






- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
- 🚀 文章来源:K同学的学习圈子
📌 本周任务:
●1. 在DenseNet系列算法中插入SE-Net通道注意力机制,并完成猴痘病识别
●2. 改进思路是否可以迁移到其他地方呢
●3. 测试集accuracy到达89%(拔高,可选)
前言
SE-Net是ImageNet 2017 (lmageNet 收官赛)的冠军模型,是由WMW团队发布。具有复杂度低,参数少和计算量小的优点。且SENet 思路很简单,很容易扩展到已有网络结构如 Inception 和 ResNet 中。已经有很多工作在空间维度上来提升网络的性能,如 nception 等,而 SENet 将关注点放在了特征通道之间的关系上。其具体策略为: 通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征,这又叫做“特征重标定”策略。
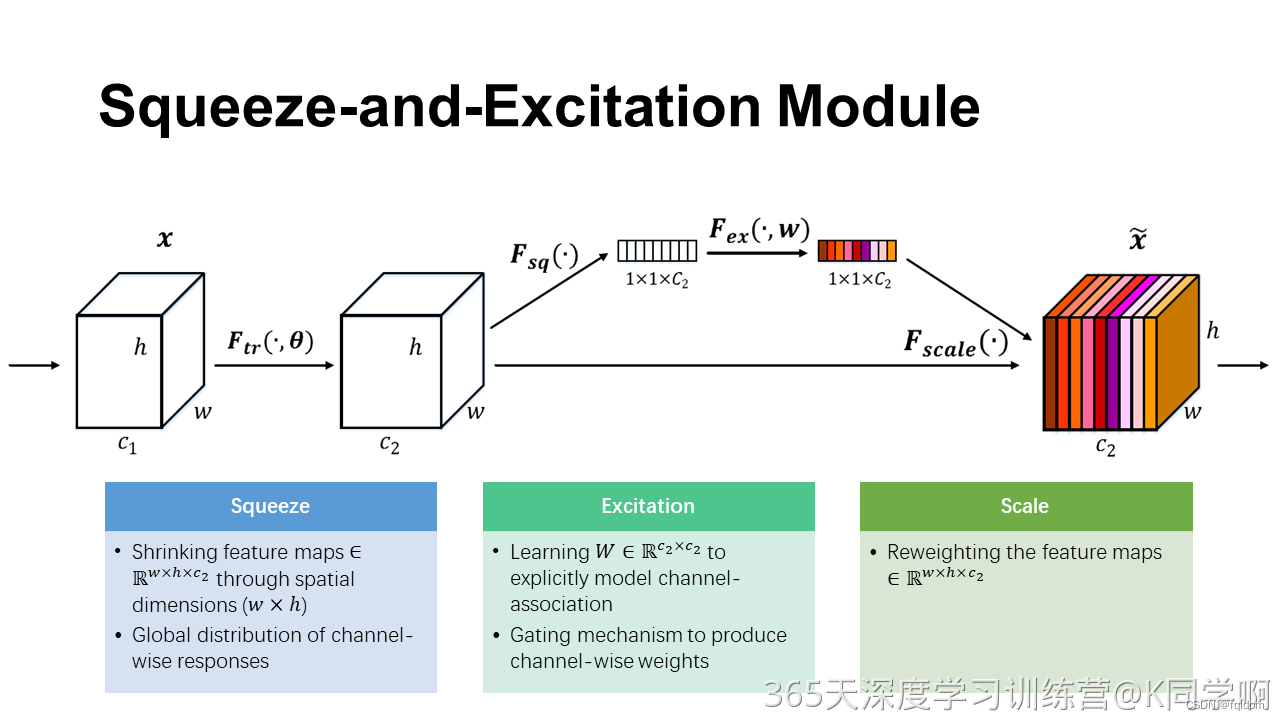
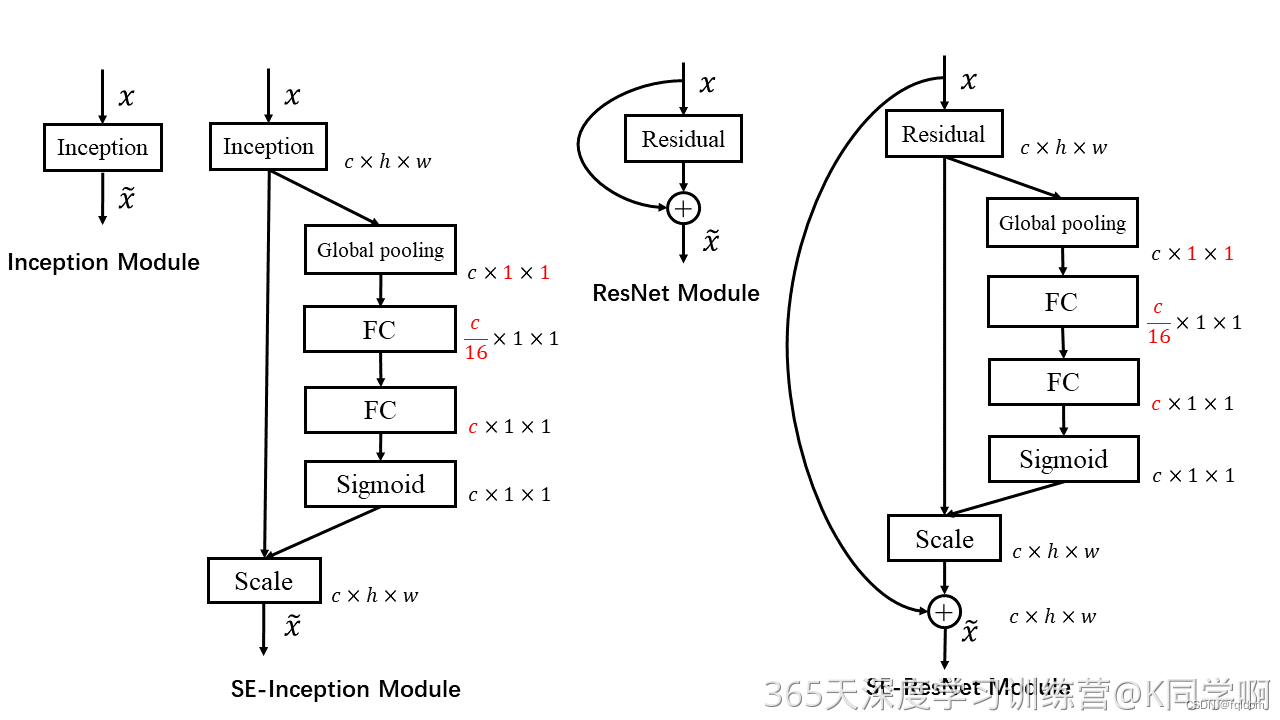
SE模块的灵活性在于它可以直接应用现有的网络结构中。以Inception 和 ResNet 为例,我们只需要在Inception 模块或 Residual 模块后添加一个SE 模块即可。具体如下图所示:
SE模块实现
class Squeeze_excitation_layer(nn.Module):
def __init__(self, channel, reduction=16):
super(Squeeze_excitation_layer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=True),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=True),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
在DenseNet中添加SE模块
class DenseLayer(nn.Sequential):
def __init__(self, in_channel, growth_rate, bn_size, drop_rate):
super(DenseLayer, self).__init__()
self.out_channels1 = bn_size * growth_rate
self.out_channels2 = growth_rate
self.add_module("norm1", nn.BatchNorm2d(num_features=in_channel))
self.add_module("relu1", nn.ReLU(inplace=True))
self.add_module("conv1", nn.Conv2d(in_channels=in_channel, out_channels=self.out_channels1, kernel_size=1, stride=1, padding=0, bias=False))
self.add_module("norm2", nn.BatchNorm2d(num_features=self.out_channels1))
self.add_module("relu2", nn.ReLU(inplace=True))
self.add_module("conv2", nn.Conv2d(in_channels=self.out_channels1, out_channels=self.out_channels2, kernel_size=3, stride=1, padding=1, bias=False))
self.drop_rate = drop_rate
def forward(self, x):
new_features = super(DenseLayer, self).forward(x)
if self.drop_rate>0:
new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)
return torch.cat([x, new_features], 1)
class DenseBlock(nn.Sequential):
def __init__(self, num_layers, in_channel, growth_rate, bn_size, drop_rate):
super(DenseBlock, self).__init__()
for i in range(num_layers):
layer = DenseLayer(in_channel+i*growth_rate, growth_rate, bn_size, drop_rate)
self.add_module('DenseLayer%d' %(i+1), layer)
class Transition(nn.Sequential):
def __init__(self, in_channel, out_channel):
super(Transition, self).__init__()
self.add_module("norm", nn.BatchNorm2d(num_features=in_channel))
self.add_module("relu", nn.ReLU(inplace=True))
self.add_module("conv", nn.Conv2d(in_channels=in_channel, out_channels=out_channel, kernel_size=1, stride=1, padding=0, bias=False))
self.add_module("pool", nn.AvgPool2d(2, stride=2))
class DenseNet_SE(nn.Module):
def __init__(self, growth_rate = 32, block_config=(6, 12, 24, 16), num_init_features=64,
bn_size=4, compression_rate=0.5, drop_rate=0, num_classes=4):
super(DenseNet_SE, self).__init__()
# basic_layer
self.in_channels = 3
self.basic_layer = nn.Sequential(
nn.Conv2d(self.in_channels, out_channels=num_init_features, kernel_size=7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(num_features=num_init_features),
nn.ReLU(inplace=False),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
self.features = self.basic_layer
# DenseBlock
self.num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = DenseBlock(num_layers, self.num_features, growth_rate, bn_size, drop_rate)
self.features.add_module('DenseBlock%d' %(i+1), block)
self.num_features += num_layers * growth_rate
if i != (len(block_config) - 1):
trans = Transition(self.num_features, int(self.num_features * compression_rate))
self.features.add_module('Transition%d' %(i+1), trans)
self.num_features = int(self.num_features * compression_rate)
# SE_layer
self.features.add_module('SE-module', Squeeze_excitation_layer(self.num_features))
# final_layer
self.features.add_module('norm_f', nn.BatchNorm2d(num_features=self.num_features))
self.add_module("relu_f", nn.ReLU(inplace=True))
# classfication layer
self.classifier = nn.Sequential(nn.Linear(self.num_features, num_classes),
nn.Softmax(dim=1))
# param initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self, x):
features = self.features(x)
out = F.avg_pool2d(features, 7, stride=1).view(features.size(0), -1)
out = self.classifier(out)
return out
在数据集上进行测试
导入数据
data_dir = "./data/bird_photos"
def random_split_imagefolder(data_dir, transforms, random_split_rate=0.8):
_total_data = datasets.ImageFolder(data_dir, transform=transforms)
train_size = int(random_split_rate * len(_total_data))
test_size = len(_total_data) - train_size
_train_datasets, _test_datasets = torch.utils.data.random_split(_total_data, [train_size, test_size])
return _total_data, _train_datasets, _test_datasets
N_classes=4
batch_size = 64
mean = [0.4958, 0.4984, 0.4068]
std = [0.2093, 0.2026, 0.2170]
# 真实均值-标准差重新读取数据
real_transforms = transforms.Compose(
[
transforms.Resize(224),#中心裁剪到224*224
transforms.ToTensor(),#转化成张量
transforms.Normalize(mean, std)
])
total_data, train_datasets, test_datasets = random_split_imagefolder(data_dir, real_transforms, 0.8)
# 批读取文件
train_data = torch.utils.data.DataLoader(train_datasets, batch_size=batch_size, shuffle=True)
test_data = torch.utils.data.DataLoader(test_datasets, batch_size=batch_size, shuffle=False)
train_data_size = len(train_datasets)
test_data_size = len(test_datasets)
训练与测试代码
from torch.utils.data import DataLoader
from tqdm import tqdm
def train_and_test(model, loss_func, optimizer, epochs=25):
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
summary.summary(model, (3, 224, 224))
record = []
best_acc = 0.0
best_epoch = 0
train_data = DataLoader(train_datasets, batch_size=batch_size, shuffle=True)
test_data = DataLoader(test_datasets, batch_size=batch_size, shuffle=True)
train_data_size = len(train_data.dataset)
test_data_size = len(test_data.dataset)
for epoch in range(epochs):#训练epochs轮
epoch_start = time.time()
print("Epoch: {}/{}".format(epoch + 1, epochs))
model.train()#训练
train_loss = 0.0
train_acc = 0.0
valid_loss = 0.0
valid_acc = 0.0
for i, (inputs, labels) in enumerate(train_data):
inputs = inputs.to(device)
labels = labels.to(device)
#print(labels)
# 记得清零
optimizer.zero_grad()
outputs = model(inputs)
loss = loss_func(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item() * inputs.size(0)
ret, predictions = torch.max(outputs.data, 1)
correct_counts = predictions.eq(labels.data.view_as(predictions))
acc = torch.mean(correct_counts.type(torch.FloatTensor))
train_acc += acc.item() * inputs.size(0)
with torch.no_grad():
model.eval()#验证
for j, (inputs, labels) in enumerate(test_data):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = loss_func(outputs, labels)
valid_loss += loss.item() * inputs.size(0)
ret, predictions = torch.max(outputs.data, 1)
correct_counts = predictions.eq(labels.data.view_as(predictions))
acc = torch.mean(correct_counts.type(torch.FloatTensor))
valid_acc += acc.item() * inputs.size(0)
avg_train_loss = train_loss / train_data_size
avg_train_acc = train_acc / train_data_size
avg_valid_loss = valid_loss / test_data_size
avg_valid_acc = valid_acc / test_data_size
record.append([avg_train_loss, avg_valid_loss, avg_train_acc, avg_valid_acc])
if avg_valid_acc > best_acc :#记录最高准确性的模型
best_acc = avg_valid_acc
best_epoch = epoch + 1
epoch_end = time.time()
print("Epoch: {:03d}, Training: Loss: {:.4f}, Accuracy: {:.4f}%, \n\t\tValidation: Loss: {:.4f}, Accuracy: {:.4f}%, Time: {:.4f}s".format(
epoch + 1, avg_valid_loss, avg_train_acc * 100, avg_valid_loss, avg_valid_acc * 100,
epoch_end - epoch_start))
print("Best Accuracy for validation : {:.4f} at epoch {:03d}".format(best_acc, best_epoch))
return model, record
正式训练
epochs = 100
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(),lr=0.001)
model, record = train_and_test(model, loss_func, optimizer, epochs)
record = np.array(record)
plt.plot(record[:, 0:2])
plt.legend(['Train Loss', 'Valid Loss'])
plt.xlabel('Epoch Number')
plt.ylabel('Loss')
plt.ylim(0, 1.5)
plt.savefig('Loss.png')
plt.show()
plt.plot(record[:, 2:4])
plt.legend(['Train Accuracy', 'Valid Accuracy'])
plt.xlabel('Epoch Number')
plt.ylabel('Accuracy')
plt.ylim(0, 1)
plt.savefig('Accuracy.png')
plt.show()
测试结果
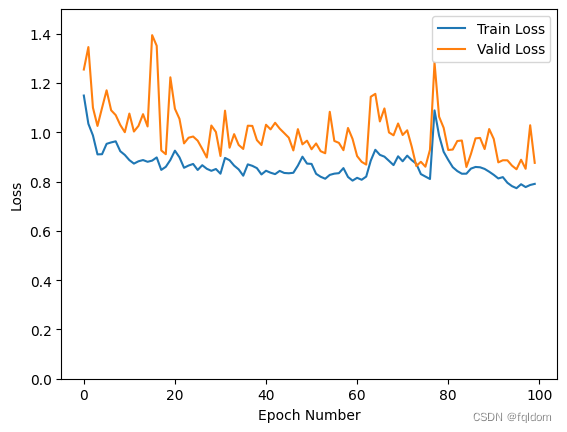
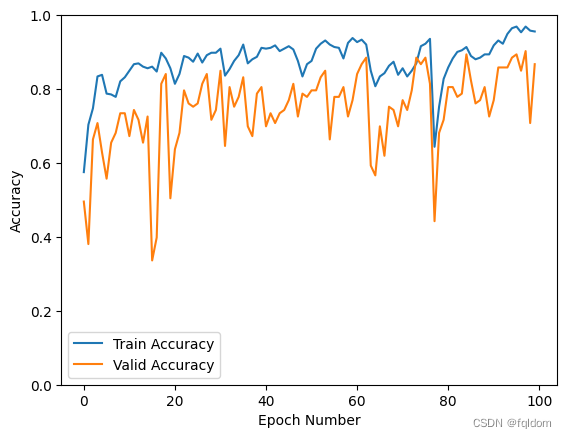
记录最优结果
best_val_acc = np.max(record[:, 3])
print("The highest validation accuracy is {:.4f} at epoch {:03d}".format(best_val_acc, np.argmax(record[:, 3]) + 1))
The highest validation accuracy is 0.9027 at epoch 098
添加SE模块后val_accuracy可达到90.27%
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









