






 本文介绍了如何基于Pytorch实现ResNetV2模型,对比了ResNet50与ResNetV2的差异,详细展示了ResNetV2的Block结构,并提供了在CIFAR-10数据集上的训练过程。代码包括了ResNetV2的网络结构定义和训练、测试函数。
本文介绍了如何基于Pytorch实现ResNetV2模型,对比了ResNet50与ResNetV2的差异,详细展示了ResNetV2的Block结构,并提供了在CIFAR-10数据集上的训练过程。代码包括了ResNetV2的网络结构定义和训练、测试函数。
- 🍨 本文为🔗365天深度学习训练营 中的学习记录博客
- 🍖 原作者:K同学啊 | 接辅导、项目定制
- 🚀 文章来源:K同学的学习圈子
📌 本周任务:
●1.请根据本文 TensorFlow 代码,编写出相应的 Pytorch 代码(建议使用上周的数据测试一下模型是否构建正确)
●2.了解ResNetV2与ResNetV的区别
●3.改进思路是否可以迁移到其他地方呢(自由探索)
前言
上周复现了何恺明在2015年提出的深度残差网络ResNet,大神在后来的论文中提到一种全新的残差单元,我们命名为ResNet_V2, 本文将在上周的基础上基于Pytorch实现ResNet_V2模型。
一、ResNet50 VS ResNet_V2 的异同
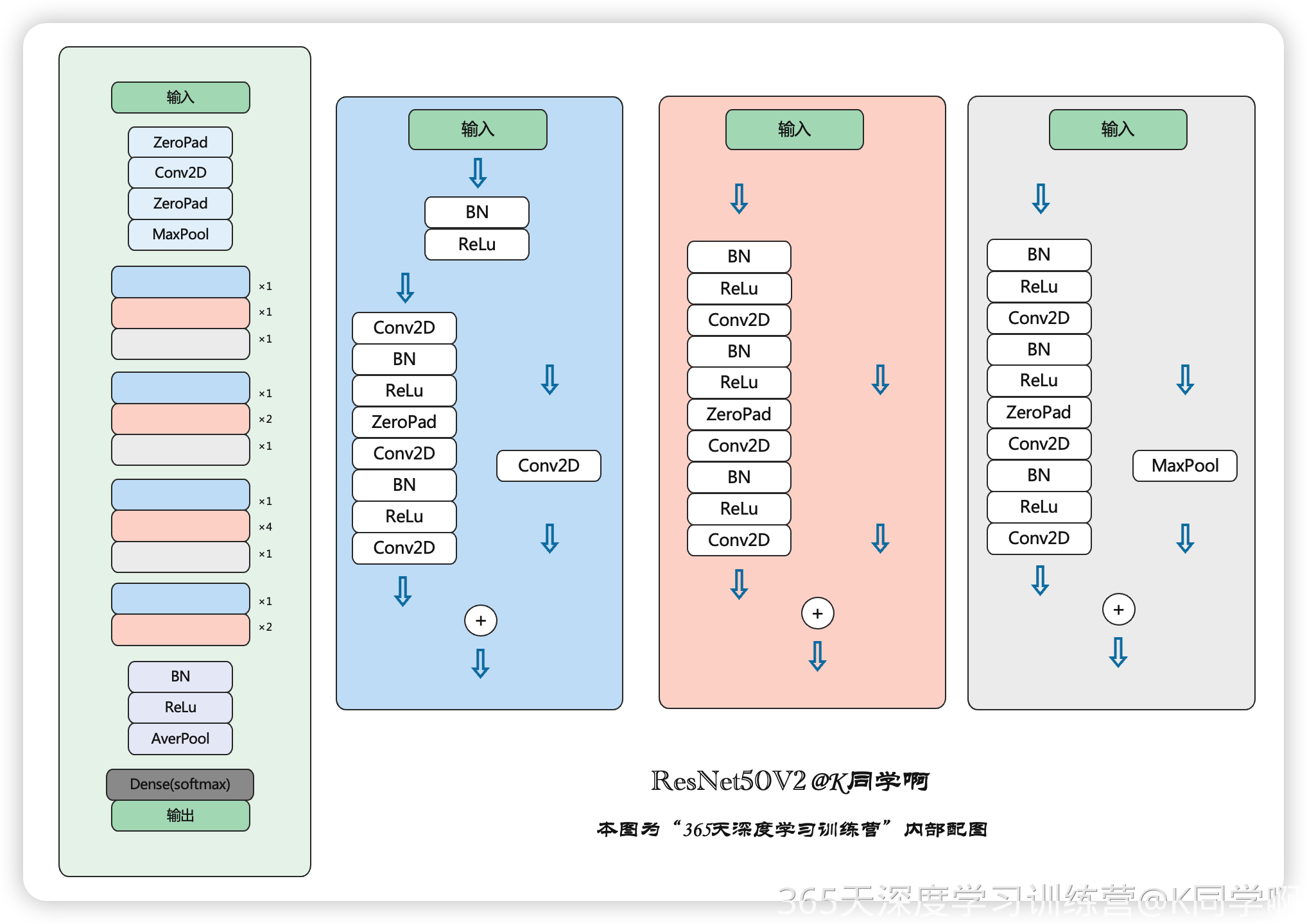
ResNet50_V2 的框架图多了下面红色框框里的block,不难看出这个block其实就是把ResNet50里面的Conv Block 模块 的conv2d 改成了 MaxPool。
二、ResNet_V2实现
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os, PIL, pathlib, warnings
from torchsummary import summary
#忽略警告信息
warnings.filterwarnings("ignore")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
"""
Residual Block
"""
class Block2(nn.Module):
def __init__(self, in_channel, filters, kernel_size=3, stride=1, conv_shortcut=False):
super(Block2, self).__init__()
self.preact = nn.Sequential(
nn.BatchNorm2d(in_channel),
nn.ReLU(True)
)
self.shortcut = conv_shortcut
if self.shortcut:
self.short = nn.Conv2d(in_channel, 4*filters, 1, stride=stride, padding=0, bias=False)
elif stride>1:
self.short = nn.MaxPool2d(kernel_size=1, stride=stride, padding=0)
else:
self.short = nn.Identity()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channel, filters, 1, stride=1, bias=False),
nn.BatchNorm2d(filters),
nn.ReLU(True)
)
self.conv2 = nn.Sequential(
nn.Conv2d(filters, filters, kernel_size, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(filters),
nn.ReLU(True)
)
self.conv3 = nn.Conv2d(filters, 4*filters, 1, stride=1, bias=False)
def forward(self, x):
x1 = self.preact(x)
if self.shortcut:
x2 = self.short(x1)
else:
x2 = self.short(x)
x1 = self.conv1(x1)
x1 = self.conv2(x1)
x1 = self.conv3(x1)
x = x1 + x2
return x
class Stack2(nn.Module):
def __init__(self, in_channel, filters, blocks, stride=2):
super(Stack2, self).__init__()
self.conv = nn.Sequential()
self.conv.add_module(str(0), Block2(in_channel, filters, conv_shortcut=True))
for i in range(1, blocks-1):
self.conv.add_module(str(i), Block2(4*filters, filters))
self.conv.add_module(str(blocks-1), Block2(4*filters, filters, stride=stride))
def forward(self, x):
x = self.conv(x)
return x
"""
构建ResNet50V2
"""
class ResNet50V2(nn.Module):
def __init__(self,
include_top=True, # 是否包含位于网络顶部的全链接层
preact=True, # 是否使用预激活
use_bias=True, # 是否对卷积层使用偏置
input_shape=[224, 224, 3],
classes=1000,
pooling=None): # 用于分类图像的可选类数
super(ResNet50V2, self).__init__()
self.conv1 = nn.Sequential()
self.conv1.add_module('conv', nn.Conv2d(3, 64, 7, stride=2, padding=3, bias=use_bias, padding_mode='zeros'))
if not preact:
self.conv1.add_module('bn', nn.BatchNorm2d(64))
self.conv1.add_module('relu', nn.ReLU())
self.conv1.add_module('max_pool', nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
self.conv2 = Stack2(64, 64, 3)
self.conv3 = Stack2(256, 128, 4)
self.conv4 = Stack2(512, 256, 6)
self.conv5 = Stack2(1024, 512, 3, stride=1)
self.post = nn.Sequential()
if preact:
self.post.add_module('bn', nn.BatchNorm2d(2048))
self.post.add_module('relu', nn.ReLU())
if include_top:
self.post.add_module('avg_pool', nn.AdaptiveAvgPool2d((1, 1)))
self.post.add_module('flatten', nn.Flatten())
self.post.add_module('fc', nn.Linear(2048, classes))
else:
if pooling=='avg':
self.post.add_module('avg_pool', nn.AdaptiveAvgPool2d((1, 1)))
elif pooling=='max':
self.post.add_module('max_pool', nn.AdaptiveMaxPool2d((1, 1)))
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = self.post(x)
return x
model = ResNet50V2().to(device)
summary(model, (3, 224, 224))
三、在CIFAR-10上进行训练
import torchvision.datasets as datasets
import torchvision.transforms as transforms
# 定义预处理转换
transform = transforms.Compose([
transforms.ToTensor(), # 将 PIL 图像转换为张量
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 归一化
])
# 加载 CIFAR-10 数据集
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=transform)
test_dataset = datasets.CIFAR10(root='./data', train=False, download=True, transform=transform)
# 创建数据加载器
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=64, shuffle=False)
def train(dataloader,model,loss_fn,optimizer):
size = len(dataloader.dataset)
num_batches = len(dataloader)
train_loss,train_acc = 0,0
for x,y in dataloader:
x,y = x.to(device),y.to(device)
pred = model(x)
loss = loss_fn(pred,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
train_loss += loss.item()
train_acc += (pred.argmax(1)==y).type(torch.float).sum().item()
train_loss /= num_batches
train_acc /= size
return train_loss,train_acc
def test(dataloader,model,loss_fn):
size = len(dataloader.dataset)
num_batches = len(dataloader)
test_loss,test_acc = 0,0
with torch.no_grad():
for x,y in dataloader:
x,y = x.to(device),y.to(device)
pred = model(x)
loss = loss_fn(pred,y)
test_loss += loss.item()
test_acc += (pred.argmax(1)==y).type(torch.float).sum().item()
test_loss /= num_batches
test_acc /= size
return test_loss,test_acc
loss_fn = nn.CrossEntropyLoss()
epochs = 50
train_loss = []
train_acc = []
test_loss = []
test_acc = []
best_acc = 0
learning_rate = 1e-3
optimizer = torch.optim.Adam(model.parameters(),lr=learning_rate)
for epoch in range(1,epochs+1):
model.train()
eopch_train_loss,epoch_train_acc = train(train_loader,model,loss_fn,optimizer)
model.eval()
epoch_test_loss,epoch_test_acc = test(test_loader,model,loss_fn)
train_loss.append(eopch_train_loss)
train_acc.append(epoch_train_acc)
test_loss.append(epoch_test_loss)
test_acc.append(epoch_test_acc)
lr = optimizer.param_groups[0]['lr']
tmp = "Epoch:{},lr:{:.6f},train_loss:{:.4f},train_acc:{:.4f},test_loss:{:.4f},test_acc:{:.4f}"
print(tmp.format(epoch,lr,eopch_train_loss,epoch_train_acc,epoch_test_loss,epoch_test_acc))
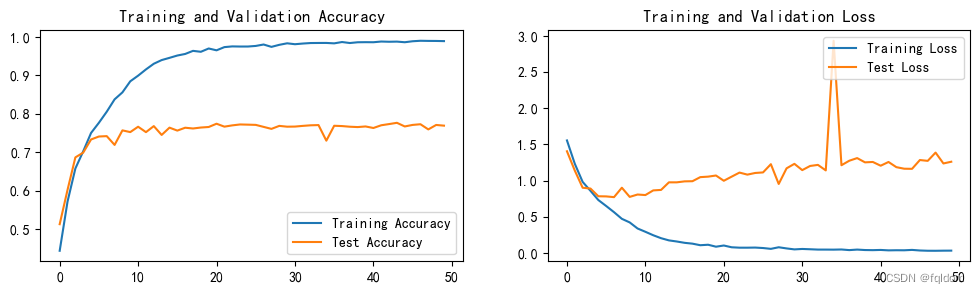
四、效果可视化
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()

















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









