






🍨 本文为🔗365天深度学习训练营 中的学习记录博客
🍦 参考文章:[Pytorch实战 | 第J4周:ResNet与DenseNet结合探索
🍖 原作者:K同学啊|接辅导、项目定制
一、模型准备
ResNet50_V2
import torch
from torchvision import datasets, transforms
import torch.nn as nn
import time
import numpy as np
import matplotlib.pyplot as plt
import torchsummary as summary
import os
from collections import OrderedDict
class IdentityBlock_V2(nn.Module):
def __init__(self, in_channel, kl_size, filters):
super(IdentityBlock_V2, self).__init__()
filter1, filter2, filter3 = filters
self.bn0 = nn.BatchNorm2d(num_features=in_channel)
self.cov1 = nn.Conv2d(in_channels=in_channel, out_channels=filter1, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(num_features=filter1)
self.relu = nn.ReLU(inplace=True)
self.zeropadding2d1 = nn.ZeroPad2d(1)
self.cov2 = nn.Conv2d(in_channels=filter1, out_channels=filter2, kernel_size=kl_size, stride=1, padding=0)
self.bn2 = nn.BatchNorm2d(num_features=filter2)
self.cov3 = nn.Conv2d(in_channels=filter2, out_channels=filter3, kernel_size=1, stride=1, padding=0)
self.bn3 = nn.BatchNorm2d(num_features=filter3)
def forward(self, x):
identity = self.bn0(x)
identity = self.relu(identity)
identity = self.cov1(identity)
identity = self.bn1(identity)
identity = self.relu(identity)
identity = self.zeropadding2d1(identity)
identity = self.cov2(identity)
identity = self.bn2(identity)
identity = self.relu(identity)
identity = self.cov3(identity)
x = identity + x
x = self.relu(x)
return x
class ConvBlock_V2(nn.Module):
def __init__(self, in_channel, kl_size, filters, stride_size=2, conv_shortcut=False):
super(ConvBlock_V2, self).__init__()
filter1, filter2, filter3 = filters
self.bn0 = nn.BatchNorm2d(num_features=in_channel)
self.cov1 = nn.Conv2d(in_channels=in_channel, out_channels=filter1, kernel_size=1, stride=stride_size, padding=0)
self.bn1 = nn.BatchNorm2d(num_features=filter1)
self.relu = nn.ReLU(inplace=True)
self.zeropadding2d1 = nn.ZeroPad2d(1)
self.cov2 = nn.Conv2d(in_channels=filter1, out_channels=filter2, kernel_size=kl_size, stride=1, padding=0)
self.bn2 = nn.BatchNorm2d(num_features=filter2)
self.cov3 = nn.Conv2d(in_channels=filter2, out_channels=filter3, kernel_size=1, stride=1, padding=0)
self.bn3 = nn.BatchNorm2d(num_features=filter3)
self.conv_shortcut = conv_shortcut
if self.conv_shortcut:
self.short_cut = nn.Conv2d(in_channels=in_channel, out_channels=filter3, kernel_size=1, stride=stride_size, padding=0)
else:
self.short_cut = nn.MaxPool2d(kernel_size=1, stride=stride_size, padding=0)
def forward(self, x):
identity = self.bn0(x)
identity = self.relu(identity)
short_cut = self.short_cut(identity)
identity = self.cov1(identity)
identity = self.bn1(identity)
identity = self.relu(identity)
identity = self.zeropadding2d1(identity)
identity = self.cov2(identity)
identity = self.bn2(identity)
identity = self.relu(identity)
identity = self.cov3(identity)
x = identity + short_cut
x = self.relu(x)
return x
class Resnet50_Model_V2(nn.Module):
def __init__(self, in_channel, N_classes):
super(Resnet50_Model_V2, self).__init__()
self.in_channels = in_channel
# ============= 基础层
# 方法1
self.zeropadding2d_0 = nn.ZeroPad2d(3)
self.cov0 = nn.Conv2d(self.in_channels, out_channels=64, kernel_size=7, stride=2)
self.zeropadding2d_1 = nn.ZeroPad2d(1)
self.maxpool0 = nn.MaxPool2d(kernel_size=3, stride=2, padding=0)
self.layer1 = nn.Sequential(
ConvBlock_V2(64, 3, [64, 64, 256], 1, 1),
IdentityBlock_V2(256, 3, [64, 64, 256]),
ConvBlock_V2(256, 3, [64, 64, 256], 2, 0),
)
self.layer2 = nn.Sequential(
ConvBlock_V2(256, 3, [128, 128, 512], 1, 1),
IdentityBlock_V2(512, 3, [128, 128, 512]),
IdentityBlock_V2(512, 3, [128, 128, 512]),
ConvBlock_V2(512, 3, [128, 128, 512], 2, 0),
)
self.layer3 = nn.Sequential(
ConvBlock_V2(512, 3, [256, 256, 1024], 1, 1),
IdentityBlock_V2(1024, 3, [256, 256, 1024]),
IdentityBlock_V2(1024, 3, [256, 256, 1024]),
IdentityBlock_V2(1024, 3, [256, 256, 1024]),
IdentityBlock_V2(1024, 3, [256, 256, 1024]),
ConvBlock_V2(1024, 3, [256, 256, 1024], 2, 0),
)
self.layer4 = nn.Sequential(
ConvBlock_V2(1024, 3, [512, 512, 2048], 1, 1),
IdentityBlock_V2(2048, 3, [512, 512, 2048]),
IdentityBlock_V2(2048, 3, [512, 512, 2048]),
)
# 输出网络
self.bn = nn.BatchNorm2d(num_features=2048)
self.relu = nn.ReLU(inplace=True)
self.avgpool = nn.AvgPool2d((7, 7))
# classfication layer
# 7*7均值后2048个参数
self.fc = nn.Sequential(nn.Linear(2048, N_classes),
nn.Softmax(dim=1))
def basic_layer1(self, x):
'''
input: x = tensor(3, 224, 224).unsqueeze(0)
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 64, 112, 112] 9,408
BatchNorm2d-2 [-1, 64, 112, 112] 128
ReLU-3 [-1, 64, 112, 112] 0
MaxPool2d-4 [-1, 64, 56, 56] 0
================================================================
'''
x = self.zeropadding2d_0(x)
x = self.cov0(x)
x = self.zeropadding2d_1(x)
x = self.maxpool0(x)
return x
def forward(self, x):
x = self.forward1(x)
return x
def forward1(self, x):
x = self.basic_layer1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.bn(x)
x = self.relu(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return x
DenseNet
import torch
from torchvision import datasets, transforms
import torch.nn as nn
import time
import numpy as np
import matplotlib.pyplot as plt
import torch.nn.functional as F
import torchsummary as summary
import os
from collections import OrderedDict
class DenseLayer(nn.Sequential):
def __init__(self, in_channel, growth_rate, bn_size, drop_rate):
super(DenseLayer, self).__init__()
self.out_channels1 = bn_size * growth_rate
self.out_channels2 = growth_rate
self.add_module("norm1", nn.BatchNorm2d(num_features=in_channel))
self.add_module("relu1", nn.ReLU(inplace=True))
self.add_module("conv1", nn.Conv2d(in_channels=in_channel, out_channels=self.out_channels1, kernel_size=1, stride=1, padding=0, bias=False))
self.add_module("norm2", nn.BatchNorm2d(num_features=self.out_channels1))
self.add_module("relu2", nn.ReLU(inplace=True))
self.add_module("conv2", nn.Conv2d(in_channels=self.out_channels1, out_channels=self.out_channels2, kernel_size=3, stride=1, padding=1, bias=False))
self.drop_rate = drop_rate
def forward(self, x):
new_features = super(DenseLayer, self).forward(x)
if self.drop_rate>0:
new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)
return torch.cat([x, new_features], 1)
class DenseBlock(nn.Sequential):
def __init__(self, num_layers, in_channel, growth_rate, bn_size, drop_rate):
super(DenseBlock, self).__init__()
for i in range(num_layers):
layer = DenseLayer(in_channel+i*growth_rate, growth_rate, bn_size, drop_rate)
self.add_module('DenseLayer%d' %(i+1), layer)
class Transition(nn.Sequential):
def __init__(self, in_channel, out_channel):
super(Transition, self).__init__()
self.add_module("norm", nn.BatchNorm2d(num_features=in_channel))
self.add_module("relu", nn.ReLU(inplace=True))
self.add_module("conv", nn.Conv2d(in_channels=in_channel, out_channels=out_channel, kernel_size=1, stride=1, padding=0, bias=False))
self.add_module("pool", nn.AvgPool2d(2, stride=2))
class DenseNet(nn.Module):
def __init__(self, growth_rate = 32, block_config=(6, 12, 24, 16), num_init_features=64,
bn_size=4, compression_rate=0.5, drop_rate=0, num_classes=4):
super(DenseNet, self).__init__()
# basic_layer
self.in_channels = 3
self.basic_layer = nn.Sequential(
nn.Conv2d(self.in_channels, out_channels=num_init_features, kernel_size=7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(num_features=num_init_features),
nn.ReLU(inplace=False),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
self.features = self.basic_layer
# DenseBlock
self.num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = DenseBlock(num_layers, self.num_features, growth_rate, bn_size, drop_rate)
self.features.add_module('DenseBlock%d' %(i+1), block)
self.num_features += num_layers * growth_rate
if i != (len(block_config) - 1):
trans = Transition(self.num_features, int(self.num_features * compression_rate))
self.features.add_module('Transition%d' %(i+1), trans)
self.num_features = int(self.num_features * compression_rate)
# final_layer
self.features.add_module('norm_f', nn.BatchNorm2d(num_features=self.num_features))
self.add_module("relu_f", nn.ReLU(inplace=True))
# classfication layer
self.classifier = nn.Sequential(nn.Linear(self.num_features, num_classes),
nn.Softmax(dim=1))
# param initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self, x):
features = self.features(x)
out = F.avg_pool2d(features, 7, stride=1).view(features.size(0), -1)
out = self.classifier(out)
return out
def densenet121(pretrained=False, **kwargs):
model = DenseNet(growth_rate = 32, block_config=(6, 12, 24, 16), num_init_features=64)
if pretrained:
summary.summary(model, (3, 224, 224))
return model
将两个模型结合
class DenseNet_Resnet(nn.Module):
def __init__(self, growth_rate = 32, block_config=(6, 12, 24, 16), num_init_features=64,
bn_size=4, compression_rate=0.5, drop_rate=0, num_classes=4):
super(DenseNet_Resnet, self).__init__()
# basic_layer
self.in_channels = 3
self.basic_layer = nn.Sequential(
nn.Conv2d(self.in_channels, out_channels=num_init_features, kernel_size=7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(num_features=num_init_features),
nn.ReLU(inplace=False),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
self.features = self.basic_layer
# DenseBlock
self.num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = DenseBlock(num_layers, self.num_features, growth_rate, bn_size, drop_rate)
self.features.add_module('DenseBlock%d' %(i+1), block)
self.num_features += num_layers * growth_rate
if i != (len(block_config) - 1):
trans = Transition(self.num_features, int(self.num_features * compression_rate))
self.features.add_module('Transition%d' %(i+1), trans)
self.num_features = int(self.num_features * compression_rate)
# Resnet50_V2
Resnet_ConvBlock_V2 = ConvBlock_V2(self.num_features, 3, [int(self.num_features/2), int(self.num_features/2), self.num_features * 2], 1, 1)
self.features.add_module('ConvBlock_V2%d' %(i+1), Resnet_ConvBlock_V2)
self.num_features = self.num_features * 2
# final_layer
self.features.add_module('norm_f', nn.BatchNorm2d(num_features=self.num_features))
self.add_module("relu_f", nn.ReLU(inplace=True))
# classfication layer
self.classifier = nn.Sequential(nn.Linear(self.num_features, num_classes),
nn.Softmax(dim=1))
# param initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self, x):
features = self.features(x)
out = F.avg_pool2d(features, 7, stride=1).view(features.size(0), -1)
out = self.classifier(out)
return out
模型可视化
model = DenseNet_Resnet()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
summary.summary(model, (3, 224, 224))
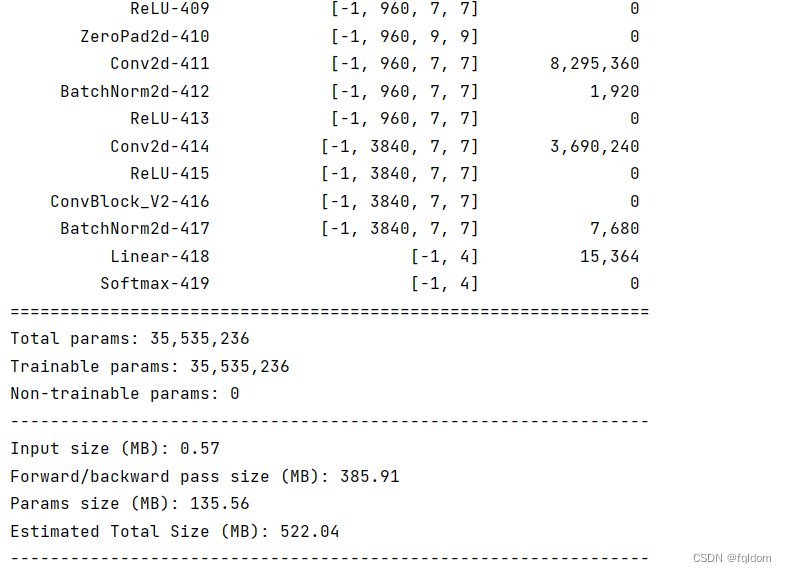
很明显参数量增加不少
二、训练
导入本地数据
data_dir = './data/bird_photos'
# 归一化参数是怎么来的, tf模型中没有归一化这个过程会不会导致结果不一致?
raw_transforms = transforms.Compose(
[
transforms.Resize(224),#中心裁剪到224*224
transforms.ToTensor(),#转化成张量)
])
def random_split_imagefolder(data_dir, transforms, random_split_rate=0.8):
_total_data = datasets.ImageFolder(data_dir, transform=transforms)
train_size = int(random_split_rate * len(_total_data))
test_size = len(_total_data) - train_size
_train_datasets, _test_datasets = torch.utils.data.random_split(_total_data, [train_size, test_size])
return _total_data, _train_datasets, _test_datasets
batch_size = 32
total_data, train_datasets, test_datasets = random_split_imagefolder(data_dir, raw_transforms, 0.8)
from torch.utils.data import DataLoader
from tqdm import tqdm
def train_and_test(model, loss_func, optimizer, epochs=25):
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model.to(device)
summary.summary(model, (3, 224, 224))
record = []
best_acc = 0.0
best_epoch = 0
train_data = DataLoader(train_datasets, batch_size=batch_size, shuffle=True)
test_data = DataLoader(test_datasets, batch_size=batch_size, shuffle=True)
train_data_size = len(train_data.dataset)
test_data_size = len(test_data.dataset)
for epoch in range(epochs):#训练epochs轮
epoch_start = time.time()
print("Epoch: {}/{}".format(epoch + 1, epochs))
model.train()#训练
train_loss = 0.0
train_acc = 0.0
valid_loss = 0.0
valid_acc = 0.0
for i, (inputs, labels) in enumerate(train_data):
inputs = inputs.to(device)
labels = labels.to(device)
#print(labels)
# 记得清零
optimizer.zero_grad()
outputs = model(inputs)
loss = loss_func(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item() * inputs.size(0)
ret, predictions = torch.max(outputs.data, 1)
correct_counts = predictions.eq(labels.data.view_as(predictions))
acc = torch.mean(correct_counts.type(torch.FloatTensor))
train_acc += acc.item() * inputs.size(0)
with torch.no_grad():
model.eval()#验证
for j, (inputs, labels) in enumerate(test_data):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = loss_func(outputs, labels)
valid_loss += loss.item() * inputs.size(0)
ret, predictions = torch.max(outputs.data, 1)
correct_counts = predictions.eq(labels.data.view_as(predictions))
acc = torch.mean(correct_counts.type(torch.FloatTensor))
valid_acc += acc.item() * inputs.size(0)
avg_train_loss = train_loss / train_data_size
avg_train_acc = train_acc / train_data_size
avg_valid_loss = valid_loss / test_data_size
avg_valid_acc = valid_acc / test_data_size
record.append([avg_train_loss, avg_valid_loss, avg_train_acc, avg_valid_acc])
if avg_valid_acc > best_acc :#记录最高准确性的模型
best_acc = avg_valid_acc
best_epoch = epoch + 1
epoch_end = time.time()
print("Epoch: {:03d}, Training: Loss: {:.4f}, Accuracy: {:.4f}%, \n\t\tValidation: Loss: {:.4f}, Accuracy: {:.4f}%, Time: {:.4f}s".format(
epoch + 1, avg_valid_loss, avg_train_acc * 100, avg_valid_loss, avg_valid_acc * 100,
epoch_end - epoch_start))
print("Best Accuracy for validation : {:.4f} at epoch {:03d}".format(best_acc, best_epoch))
return model, record
正式训练
epochs = 100
model = DenseNet_Resnet()
loss_func = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(),lr=0.001)
model, record = train_and_test(model, loss_func, optimizer, epochs)
record = np.array(record)
plt.plot(record[:, 0:2])
plt.legend(['Train Loss', 'Valid Loss'])
plt.xlabel('Epoch Number')
plt.ylabel('Loss')
plt.ylim(0, 1.5)
plt.savefig('Loss.png')
plt.show()
plt.plot(record[:, 2:4])
plt.legend(['Train Accuracy', 'Valid Accuracy'])
plt.xlabel('Epoch Number')
plt.ylabel('Accuracy')
plt.ylim(0, 1)
plt.savefig('Accuracy.png')
plt.show()
三、运行结果
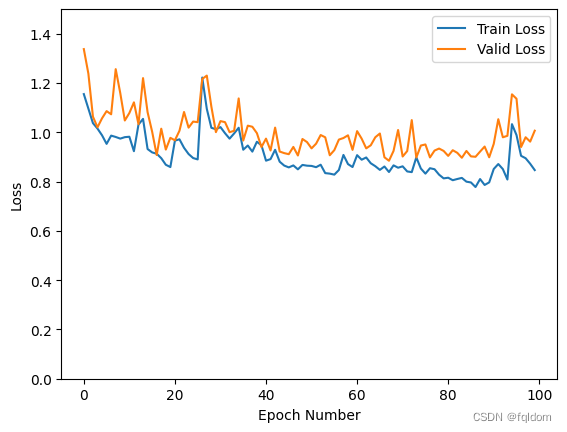
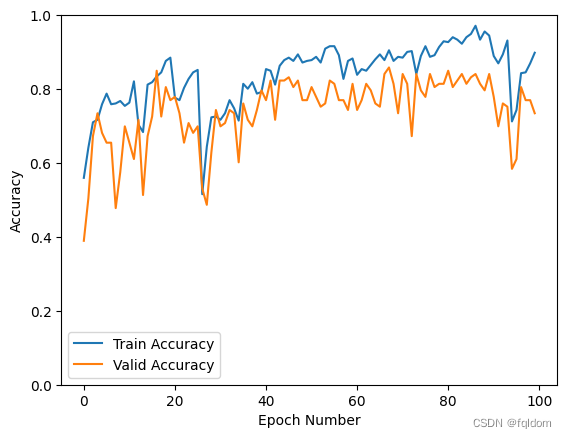
结果比单独使用DenseNet或者RenNet要好一点。















 820
820











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









