







 本文详细介绍了Lucene的索引文件格式,包括段的元数据(segments_N)、域的元数据(.fnm)、域数据(.fdt、.fdx)以及词向量数据(.tvx、.tvd、.tvf)。内容涉及段的选取、段的元数据信息、域的索引方式、存储方式以及词向量信息的存储结构。
本文详细介绍了Lucene的索引文件格式,包括段的元数据(segments_N)、域的元数据(.fnm)、域数据(.fdt、.fdx)以及词向量数据(.tvx、.tvd、.tvf)。内容涉及段的选取、段的元数据信息、域的索引方式、存储方式以及词向量信息的存储结构。
四、具体格式
上面曾经交代过,Lucene保存了从Index到Segment到Document到Field一直到Term的正向信息,也包括了从Term到Document映射的反向信息,还有其他一些Lucene特有的信息。下面对这三种信息一一介绍。
4.1. 正向信息
Index –> Segments (segments.gen, segments_N) –> Field(fnm, fdx, fdt) –> Term (tvx, tvd, tvf)
上面的层次结构不是十分的准确,因为segments.gen和segments_N保存的是段(segment)的元数据信息(metadata),其实是每个Index一个的,而段的真正的数据信息,是保存在域(Field)和词(Term)中的。
4.1.1. 段的元数据信息(segments_N)
一个索引(Index)可以同时存在多个segments_N(至于如何存在多个segments_N,在描述完详细信息之后会举例说明),然而当我们要打开一个索引的时候,我们必须要选择一个来打开,那如何选择哪个segments_N呢?
Lucene采取以下过程:
- 其一,在所有的segments_N中选择N最大的一个。基本逻辑参照SegmentInfos.getCurrentSegmentGeneration(File[] files),其基本思路就是在所有以segments开头,并且不是segments.gen的文件中,选择N最大的一个作为genA。
- 其二,打开segments.gen,其中保存了当前的N值。其格式如下,读出版本号(Version),然后再读出两个N,如果两者相等,则作为genB。
![[图]segments.gen格式](http://hi.csdn.net/attachment/201002/2/3634917_1265115802y5M4.jpg)
IndexInput genInput = directory.openInput(IndexFileNames.SEGMENTS_GEN);//"segments.gen"
int version = genInput.readInt();//读出版本号
if (version == FORMAT_LOCKLESS) {//如果版本号正确
long gen0 = genInput.readLong();//读出第一个N
long gen1 = genInput.readLong();//读出第二个N
if (gen0 == gen1) {//如果两者相等则为genB
genB = gen0;
}
}- 其三,在上述得到的genA和genB中选择最大的那个作为当前的N,方才打开segments_N文件。其基本逻辑如下:
if (genA > genB)
gen = genA;
else
gen = genB;
如下图是segments_N的具体格式:
![[图]segments_N格式](http://hi.csdn.net/attachment/201002/2/3634917_1265115802MM0M.jpg)
- Format:
- 索引文件格式的版本号。
- 由于Lucene是在不断开发过程中的,因而不同版本的Lucene,其索引文件格式也不尽相同,于是规定一个版本号。
- Lucene 2.1此值-3,Lucene 2.9时,此值为-9。
- 当用某个版本号的IndexReader读取另一个版本号生成的索引的时候,会因为此值不同而报错。
- Version:
- 索引的版本号,记录了IndexWriter将修改提交到索引文件中的次数。
- 其初始值大多数情况下从索引文件里面读出,仅仅在索引开始创建的时候,被赋予当前的时间,已取得一个唯一值。
- 其值改变在IndexWriter.commit->IndexWriter.startCommit->SegmentInfos.prepareCommit->SegmentInfos.write->writeLong(++version)
- 其初始值之所最初取一个时间,是因为我们并不关心IndexWriter将修改提交到索引的具体次数,而更关心到底哪个是最新的。IndexReader中常比较自己的version和索引文件中的version是否相同来判断此IndexReader被打开后,还有没有被IndexWriter更新。
| //在DirectoryReader中有一下函数。 public boolean isCurrent() throws CorruptIndexException, IOException { |
- NameCount
- 是下一个新段(Segment)的段名。
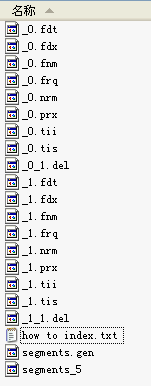
- 所有属于同一个段的索引文件都以段名作为文件名,一般为_0.xxx, _0.yyy, _1.xxx, _1.yyy ……
- 新生成的段的段名一般为原有最大段名加一。
- 如同的索引,NameCount读出来是2,说明新的段为_2.xxx, _2.yyy
![[图]同段文件名相同后缀不同](http://hi.csdn.net/attachment/201002/2/3634917_126511580020BS.png)
- SegCount
- 段(Segment)的个数。
- 如上图,此值为2。
- SegCount个段的元数据信息:
- SegName
- 段名,所有属于同一个段的文件都有以段名作为文件名。
- 如上图,第一个段的段名为"_0",第二个段的段名为"_1"
- SegSize
- 此段中包含的文档数
- 然而此文档数是包括已经删除,又没有optimize的文档的,因为在optimize之前,Lucene的段中包含了所有被索引过的文档,而被删除的文档是保存在.del文件中的,在搜索的过程中,是先从段中读到了被删除的文档,然后再用.del中的标志,将这篇文档过滤掉。
- 如下的代码形成了上图的索引,可以看出索引了两篇文档形成了_0段,然后又删除了其中一篇,形成了_0_1.del,又索引了两篇文档形成_1段,然后又删除了其中一篇,形成_1_1.del。因而在两个段中,此值都是2。
- SegName
| IndexWriter writer = new IndexWriter(FSDirectory.open(INDEX_DIR), new StandardAnalyzer(Version.LUCENE_CURRENT), true, IndexWriter.MaxFieldLength.LIMITED); //文档一为:Students should be allowed to go out with their friends, but not allowed to drink beer. //文档二为:My friend Jerry went to school to see his students but found them drunk which is not allowed. writer.commit();//提交两篇文档,形成_0段。 writer.deleteDocuments(new Term("contents", "school"));//删除文档二 |
-
- DelGen
- .del文件的版本号
- Lucene中,在optimize之前,删除的文档是保存在.del文件中的。
- 在Lucene 2.9中,文档删除有以下几种方式:
- IndexReader.deleteDocument(int docID)是用IndexReader按文档号删除。
- IndexReader.deleteDocuments(Term term)是用IndexReader删除包含此词(Term)的文档。
- IndexWriter.deleteDocuments(Term term)是用IndexWriter删除包含此词(Term)的文档。
- IndexWriter.deleteDocuments(Term[] terms)是用IndexWriter删除包含这些词(Ter
- DelGen
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1083
1083

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}