5.3 CatBoostClassifier调参
5.3.1 参数调节:
# cbt调参
#
# c 初始化参数
# params = {'learning_rate' : 0.086, 'iterations': 1000, 'verbose': 300, 'task_type': 'GPU','loss_function': 'MultiClass'}
# cbt_then_params = {'learning_rate' : 0.05, 'iterations': 700, 'verbose': 300,'loss_function': 'MultiClass'}
cbt_then_params = {'learning_rate' : 0.05, 'iterations': 700, 'verbose': 300}
# param_grid = {#'iterations': range(600,2000,100)}
# 'learning_rate': [0.05,0.1,0.15,0.2,0.25,0.3,0.35,0.4,0.45,0.5,0.55,0.6,0.65,0.7,0.75,0.8,0.85,0.9,0.95,1 ]}
# m = GridSearchCV(CatBoostClassifier(),param_grid)
# m.fit(X_train,y)
# print("该参数下得到的最佳得分为:{}".format(m.best_score_))
# print("最佳参数为:{}".format(m.best_params_))
5.3.2 CatBoostClassifier新模型
# cbt_then 线上有效得分:
def cbt_then():
model = CatBoostClassifier(**cbt_then_params)
model.fit(X_train,y)
pred = model.predict_proba(X_test)
MAE = 1/(1 + np.sum(np.absolute(np.eye(4)[y] - pred))/480)
gdbt_then_score = 1/(1+10*MAE)
print('log_loss',log_loss(pd.get_dummies(y).values, pred))
print('cbt_then_ac',accuracy_score(y,np.argmax(pred,axis = 1)))
print('MAE',1/(1 + np.sum(np.absolute(np.eye(4)[y] - pred))/480))
print('cbt_then_score',1/(1+10*MAE))
print('--------------------------------')
return model
5.4 结果显示
if __name__ == '__main__':
svc(X_train, y, X_test)
svc_then()
gdbt()
gdbt_then()
cbt()
cbt_then()
model_mix()

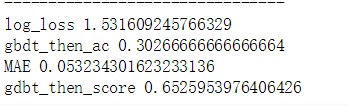

通过三组数据,可以发现,在调参之后的,线下:SVC的Score> GradientBoostingClassifier 的Score>CatBoostClassifier的Score。
至此,综合考虑,本次实验SVC作为主要模型进行实验。
而对于模型融合,已经试过,如下图所示。通过图可以发现选择SVC作为单独模型的优势。所以,本次模型融合不予考虑。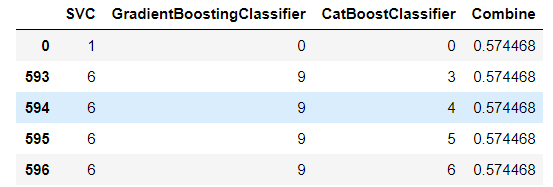
6、输出结果
6.1保存predict
# 得出每个模型的predict
svc = SVC(probability=True)
svc.fit(X_train,y)
svc_pred = svc.predict_proba(X_test)
svc_then = SVC(probability=True)
svc.fit(X_train,y)
svc_then_pred = svc.predict_proba(X_test)
gdbt = GradientBoostingClassifier()
gdbt.fit(X_train,y)
gdbt_pred = gdbt.predict_proba(X_test)
gdbt_then = GradientBoostingClassifier()
gdbt_then.fit(X_train,y)
gdbt_then_pred = gdbt.predict_proba(X_test)
cbt = CatBoostClassifier()
cbt.fit(X_train,y)
cbt_pred = cbt.predict_proba(X_test)
cbt_then = CatBoostClassifier()
cbt_then.fit(X_train,y)
cbt_then_pred = cbt.predict_proba(X_test)
6.2 输出结果
结果输出:
sub = test_data[['Group']]
prob_cols = [i for i in submit.columns if i not in ['Group']]
print(prob_cols)
for i, f in enumerate(prob_cols):
# sub[f] = svc_pred[:, i]
sub[f] = svc_then_pred[:, i]
for i in prob_cols:
sub[i] = sub.groupby('Group')[i].transform('mean')
sub = sub.drop_duplicates()
# sub.to_csv("C:/Users/93601/Desktop/svc_submission_mean.csv",index=False)
sub.to_csv("C:/Users/93601/Desktop/svc_then_submission_mean.csv",index=False)
# sub.to_csv("C:/Users/93601/Desktop/gdbt_submission_mean.csv",index=False)
# sub.to_csv("C:/Users/93601/Desktop/gdbt_then_submission_mean.csv",index=False)
# sub.to_csv("C:/Users/93601/Desktop/cbt_submission_mean.csv",index=False)
# sub.to_csv("C:/Users/93601/Desktop/cbt_then_submission_mean.csv",index=False)















 1354
1354











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









