







目录
前言
专用隐写分析方法是针对特定算法而设计的,所以通用性很弱;相反地,通用隐写分析比专用隐写分析具有更强的普适性,可以检测出多种隐写方法。传统的通用隐写分析模型又被称之为盲隐写分析模型,主要包含隐写特征设计和分类器的选取,其中分类器包含信息分类器和集成分类器。
随着机器学习的发展,进而出现了基于深度学习(Deep Learning)的隐写分析,此种方法就不需要预先设计特征,可以直接利用神经网络自动完成特征学习。部分分析特征可以同时应用于多种嵌入域,但其适用范围和检测准确性可能有很大不同。
备注:此处的机器学习与深度学习的应用是不同的。
一. 马尔科夫特征集
马尔科夫(Markov)特征集是最简单也是最有效的隐写分析特征之一。假定隐写嵌入域是一种服从马尔科夫链的随机过程,基于隐写操作就会改变马尔科夫链的状态转移概率矩阵。马尔科夫特征集计算简单,并且对于某些隐写算法在低嵌入率下也具有较好的检测效果。但是,由于变量的状态数和样本分量数量都很大,因此马尔科夫特征的维度都很高。
在实际的应用中,通常需要对某些状态值、特征分量来进行筛选和优化来降维,去除某些对检测影响很小的分量和训练中过拟合的分量,从而满足实际计算代价和检测率的要求。马尔科夫特征集在音频隐写分析中的应用形式非常多,包含时域和压缩域等等。
以下,以MP3音频为例来说明马尔科夫特征的计算过程步骤。
1.1 提取QMDCT系数矩阵
提取待测MP3音频的QMDCT系数矩阵为如下:
上式子中,的每个行向量表示MP3帧中的一个颗粒,由此M就代表音频文件的总颗粒数,它可以控制单次检测的粒度,M值越小检测粒度越细。根据MP3的编码标准,N的值大多为576,当然根据实际应用,M和N的值可以灵活选取。从每个颗粒中QMDCT系数的分布来讲(也就是每一行),大约位于后
的QMDCT系数都属于零值区,对特征的计算没有实质作用,由此就可以减小N的取值(大约300~400取值最佳)。
1.2 计算差分矩阵
计算的差分矩阵
和绝对值差分矩阵
如下:

上式子中,,
此步骤集中于行差分,实际上也可以修改为列差分计算。
1.3 计算转移概率
根据马尔科夫链的状态转移原理,可以分别计算的一阶转移概率。
行方向的帧间转移概率如下:

列方向上的帧内转移概率如下:

上式子中T代表状态量阈值,且,此式子中
。最常用的T值为15。
1.4 特征优化
为了降低特征向量维度,可以通过调节阈值T,同时对以上式子特征进行优化选择。
特征优化条件如下:
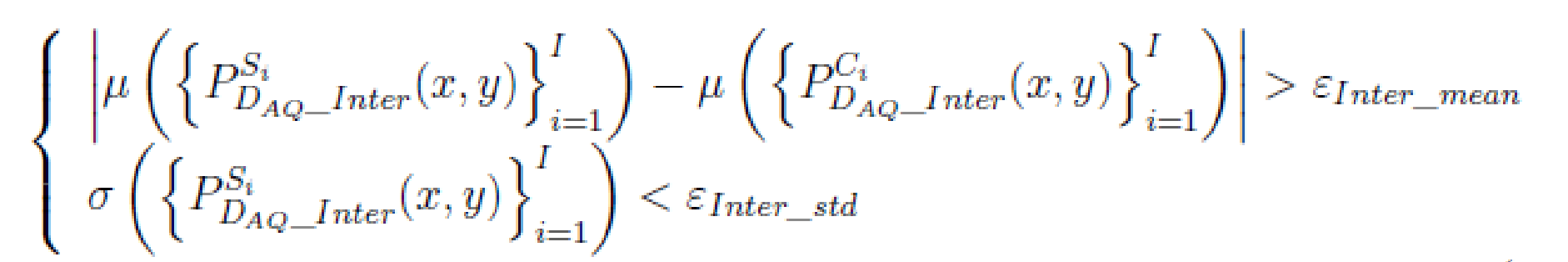
特征优化条件如下:
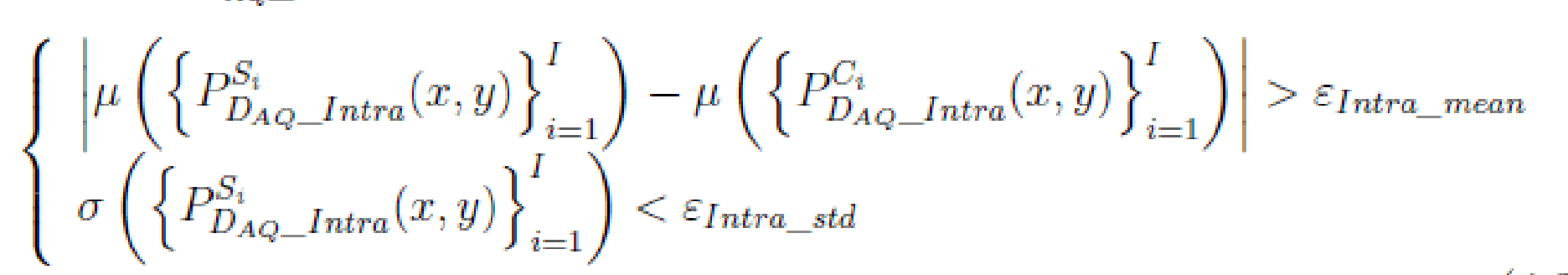
上式子中,和
分别代表均值函数和标准差函数;
和
分别表示第i个隐写音频样本和载体音频样本;I是样本对总数;
是对应的阈值;
。
综上1.1~1.4,马尔科夫特征的维度与T值选取和特征优选有关系,如果不考虑特征优选,则特征维度计算为维。x,y的计算分别有三种,总共6种;对单个x或y,其取值从-T到T,一共2T+1个值,由此可计算特征维度为
。
二. 深度学习的应用
2.1 概述
深度学习(Deep Learning,DP)在近些年受到了世界各国研究人员的热捧,成为了一个很有潜力的研究方向。深度学习已被广泛应用于图像分类,语音识别,目标跟踪以及语义分割等众多领域。其中最具有代表性的深度学习网络包括LeNet,AlexNet,VGG,GoogLeNet,ResNet和DenseNet。列举相关的书籍如下:

人工智能,机器学习,神经网络,深度学习,四者之间的关系可见如下图:
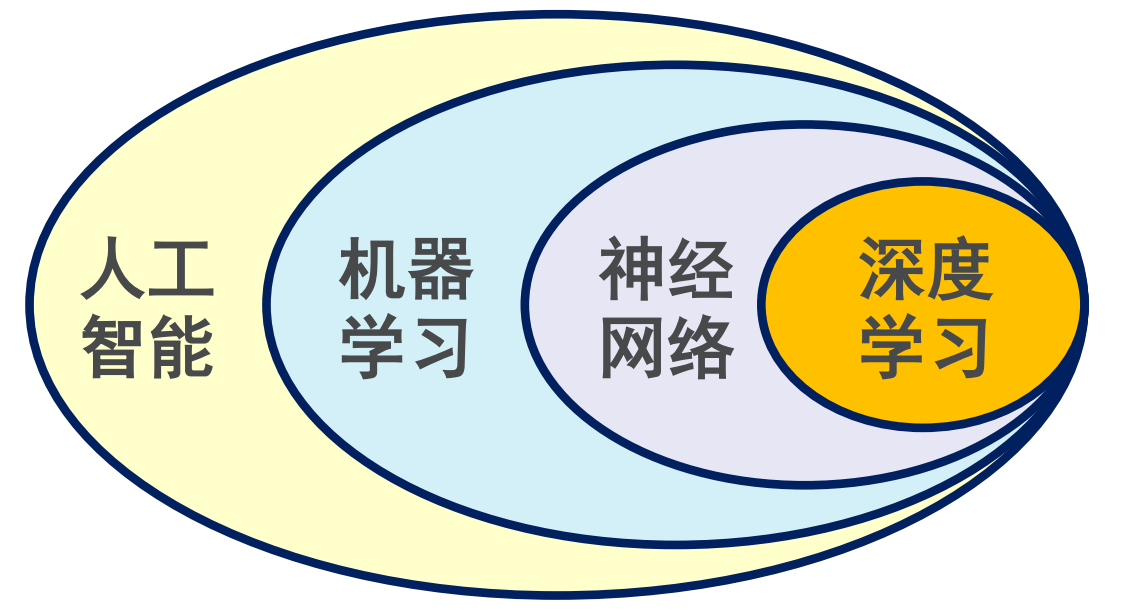
隐写分析的本质任务是分类任务,它的目标就是寻找最优的隐写统计特征表达式,从而更好地区分正常载体和隐写载体。所以,深度学习技术也是可以应用于隐写分析的。
2.2 两种隐写分析框架
基于卷积神经网络和基于手工特征设计的隐写分析方法,两种框架的基本部件是相似的,其中最本质的区别就在于隐写特征的表达。基于卷积神经网络的隐写分析方法可实现对特征空间的自动寻优;基于手工特征设计的隐写分析方法则需要较强的专业知识和设计经验。这两类隐写分析框架的比较,可见如下:
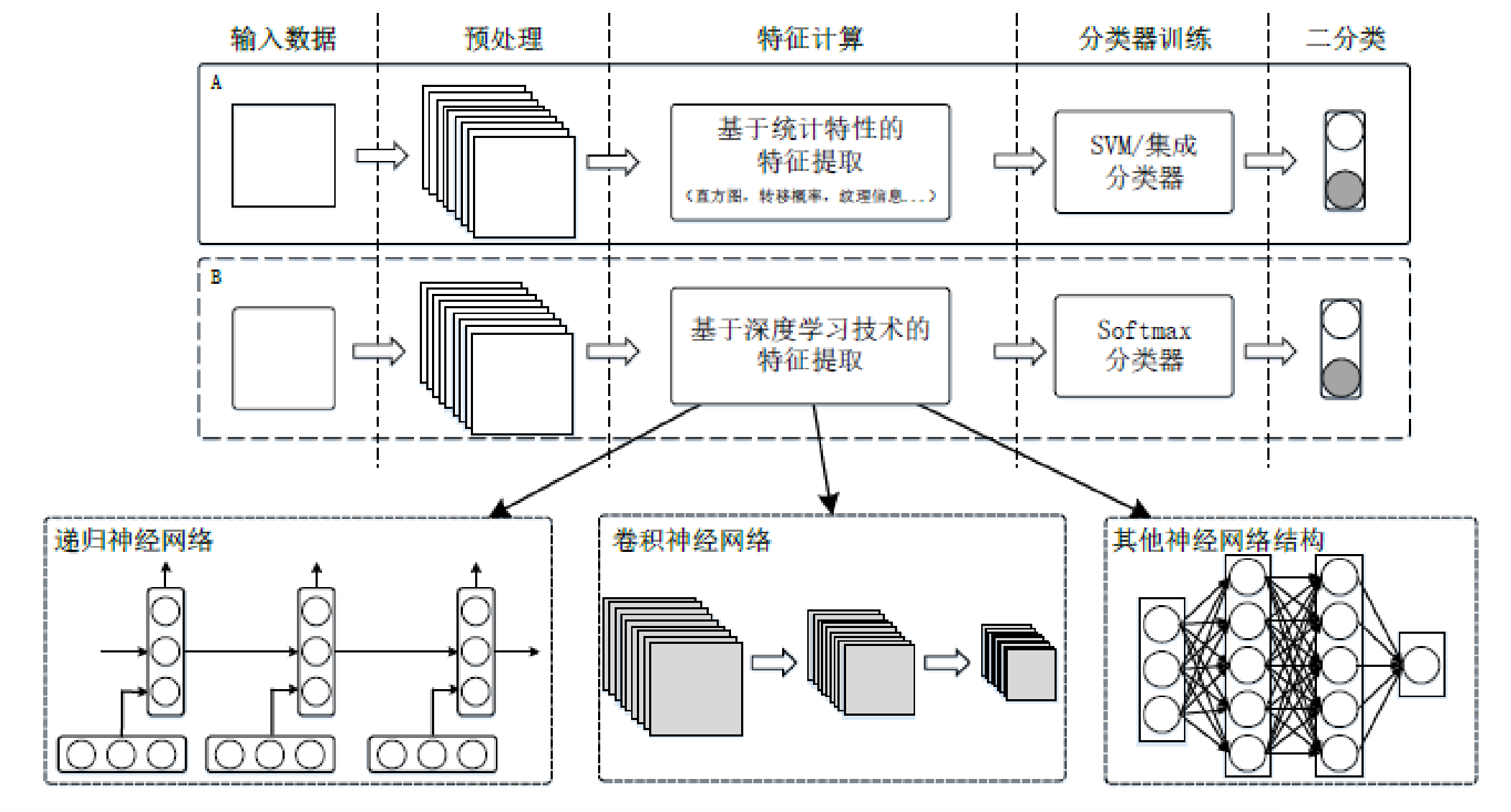
随着自适应隐写术等现代隐写技术的发展,基于手工特征设计的隐写分析方法变得愈发困难。实际上,深度学习技术已经在隐写分析中得到了很好的运用,检测效果已经超过了基于手工特征设计的传统隐写分析方法。
基于深度学习的音频隐写分析就是将如何计算隐写分析特征问题,转化为深度学习网络结构的设计问题。设计一个好的深度学习网络模型用于隐写分析检测,其实就是一个基于大样本驱动的迭代过程,然后利用反馈结果不断改进网络模型。遗憾的是,当前深度学习模型的构建仍然缺乏完备的理论体系,整个网络构成也依赖于具体的分析对象。
2.3 网络模型基础部件
(1)批量标准化层。由Google公司提出的一种训练优化方法,目的是缓解输入数据的协方差偏移现象,从而降低梯度弥散的风险。如果批次训练样本的分布特性不同,那么神经网络还需要在迭代时重新学习不同的分布,这个过程将影响网络的训练效率。所以我们需要提出多种训练数据的标准化方法。
(2)激活函数。 可以引入非线性因素,提升网络对各类函数的表达能力。
(3)池化层。对特征图进行降采样,一方面可以减少特征图的维度,降低运算复杂度;另一方面可以对特征进行压缩,保留其鲁棒性。常用的池化类型包含:均值池化,最大池化,随机池化和卷积池化。
(4)正则化。在机器学习中,通过显示控制模型复杂度来避免模型过拟合,确保其泛化能力。正则化在损失函数中引入模型复杂度指标,强化训练数据中的噪声。
系列文章
音频隐写术:结合“熵”理解隐写算法的具体步骤_唠嗑!的博客-CSDN博客
















 1553
1553











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











