







今天孩子学习爬虫练习,遇到如下错误:
bs4.FeatureNotFound: Couldn't find a tree builder with the features you requested: lxml. Do you need to install a parser library?
soup = bs4.BeautifulSoup(response.text, "lxml")
File "E:\乐乐python\venv\lib\site-packages\bs4\__init__.py", line 251, in __init__
% ",".join(features))
bs4.FeatureNotFound: Couldn't find a tree builder with the features you requested: lxml. Do you need to install a parser library?
代码如下:
# _*_ coding: UTF-8 _*_
# 开发团队: 信息化未来
# 开发人员: Administrator
# 开发时间:2022/9/3 12:01
# 文件名称: 网页新闻.py
# 开发工具: PyCharm
import requests, bs4, time
response = requests.get("https://icourse.xesimg.com/programme/static/py/pcdata/lw-web/新闻网站/index.html")
response.encoding = "UTF-8"
soup = bs4.BeautifulSoup(response.text, "lxml")
data1 = soup.find_all(name="div", attrs={'class': 'article'})
for n in data1:
data2 = n.find_all(name="a")
print("--------------------------------------")
print("题目:"+data2[0].text)
print("摘要:"+data2[1].text)
print("主题:"+data2[2].text)
提示soup = bs4.BeautifulSoup(response.text, "lxml")这句有误,xlml修改为html.parser
如下
soup = bs4.BeautifulSoup(response.text, "html.parser")
运行结果:
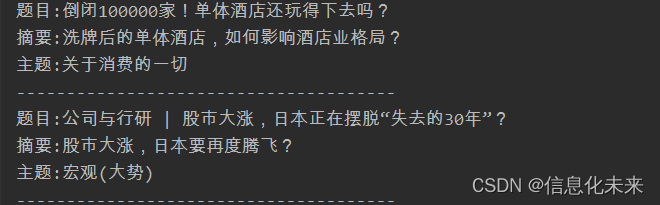
正常
原因:没有解析库安装包,还有第二种方法,不改原码,安装下html包就行了
pip install lxml

import requests, bs4, time
response = requests.get("https://icourse.xesimg.com/programme/static/py/pcdata/lw-web/新闻网站/index.html")
response.encoding = "UTF-8"
soup = bs4.BeautifulSoup(response.text, "lxml")
data1 = soup.find_all(name="div", attrs={'class': 'article'})
for n in data1:
data2 = n.find_all(name="a")
print("--------------------------------------")
print("题目:"+data2[0].text)
print("摘要:"+data2[1].text)
print("主题:"+data2[2].text)
运行也正常
















 968
968











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











