







 本文详细介绍了OpenCV中的图像颜色空间转换,包括RGB到灰度、YUV、HSV和Lab的转换。接着讨论了图像像素操作,如像素统计、图像按位操作和二值化,以及LUT的应用。此外,还涵盖了图像连接、尺寸变换、翻转、仿射变换和透视变换等图像变换方法。最后,提到了绘制图形和文字、感兴趣区域选择以及窗口交互操作等内容。
本文详细介绍了OpenCV中的图像颜色空间转换,包括RGB到灰度、YUV、HSV和Lab的转换。接着讨论了图像像素操作,如像素统计、图像按位操作和二值化,以及LUT的应用。此外,还涵盖了图像连接、尺寸变换、翻转、仿射变换和透视变换等图像变换方法。最后,提到了绘制图形和文字、感兴趣区域选择以及窗口交互操作等内容。
一、颜色空间
1、颜色空间
图像空间包括:
RGB:由R(红)G(绿)B(蓝)三个通道组成的颜色空间,每个通道的分量为0~255。三个通道的数据类型均为uint8,在三个通道的基础上再加一个透明度分量就形成了RGBA颜色空间。
例子:
黑色(0,0,0) 白色(255,255,255) 红色(255,0,0)
YUV:由亮度(Y)、红色分量与亮度差(U)、蓝色分量与亮度差(V)三个分量组成,主要用于电视信号的传输。
HSV:由色调(H)、饱和度(S)和亮度(V)组成,HSV是最为接近人体感知颜色的方式。
Lab:由亮度(L)、ab两个颜色通道组成,是一种与设备无关,基于生理特征的颜色空间。
GRAY:灰度颜色空间,只有一个通道,每个灰度值由0~255的整数表示。
RGB转GRAY = GRAY = 0.3R+0.59R+0.11B
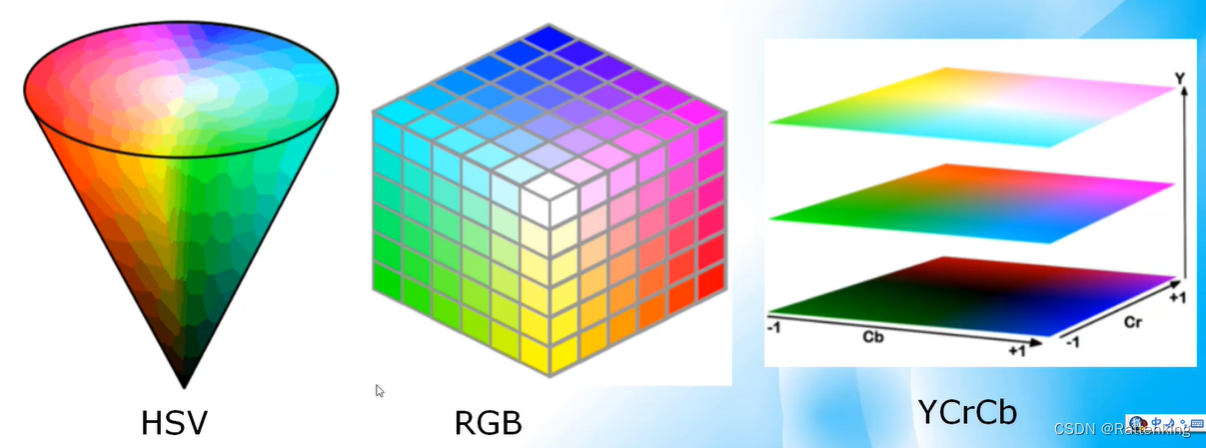
2、不同的颜色空间转换 cv.cvtColor
cv.cvtColor()函数用于将图像从一个颜色空间转换为另一个颜色空间,并将转化之后的结果通过值返回。
#函数原型:
dst = cv.cvtColor(src,
code
[, dst
[, dstCn]])
# src:待转化颜色空间的图像
# code:颜色空间转化的标志
# dst:颜色空间转化后的目标图像
# dstCn:目标图像中的通道数,默认值为0
cv.COLOR_BGR2BGRA 0 为RGB添加alpha通道
cv.COLOR_BGR2RGB 4 更改彩色图像通道颜色的顺序
cv.COLOR_BGR2GRAY 10 把彩色图像转成灰度图像
cv.COLOR_GRAY2BGR 8 把灰度图像转成彩色图像(伪彩色)
cv.COLOR_BGR2YUV 82 从RGB颜色空间转成YUV颜色空间
cv.COLOR_YUV2BGR 84 从YUV颜色空间转成RGB颜色空间
cv.COLOR_BGR2HSV 40 从RGB颜色空间转成HSV颜色空间
cv.COLOR_HSV2BGR 54 从HSV颜色空间转成RGB颜色空间
cv.COLOR_BGR2Lab 44 从RGB颜色空间转成Lab颜色空间
cv.COLOR_Lab2BGR 56 从Lab颜色空间转成RGB颜色空间
代码:
if __name__ == "__main__":
image = cv2.imread('beach.png')
if image is None:
print('faile to read image')
sys.exit()
#将图像转化空间
#将图像转换为float32
HSV = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
image1 = image.astype('float32')
image1 *= 1.0/255
YUV = cv2.cvtColor(image1,cv2.COLOR_BGR2YUV)
Lab = cv2.cvtColor(image1,cv2.COLOR_BGR2Lab)
GRAY = cv2.cvtColor(image1,cv2.COLOR_BGR2GRAY)
#结果展示
cv2.imshow('HSV',HSV)
cv2.imshow("YUV",YUV)
cv2.imshow('Lab',Lab)
cv2.imshow('GRAY',GRAY)
cv2.imwrite('lab.jpg',Lab)
cv2.imread('lab.jpg')
cv2.imshow('lab',Lab)
cv2.waitKey()
cv2.destroyAllWindows()3、类型转换
dst = ndarray.astype(dtype
[,order = 'K']
[,cast = 'unsafe']
[,subok = True]
[,copy = True] )
#dtype:转化后的图像数据类型
#order:在内存中的存储顺序,默认K
#cast:数据类型转化的级别,默认值为‘unsafe’
#subok:声明是否传递子类。
#copy:声明是否返回新分配的数组参数:
- dtype:接受字符串或者numpy类型。
- order:可选{‘C’, ‘F’, ‘A’, ‘K’}控制结果的内存布局顺序。
- casting:可选{‘no’, ‘equiv’, ‘safe’, ‘same_kind’, ‘unsafe’},控制可能发生的数据类型转换。
‘no’ 表示根本不应该转换数据类型。
‘equiv’ 表示只允许字节顺序更改。
‘safe’ 意味着只允许可以保留值的强制转换。
‘same_kind’ 表示只允许安全类型转换或类型中的类型转换,如 float64 到 float32。
‘unsafe’ 意味着可以进行任何数据转换。
subok:接收bool值,如果为 True(默认),子类将被传递,否则返回的数组将被强制为基类数组。
- copy:接受bool值,是否赋值数据,默认为True。
返回值:
- ndarray
代码:
HSV = cv2.cvtColor(image, cv2.COLOR_BGR2HSV)
#将图像转化为float32类型
image1 = image.astype('float32')
#将数据归化为0~1的值
image1 *= 1.0/255需要注意该函数在进行转换前后的图像取值范围不能超出像素取值范围。
uint8: 0~255
uint16: 0~65535
float32: 0~1
4、通道的分离与合并
1、图像通道分离split
在图像颜色空间中,不同的分量存放在不同的通道中。如果我们只需要颜色空间中的某一个分量(例如,只需要处理 RGB 图像中的红色通道),则可以将红色通道从三通道的数据中分离出来再进行处理。这种方式可以减少数据所占用的内存,加快程序的运行速度。同时,当我们分别处理完多个通道后需要将所有通道合并在一起重新生成RGB图像。这就需要用到cv.split()函数和cv.merge()函数。
mv = cv.split(m,
[,mv])
#m:待分离的图像
#mv:分离后的单通道图像2、通道合并merge
该函数主要用于将多幅图像合并成一幅多通道图像,并将合并后的结果通过值返回。其功能与cv.split()相对应,对于输入尺寸和数据类型一致的多幅图像,输出结果是一幅多通道的图像,其通道数目是所有输入图像通道数目的总和。
注意:所有输入的图像的通道数可以不相同,但是所有图像需要具有相同的尺寸和数据类型
dst = cv.merge(mv
[,dst])
#mv:需要合并的图像
#dst:合并后输出的图像
代码:
import cv2
import numpy as np
import sys
import matplotlib.pyplot as plt
if __name__ =='__main__':
#读取图像
image = cv2.imread('beach.png')
if image is None:
print('failed to read image')
sys.exit()
#分离图像通道
(b,g,r) = cv2.split(image)
zeros = np.zeros(image.shape[:2],dtype='uint8')
#将通道数相同的图像合并
bg = cv2.merge([b,g,zeros])
gr = cv2.merge([zeros,g,r])
br = cv2.merge([b,zeros,r])
#将通道数目不同的图像矩阵进行合并
bgr_6 = cv2.merge([bg,r,zeros,zeros])
#展示结果
cv2.imshow('Blue',b)
cv2.imshow('Green',g)
cv2.imshow('Red',r)
cv2.imshow('Blue_Green',bg)
cv2.imshow('Green_Red',gr)
cv2.imshow('Blue_Red',br)
#cv2.imshow('BGR-6',bgr_6)
cv2.waitKey()
cv2.destroyAllWindows()二、图像像素操作
1、像素统计
(1) OpenCV 4中提供了寻找图像像素最大值、最小值的函数 cv.minMaxLoc()
#cv.minMaxLoc()函数原型
minVal, maxVal, minLoc, maxLoc = cv.minMaxLoc(src
[, mask])
#minVal:像素最小值
#maxVal:像素最大值
#minLoc:最小值坐标
#maxLoc:最大值坐标
#src:图像代码1:
import cv2
import numpy as np
import sys
if __name__== '__main__':
array = np.array([1,2,3,4,5,10,6,7,8,9,10,0])
image = cv2.imread('beach.png')
gray = cv2.cvtColor(image,cv2.COLOR_RGB2GRAY)
#将array调整为3*4的单通道图像
img1 = array.reshape((3,4))
minVal,maxVal,minLoc,maxLoc = cv2.minMaxLoc(gray)
print('图像img1的最小值为%s,其位置为%s'%(minVal,minLoc))
print('图像img1的最大值为%s,其位置为%s'%(maxVal,maxLoc))
#将array重塑为3*2*2的多通道图像
img2 = array.reshape((3,2,2))
print(img2)
#将通道图像重塑
img2_re = img2.reshape((1,-1))
minVal1,maxVal1,minLoc1,maxLoc1 = cv2.minMaxLoc(img2_re)
print('图像img2的最小值%s,其位置是%s'%(minVal1,minLoc1))
print('图像img2的最大值%s,其位置是%s' % (maxVal1, maxLoc1))
cv2.waitKey()代码2:
def MinMaxLoc(self,rec_img):
'''
获取最大最小値
:param rec_img: 图像
:return:处理后的图像
'''
try:
img = rec_img.reshape((1,-1))
min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(img)
cv2.putText(rec_img,'minVal{}'.format(min_val,3),(0,30),cv2.FONT_HERSHEY_SIMPLEX,0.5,(0,255,0),1)
cv2.putText(rec_img,'maxVal{}'.format(max_val,3),(0,60),cv2.FONT_HERSHEY_SIMPLEX,0.5,(0,255,0),1)
cv2.putText(rec_img,'minVallLoc{}'.format(min_loc,3),(0,90),cv2.FONT_HERSHEY_SIMPLEX,0.5,(0,255,0),1)
cv2.putText(rec_img,'maxValLoc{}'.format(max_loc,3),(0,120),cv2.FONT_HERSHEY_SIMPLEX,0.5,(0,255,0),1)
return False,rec_img
except Exception as e:
QMessageBox.warning(None, "错误", "{}".format(str(e)))
return(2)cv.mean()函数可计算图像的均值。
#cv.mean()函数原型
retal = cv.mean(src
[,mask])
其中各返回值和参数的含义分别为:
retal:为一个长度为4的元组,四个位置分别代表相应通道的均值,若通道不存在,则对应值为0.0
src:需要计算均值的图像或者矩阵
mask:图像掩模(可选参数)
(3)cv.meanStdDev()函数可同时计算图像的均值和标准差。
#cv.meanStdDev()函数原型
mean, stddev = cv.meanStdDev(src
[, mean
[, stddev
[, mask]]])
其中各返回值参数的含义分别为:
mean:图像每个通道的均值
stddev:图像每个通道的标准差
src:需要计算均值的图像或者矩阵
mask:图像掩模(可选参数)
代码1:
import cv2
import numpy as np
import sys
if __name__ == '__main__':
#新建array
array = np.array([1,2,3,4,5,10,6,7,8,9,10,0])
#转换为3*4单通道
img1 = array.reshape((3,4))
#转换为3*2*2多通道
img2 = array.reshape((3,2,2))
img = cv2.imread('beach.png')
#分别计算图像img1和img2的均值与标准差
mean_img1 = cv2.mean(img)
mean_img2 = cv2.mean(img2)
stDev1 = cv2.meanStdDev(img)
stDev2 = cv2.meanStdDev(img2)
print(stDev2)
print('cv.mean的计算结果:')
print('img1的平均值为{}'.format(mean_img1))
print('img2的平均值为{},其中1通道为{},2通道为{}'.format(mean_img2,mean_img2[0],mean_img2[1]))
print('cv.meanStdDev的计算结果:')
print('img1的平均值为{},标准差为{}'.format(float(stDev1[0][0]),float(stDev1[0][1])))
print('img2的平均值为{},其中1通道为{},\n2通道为{} 标准差为{},\n其中通道1为{},通道2为{}'.format(stDev2,stDev2[0][0],stDev2[0][1],stDev2[1],stDev2[1][0],stDev2[1][1]))
cv2.waitKey()代码2:
def Mean(self,rec_img):
'''
图像平均值
:param rec_img: 图像
:return: 处理后的图像
'''
try:
mean = cv2.mean(rec_img)
mean1 = mean[0]
mean2 = mean[1]
mean3 = mean[2]
cv2.putText(rec_img,'Channel1Mean{}'.format(round(mean1,3)),(0,30),cv2.FONT_HERSHEY_SIMPLEX,0.5,(0,255,0),1)
cv2.putText(rec_img,'Channel2Mean{}'.format(round(mean2,3)),(0,60),cv2.FONT_HERSHEY_SIMPLEX,0.5,(0,255,0),1)
cv2.putText(rec_img,'Channel3Mean{}'.format(round(mean3,3)),(0,90),cv2.FONT_HERSHEY_SIMPLEX,0.5,(0,255,0),1)
return False, rec_img
except Exception as e:
QMessageBox.warning(None, "错误", "{}".format(str(e)))
return
def MeanstdDev(self,rec_img):
'''
图像均值标准差
:param rec_img: 图像
:return: 处理后的图像
'''
try:
mean, stddev = cv2.meanStdDev(rec_img)
mean1 = mean[0]
mean2 = mean[1]
mean3 = mean[2]
stddev1 = stddev[0]
stddev2 = stddev[1]
stddev3 = stddev[2]
cv2.putText(rec_img,'Channel1Mean{}'.format(round(float(mean1),3)),(0,30),cv2.FONT_HERSHEY_SIMPLEX,0.5,(0,255,0),1)
cv2.putText(rec_img,'Channel2Mean{}'.format(round(float(mean2),3)),(0,60),cv2.FONT_HERSHEY_SIMPLEX,0.5,(0,255,0),1)
cv2.putText(rec_img,'Channel3Mean{}'.format(round(float(mean3),3)),(0,90),cv2.FONT_HERSHEY_SIMPLEX,0.5,(0,255,0),1)
cv2.putText(rec_img,'Channel1StdDev{}'.format(stddev1),(0,120),cv2.FONT_HERSHEY_SIMPLEX,0.5,(0,255,0),1)
cv2.putText(rec_img,'Channel2StdDev{}'.format(stddev2),(0,150),cv2.FONT_HERSHEY_SIMPLEX,0.5,(0 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5728
5728











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









