







 本文介绍了自动机器学习(AutoML)的概念,探讨了其在数据预处理和模型优化中的作用,着重分析了特征工程和超参优化工具的自动实现,如Tsfresh、Trane等,并对比了多种常见工具的优缺点。
本文介绍了自动机器学习(AutoML)的概念,探讨了其在数据预处理和模型优化中的作用,着重分析了特征工程和超参优化工具的自动实现,如Tsfresh、Trane等,并对比了多种常见工具的优缺点。
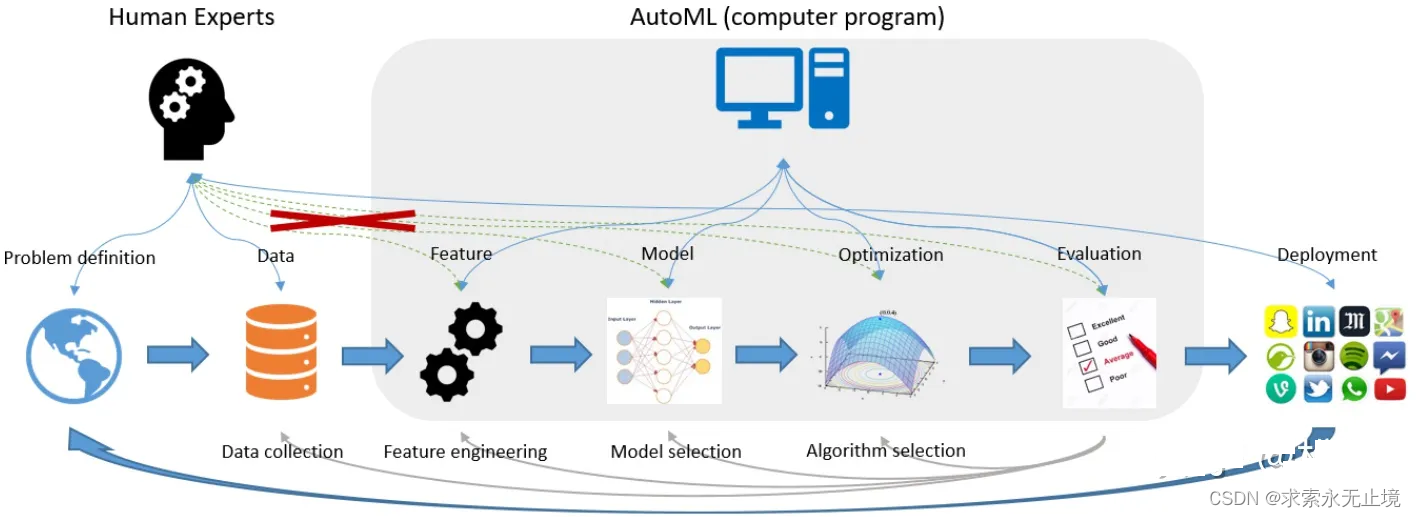
自动机器学习(AutoML)是将机器学习应用于现实问题的端到端流程自动化的过程。
传统机器学习模型大致可分为以下四个部分:数据采集、数据预处理、优化、应用
其中数据预处理与模型优化部分往往需要具备专业知识的数据科学家来完成,他们建立起了数据到计算的桥梁。
然而,即使是数据科学家,也需要花费大量的精力来进行算法与模型的选择。
机器学习在各种应用中的成功,导致对机器学习从业人员的需求不断增长,因此我们希望实现真正意义上的机器学习,让尽可能多的工作也能够被自动化完成,进一步降低机器学习的门槛,让没有该领域专业知识的人也可以使用机器学习来完成相关的工作。
AutoML应运而生。
从传统机器学习模型出发,AutoML从特征工程、模型构建、超参优化三方面实现自动化;并且也提出了end-to-end的解决方案。本专栏,贯彻AutoML的思想,将门槛降到最低,简略介绍原理,侧重介绍AutoML开源工具的使用方法。本篇文章主要对AutoML各个工具的优劣特性进行总结对比,关于AutoML各个工具的详情见专栏中细分文章。
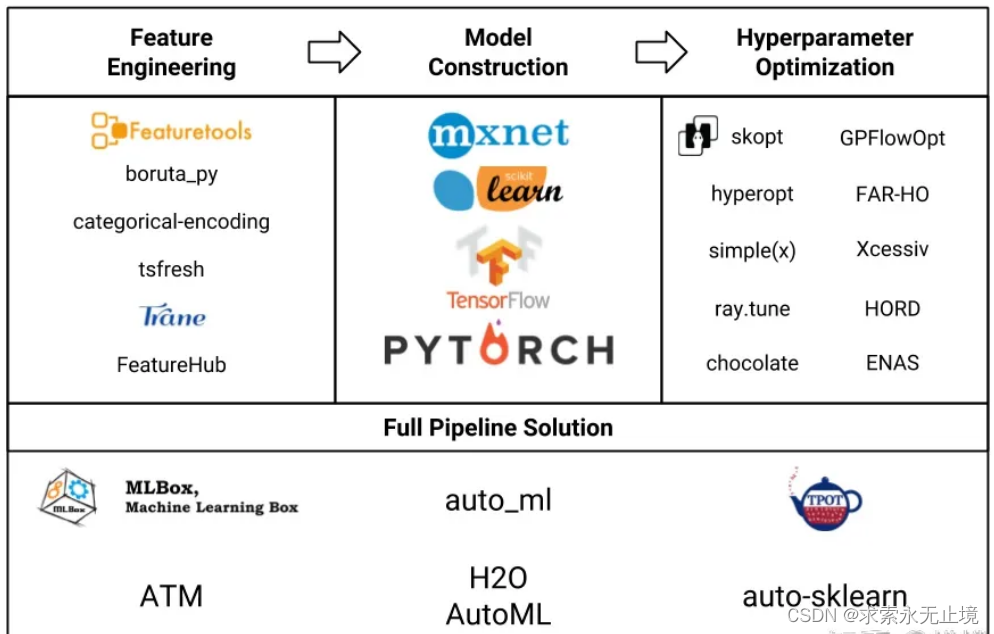
一. 特征工程
1、什么是特正工程
特征是从现实世界的具体物体到用数值表示的抽象数值化变换。
特征工程是将原始数据转化为特征的过程,这些特征可以更好地向预测模型描述潜在问题,从而提高模型对未见数据的准确性。
特征工程通常包括三个工作:特征生成、特征选择、特征编码
特征选择 在许多数据分析和建模项目中,数据科学家会收集到成百上千个特征。更糟糕的是,有时特征数目会大于样本数目。这种情况很普遍,但在大多数情况下,并不是所有的变量都是与机器试图理解和建模的内容相关的。所以数据科学家可以尝试设计一些有效的方法来选择那些重要的特征,并将它们合并到模型中,这叫做特征选择。
特征生成 一般是在特征选择之前,它提取的对象是原始数据,目的就是自动地构建新的特征,将原始数据转换为一组具有明显物理意义(比如 Gabor、几何特征、纹理特征)或者统计意义的特征。
特征编码 原始数据通常比较杂乱,可能会带有各种非数字特殊符号。而实际上机器学习模型需要的数据是数字型的,因为只有数字类型才能进行计算。因此,对于各种特殊的特征值,我们都需要对其进行相应的编码,也是量化的过程。
2 .为什么需要自动特征工程
在机器学习步骤中,特征工程会耗费数据科学家大量的人力去进行特征的提取和筛选,不仅耗费大量的时间,而且效率也不高。因此需要自动特征工程来将这些操作自动化,节省数据科学家的时间。
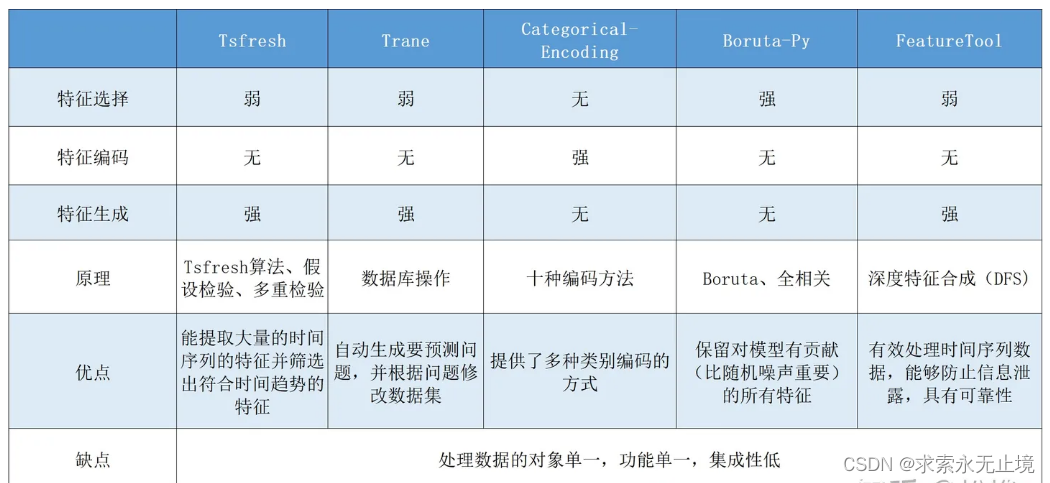
3.常见的特征工程工具总结和比较(重点)
本文调研了以下五种常用超参优化工具,并逐一撰写了报告发表在本文。
特征工程工具总结(1)——Tsfresh
特征工程工具总结(2)——Trane
特征工程工具总结(3)——Categorical Encoding
特征工程工具总结(4)——boruta_py
特征工程工具总结(5)——Featuretools
这里对这五种特征工程工具的功能、原理、优缺点等方面进行了评估了对比。
二、超参优化工具总结
1.什么是超参数优化
超参数是机器学习在学习之前预先设置好的参数,而非通过训练得到的参数,例如树的数量深度, 神经网络的学习率等,甚至在超参学习中神经网络的结构,包括层数,不同层的类型,层之间的连接方式等,都属于超参数的范畴。
手动修改调参既耗费大量的人力和时间,同时也难以寻找优化的方向,而对超参数选择进行优化既能节省大量人力和时间,又能让学习获得更好的性能和效果。因此出现了一系列的超参优化的工具来简化和改进超参选择和调整的过程。
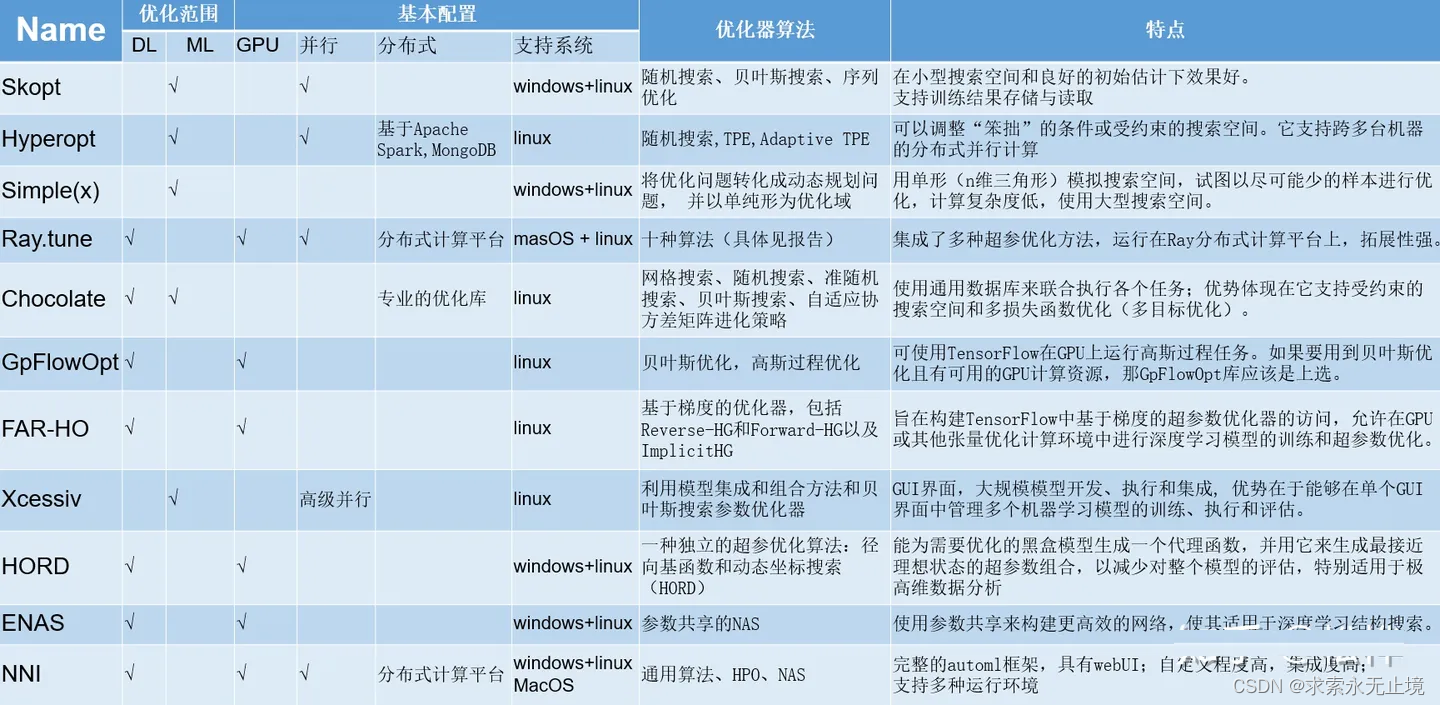
2. 十种超参优化工具的总结和比较
本专栏调研了以下十种常用超参优化工具,并逐一撰写了报告发表在本专栏。
超参优化工具总结(1)——Skopt
超参优化工具总结(2)——Hyperopt
超参优化工具总结(3)——Simple(x)
超参优化工具总结(4)——Ray.tune
超参优化工具总结(5)——Chocolate
超参优化工具总结(6)——GpFlowOpt
超参优化工具总结(7)——FAR-HO
超参优化工具总结(8)——Xcessiv
超参优化工具总结(9)——HORD
超参优化工具总结(10)——ENAS
超参优化工具总结(11)——NNI
这里从优化范围、基本配置、优化算法、各自的特点等五个方面对十一种工具进行了评估了对比。(注:表格增加了NNI的超参优化部分与其他超参优化工具的对比)。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











