







一、图像数据类型及转换
在skimage中,一张图片就是一个简单的numpy数组,数组的数据类型有很多种,相互之间也可以转换。这些数据类型及取值范围如下表所示:
| Data type | Range |
|---|---|
| uint8 | 0 to 255 |
| uint16 | 0 to 65535 |
| uint32 | 0 to 232 |
| float | -1 to 1 or 0 to 1 |
| int8 | -128 to 127 |
| int16 | -32768 to 32767 |
| int32 | -231 to 231 - 1 |
一张图片的像素值范围是[0,255], 因此默认类型是unit8, 可用如下代码查看数据类型:
from skimage import io,data img=data.chelsea() print(img.dtype.name)
在上面的表中,特别注意的是float类型,它的范围是[-1,1]或[0,1]之间。一张彩色图片转换为灰度图后,它的类型就由unit8变成了float
1、unit8转float
from skimage import data,img_as_float img=data.chelsea() print(img.dtype.name) dst=img_as_float(img) print(dst.dtype.name)
输出:
uint8
float64
2、float转uint8
from skimage import img_as_ubyte import numpy as np img = np.array([0, 0.5, 1], dtype=float) print(img.dtype.name) dst=img_as_ubyte(img) print(dst.dtype.name)
输出:
float64
uint8
float转为unit8,有可能会造成数据的损失,因此会有警告提醒。
除了这两种最常用的转换以外,其实有一些其它的类型转换,如下表:
| Function name | Description |
|---|---|
| img_as_float | Convert to 64-bit floating point. |
| img_as_ubyte | Convert to 8-bit uint. |
| img_as_uint | Convert to 16-bit uint. |
| img_as_int | Convert to 16-bit int. |
二、颜色空间及其转换
如前所述,除了直接转换可以改变数据类型外,还可以通过图像的颜色空间转换来改变数据类型。
常用的颜色空间有灰度空间、rgb空间、hsv空间和cmyk空间。颜色空间转换以后,图片类型都变成了float型。
所有的颜色空间转换函数,都放在skimage的color模块内。
例:rgb转灰度图
from skimage import io,data,color img=data.lena() gray=color.rgb2gray(img) io.imshow(gray)
其它的转换,用法都是一样的,列举常用的如下:
skimage.color.rgb2grey(rgb)
skimage.color.rgb2hsv(rgb)
skimage.color.rgb2lab(rgb)
skimage.color.gray2rgb(image)
skimage.color.hsv2rgb(hsv)
skimage.color.lab2rgb(lab)
实际上,上面的所有转换函数,都可以用一个函数来代替
skimage.color.convert_colorspace(arr, fromspace, tospace)
表示将arr从fromspace颜色空间转换到tospace颜色空间。
例:rgb转hsv
from skimage import io,data,color img=data.lena() hsv=color.convert_colorspace(img,'RGB','HSV') io.imshow(hsv)
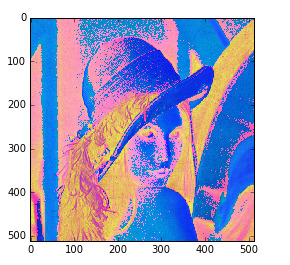
在color模块的颜色空间转换函数中,还有一个比较有用的函数是
skimage.color.label2rgb(arr), 可以根据标签值对图片进行着色。以后的图片分类后着色就可以用这个函数。
例:将lena图片分成三类,然后用默认颜色对三类进行着色

from skimage import io,data,color
import numpy as np
img=data.lena()
gray=color.rgb2gray(img)
rows,cols=gray.shape
labels=np.zeros([rows,cols])
for i in range(rows):
for j in range(cols):
if(gray[i,j]<0.4):
labels[i,j]=0
elif(gray[i,j]<0.75):
labels[i,j]=1
else:
labels[i,j]=2
dst=color.label2rgb(labels)
io.imshow(dst)















 3576
3576











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









