






这部分将实现数据库的持久存储,文章原地址:https://cstack.github.io/db_tutorial/parts/part5.html
“Nothing in the world can take the place of persistence.” – Calvin Coolidge
我们的数据库能插入记录并读回记录,但前提是保持程序运行。如果你终止了程序并重新启动它,那所有存储的记录都将小时。以下是我们想要的行为的规范:
it 'keeps data after closing connection' do
result1 = run_script([
"insert 1 user1 person1@example.com",
".exit",
])
expect(result1).to match_array([
"db > Executed.",
"db > ",
])
result2 = run_script([
"select",
".exit",
])
expect(result2).to match_array([
"db > (1, user1, person1@example.com)",
"Executed.",
"db > ",
])
end
就像sqlite一样,我们通过把整个数据库保存到文件中来持久化数据。
我们已经通过把行序列化为页大小的内存块来做到这一点。为了进一步提高数据的持久性,我们可以简单地把这些内存块写入文件中, 并在下次启动程序是把它们读回内存中。
为了简化操作,我们将做一个抽象的寻址器。我们将向寻址器询问页的位置,它会向我们返回一个内存块。它首先在缓存中搜索页。如果在缓存中没找到,它将把数据从磁盘移入缓存。
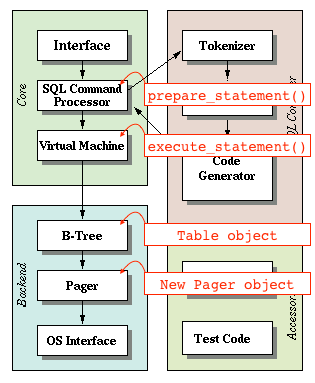
寻址器能访问缓存的页和文件。表对象可以通过寻址器请求读取页:
+typedef struct {
+ int file_descriptor;
+ uint32_t file_length;
+ void* pages[TABLE_MAX_PAGES];
+} Pager;
+
typedef struct {
- void* pages[TABLE_MAX_PAGES];
+ Pager* pager;
uint32_t num_rows;
} Table;
我把 new_table() 方法重命名为 db_open() 因为它现在有连接数据库的功能。意思是它可以:
- 打开数据库文件
- 初始化寻址器数据结构
- 初始化表数据结构
-Table* new_table() {
+Table* db_open(const char* filename) {
+ Pager* pager = pager_open(filename);
+ uint32_t num_rows = pager->file_length / ROW_SIZE;
+
Table* table = malloc(sizeof(Table));
- table->num_rows = 0;
+ table->pager = pager;
+ table->num_rows = num_rows;
return table;
}
db_open() 反过来调用 pager_open(),
后者可以打开数据库文件并跟踪它的大小。它还可以初始化页缓存为 NULL .
+Pager* pager_open(const char* filename) {
+ int fd = open(filename,
+ O_RDWR | // Read/Write mode
+ O_CREAT, // Create file if it does not exist
+ S_IWUSR | // User write permission
+ S_IRUSR // User read permission
+ );
+
+ if (fd == -1) {
+ printf("Unable to open file\n");
+ exit(EXIT_FAILURE);
+ }
+
+ off_t file_length = lseek(fd, 0, SEEK_END);
+
+ Pager* pager = malloc(sizeof(Pager));
+ pager->file_descriptor = fd;
+ pager->file_length = file_length;
+
+ for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
+ pager->pages[i] = NULL;
+ }
+
+ return pager;
+}
按照我们的抽象方法,我们把获取页的功能,放在了它独属的方法中:
void* row_slot(Table* table, uint32_t row_num) {
uint32_t page_num = row_num / ROWS_PER_PAGE;
- void* page = table->pages[page_num];
- if (page == NULL) {
- // Allocate memory only when we try to access page
- page = table->pages[page_num] = malloc(PAGE_SIZE);
- }
+ void* page = get_page(table->pager, page_num);
uint32_t row_offset = row_num % ROWS_PER_PAGE;
uint32_t byte_offset = row_offset * ROW_SIZE;
return page + byte_offset;
}
get_page() 方法实现了处理缺少页缓存情况的逻辑。我们假设页被一个一个地保存在数据库文件中: 页0在偏移为0的位置,页1在偏移为4096的位置,页2在偏移为8192的位置,以此类推。如果请求的页位于文件的边界外,我们知道它应该是空白的,所以我们只需要分配以下内存并返回它。页会在我们合并缓存时被写入数据库文件。
+void* get_page(Pager* pager, uint32_t page_num) {
+ if (page_num > TABLE_MAX_PAGES) {
+ printf("Tried to fetch page number out of bounds. %d > %d\n", page_num,
+ TABLE_MAX_PAGES);
+ exit(EXIT_FAILURE);
+ }
+
+ if (pager->pages[page_num] == NULL) {
+ // Cache miss. Allocate memory and load from file.
+ void* page = malloc(PAGE_SIZE);
+ uint32_t num_pages = pager->file_length / PAGE_SIZE;
+
+ // We might save a partial page at the end of the file
+ if (pager->file_length % PAGE_SIZE) {
+ num_pages += 1;
+ }
+
+ if (page_num <= num_pages) {
+ lseek(pager->file_descriptor, page_num * PAGE_SIZE, SEEK_SET);
+ ssize_t bytes_read = read(pager->file_descriptor, page, PAGE_SIZE);
+ if (bytes_read == -1) {
+ printf("Error reading file: %d\n", errno);
+ exit(EXIT_FAILURE);
+ }
+ }
+
+ pager->pages[page_num] = page;
+ }
+
+ return pager->pages[page_num];
+}
现在,我们将等待缓存合并到硬盘直到用户关闭与数据库的连接。当用户退出时,我们将调用一个新的方法 db_close() :
- 将页缓存写入磁盘
- 关闭数据库文件
- 释放寻址器数据结构和表数据结构占用的内存
+void db_close(Table* table) {
+ Pager* pager = table->pager;
+ uint32_t num_full_pages = table->num_rows / ROWS_PER_PAGE;
+
+ for (uint32_t i = 0; i < num_full_pages; i++) {
+ if (pager->pages[i] == NULL) {
+ continue;
+ }
+ pager_flush(pager, i, PAGE_SIZE);
+ free(pager->pages[i]);
+ pager->pages[i] = NULL;
+ }
+
+ // There may be a partial page to write to the end of the file
+ // This should not be needed after we switch to a B-tree
+ uint32_t num_additional_rows = table->num_rows % ROWS_PER_PAGE;
+ if (num_additional_rows > 0) {
+ uint32_t page_num = num_full_pages;
+ if (pager->pages[page_num] != NULL) {
+ pager_flush(pager, page_num, num_additional_rows * ROW_SIZE);
+ free(pager->pages[page_num]);
+ pager->pages[page_num] = NULL;
+ }
+ }
+
+ int result = close(pager->file_descriptor);
+ if (result == -1) {
+ printf("Error closing db file.\n");
+ exit(EXIT_FAILURE);
+ }
+ for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
+ void* page = pager->pages[i];
+ if (page) {
+ free(page);
+ pager->pages[i] = NULL;
+ }
+ }
+ free(pager);
+ free(table);
+}
+
-MetaCommandResult do_meta_command(InputBuffer* input_buffer) {
+MetaCommandResult do_meta_command(InputBuffer* input_buffer, Table* table) {
if (strcmp(input_buffer->buffer, ".exit") == 0) {
+ db_close(table);
exit(EXIT_SUCCESS);
} else {
return META_COMMAND_UNRECOGNIZED_COMMAND;
在我们现在的设计中,文件的长度编码了数据库的行数,所以我们需要在文件末尾写入部分页面。这就是 pager_flush 同时需要页的数量和大小的原因。这不是最伟大的设计,但当我们开始实现B树时,它就会很快地消失。
+void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {
+ if (pager->pages[page_num] == NULL) {
+ printf("Tried to flush null page\n");
+ exit(EXIT_FAILURE);
+ }
+
+ off_t offset = lseek(pager->file_descriptor, page_num * PAGE_SIZE, SEEK_SET);
+
+ if (offset == -1) {
+ printf("Error seeking: %d\n", errno);
+ exit(EXIT_FAILURE);
+ }
+
+ ssize_t bytes_written =
+ write(pager->file_descriptor, pager->pages[page_num], size);
+
+ if (bytes_written == -1) {
+ printf("Error writing: %d\n", errno);
+ exit(EXIT_FAILURE);
+ }
+}
最后,我们需要接受文件名作为命令行参数。不要忘记加入在 do_meta_command 中添加额外参数:
int main(int argc, char* argv[]) {
- Table* table = new_table();
+ if (argc < 2) {
+ printf("Must supply a database filename.\n");
+ exit(EXIT_FAILURE);
+ }
+
+ char* filename = argv[1];
+ Table* table = db_open(filename);
+
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
read_input(input_buffer);
if (input_buffer->buffer[0] == '.') {
- switch (do_meta_command(input_buffer)) {
+ switch (do_meta_command(input_buffer, table)) {
有了这些更改,我们现在可以关闭然后重新打开数据库,并保证我们的记录仍然存在。
~ ./db mydb.db
db > insert 1 cstack foo@bar.com
Executed.
db > insert 2 voltorb volty@example.com
Executed.
db > .exit
~
~ ./db mydb.db
db > select
(1, cstack, foo@bar.com)
(2, voltorb, volty@example.com)
Executed.
db > .exit
~
为了获得额外的乐趣,让我们打开 mydb.db 看看数据是如何存储的。我将使用vim作为十六进制编辑器查看文件的内存布局:
vim mydb.db
:%!xxd
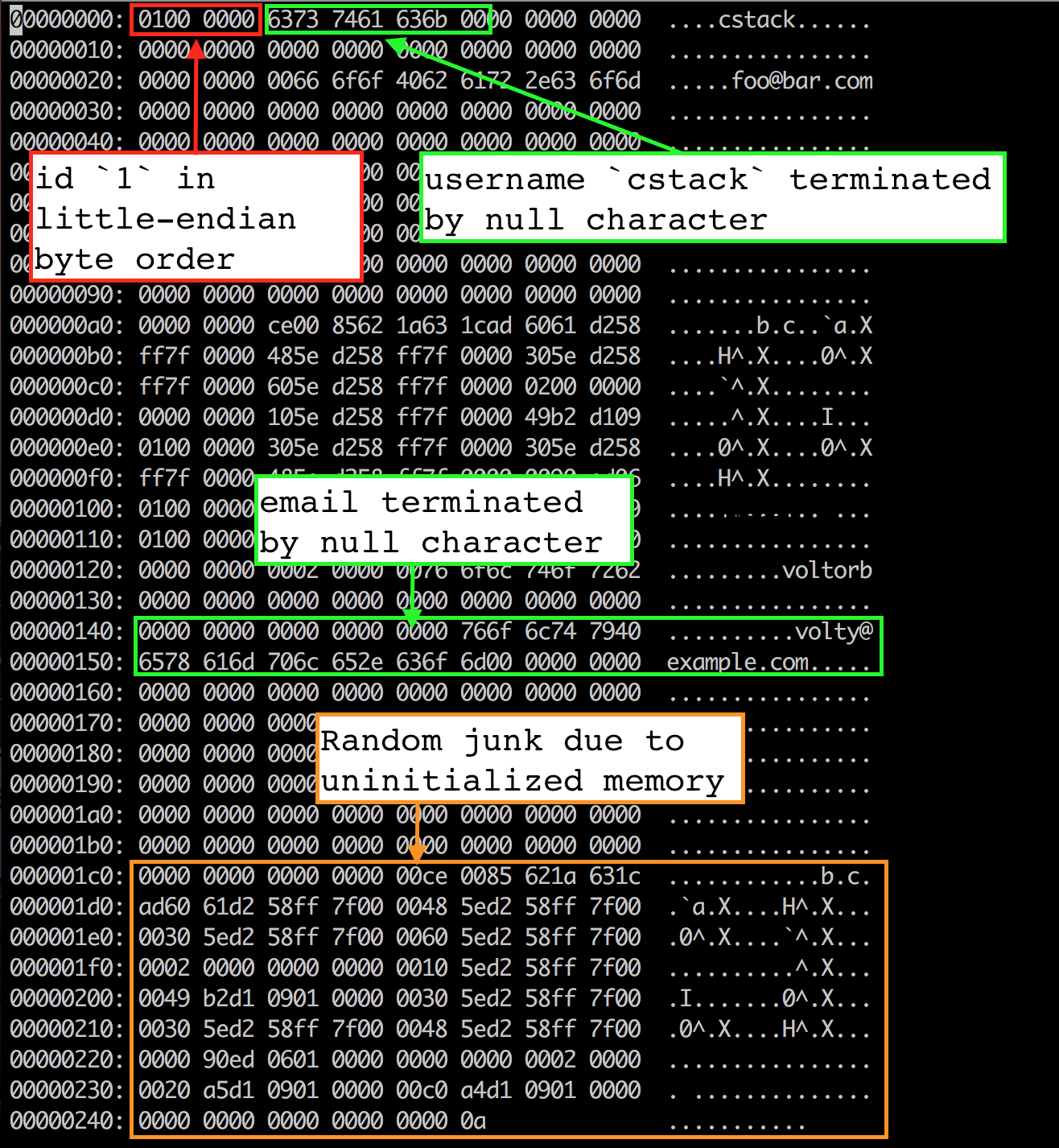
前4个字节是第一行的id(四个字节是因为以 uint32_t 数据结构存储的)。它采用低位编址,所以最低有效字节排在第一位(01),然后是高阶字节(00 00 00)。我们使用 memcpy() 将字节从行结构复制到页缓存中,这意味着该结构以小端字节顺序放置在内存中。这是我用来编译程序的机器的一个属性。如果我们想在我的机器上写入一个数据库文件,然后在高位编址的及其上读取,我们必须修改 serialize_row() 和 deserialize_row() ,使它们以同样的顺序存储和读取字节。
接下来的33个字节将用户名存储为一个以空字符结尾的字符串。显然,ASCII十六进制中的 cstack 是 63 73 74 61 63 6b,后跟一个空字符(00) 。其余的33个字节未使用。
再然后的256个字符以同样的方式存储了邮件地址。在这里我们可以看到终止空字符后的一些随机垃圾。这很可能是我们在行结构中未初始化的内存空间。在操作中我们直接把256字节的邮件地址从缓冲区复制到文件中,这部分字节包括了任何在终止空字符后的字节。但由于我们使用终止空字符,因此它对我们的行为没有影响。
注意: 如果我们想要确保所有字节都被初始化,在序列化行时复制用户名和邮箱的操作应该使用 strncpy 而不是 memcpy,就像这样:
void serialize_row(Row* source, void* destination) {
memcpy(destination + ID_OFFSET, &(source->id), ID_SIZE);
- memcpy(destination + USERNAME_OFFSET, &(source->username), USERNAME_SIZE);
- memcpy(destination + EMAIL_OFFSET, &(source->email), EMAIL_SIZE);
+ strncpy(destination + USERNAME_OFFSET, source->username, USERNAME_SIZE);
+ strncpy(destination + EMAIL_OFFSET, source->email, EMAIL_SIZE);
}
Conclusion
好了!我们现在已经拥有了持久储存数据的能力。当然这并不是最好的。例如,如果你在不输入 .exit 的情况下终止程序,更改同样会丢失。另外,我们会把所有页从内存写入磁盘,即便该页相比磁盘中的版本并没有任何更改。这些问题我们稍后就可以解决。
下一次我们将介绍游标,这会使实现B树变得更加容易。
Complete Diff
+#include <errno.h>
+#include <fcntl.h>
#include <stdbool.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdint.h>
+#include <unistd.h>
struct InputBuffer_t {
char* buffer;
@@ -62,9 +65,16 @@ const uint32_t PAGE_SIZE = 4096;
const uint32_t ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE;
const uint32_t TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES;
+typedef struct {
+ int file_descriptor;
+ uint32_t file_length;
+ void* pages[TABLE_MAX_PAGES];
+} Pager;
+
typedef struct {
uint32_t num_rows;
- void* pages[TABLE_MAX_PAGES];
+ Pager* pager;
} Table;
@@ -84,32 +94,81 @@ void deserialize_row(void *source, Row* destination) {
memcpy(&(destination->email), source + EMAIL_OFFSET, EMAIL_SIZE);
}
+void* get_page(Pager* pager, uint32_t page_num) {
+ if (page_num > TABLE_MAX_PAGES) {
+ printf("Tried to fetch page number out of bounds. %d > %d\n", page_num,
+ TABLE_MAX_PAGES);
+ exit(EXIT_FAILURE);
+ }
+
+ if (pager->pages[page_num] == NULL) {
+ // Cache miss. Allocate memory and load from file.
+ void* page = malloc(PAGE_SIZE);
+ uint32_t num_pages = pager->file_length / PAGE_SIZE;
+
+ // We might save a partial page at the end of the file
+ if (pager->file_length % PAGE_SIZE) {
+ num_pages += 1;
+ }
+
+ if (page_num <= num_pages) {
+ lseek(pager->file_descriptor, page_num * PAGE_SIZE, SEEK_SET);
+ ssize_t bytes_read = read(pager->file_descriptor, page, PAGE_SIZE);
+ if (bytes_read == -1) {
+ printf("Error reading file: %d\n", errno);
+ exit(EXIT_FAILURE);
+ }
+ }
+
+ pager->pages[page_num] = page;
+ }
+
+ return pager->pages[page_num];
+}
+
void* row_slot(Table* table, uint32_t row_num) {
uint32_t page_num = row_num / ROWS_PER_PAGE;
- void *page = table->pages[page_num];
- if (page == NULL) {
- // Allocate memory only when we try to access page
- page = table->pages[page_num] = malloc(PAGE_SIZE);
- }
+ void *page = get_page(table->pager, page_num);
uint32_t row_offset = row_num % ROWS_PER_PAGE;
uint32_t byte_offset = row_offset * ROW_SIZE;
return page + byte_offset;
}
-Table* new_table() {
- Table* table = malloc(sizeof(Table));
- table->num_rows = 0;
+Pager* pager_open(const char* filename) {
+ int fd = open(filename,
+ O_RDWR | // Read/Write mode
+ O_CREAT, // Create file if it does not exist
+ S_IWUSR | // User write permission
+ S_IRUSR // User read permission
+ );
+
+ if (fd == -1) {
+ printf("Unable to open file\n");
+ exit(EXIT_FAILURE);
+ }
+
+ off_t file_length = lseek(fd, 0, SEEK_END);
+
+ Pager* pager = malloc(sizeof(Pager));
+ pager->file_descriptor = fd;
+ pager->file_length = file_length;
+
for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
- table->pages[i] = NULL;
+ pager->pages[i] = NULL;
}
- return table;
+
+ return pager;
}
-void free_table(Table* table) {
- for (int i = 0; table->pages[i]; i++) {
- free(table->pages[i]);
- }
- free(table);
+Table* db_open(const char* filename) {
+ Pager* pager = pager_open(filename);
+ uint32_t num_rows = pager->file_length / ROW_SIZE;
+
+ Table* table = malloc(sizeof(Table));
+ table->pager = pager;
+ table->num_rows = num_rows;
+
+ return table;
}
InputBuffer* new_input_buffer() {
@@ -142,10 +201,76 @@ void close_input_buffer(InputBuffer* input_buffer) {
free(input_buffer);
}
+void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {
+ if (pager->pages[page_num] == NULL) {
+ printf("Tried to flush null page\n");
+ exit(EXIT_FAILURE);
+ }
+
+ off_t offset = lseek(pager->file_descriptor, page_num * PAGE_SIZE,
+ SEEK_SET);
+
+ if (offset == -1) {
+ printf("Error seeking: %d\n", errno);
+ exit(EXIT_FAILURE);
+ }
+
+ ssize_t bytes_written = write(
+ pager->file_descriptor, pager->pages[page_num], size
+ );
+
+ if (bytes_written == -1) {
+ printf("Error writing: %d\n", errno);
+ exit(EXIT_FAILURE);
+ }
+}
+
+void db_close(Table* table) {
+ Pager* pager = table->pager;
+ uint32_t num_full_pages = table->num_rows / ROWS_PER_PAGE;
+
+ for (uint32_t i = 0; i < num_full_pages; i++) {
+ if (pager->pages[i] == NULL) {
+ continue;
+ }
+ pager_flush(pager, i, PAGE_SIZE);
+ free(pager->pages[i]);
+ pager->pages[i] = NULL;
+ }
+
+ // There may be a partial page to write to the end of the file
+ // This should not be needed after we switch to a B-tree
+ uint32_t num_additional_rows = table->num_rows % ROWS_PER_PAGE;
+ if (num_additional_rows > 0) {
+ uint32_t page_num = num_full_pages;
+ if (pager->pages[page_num] != NULL) {
+ pager_flush(pager, page_num, num_additional_rows * ROW_SIZE);
+ free(pager->pages[page_num]);
+ pager->pages[page_num] = NULL;
+ }
+ }
+
+ int result = close(pager->file_descriptor);
+ if (result == -1) {
+ printf("Error closing db file.\n");
+ exit(EXIT_FAILURE);
+ }
+ for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
+ void* page = pager->pages[i];
+ if (page) {
+ free(page);
+ pager->pages[i] = NULL;
+ }
+ }
+
+ free(pager);
+ free(table);
+}
+
MetaCommandResult do_meta_command(InputBuffer* input_buffer, Table *table) {
if (strcmp(input_buffer->buffer, ".exit") == 0) {
close_input_buffer(input_buffer);
- free_table(table);
+ db_close(table);
exit(EXIT_SUCCESS);
} else {
return META_COMMAND_UNRECOGNIZED_COMMAND;
@@ -182,6 +308,7 @@ PrepareResult prepare_insert(InputBuffer* input_buffer, Statement* statement) {
return PREPARE_SUCCESS;
}
+
PrepareResult prepare_statement(InputBuffer* input_buffer,
Statement* statement) {
if (strncmp(input_buffer->buffer, "insert", 6) == 0) {
@@ -227,7 +354,14 @@ ExecuteResult execute_statement(Statement* statement, Table *table) {
}
int main(int argc, char* argv[]) {
- Table* table = new_table();
+ if (argc < 2) {
+ printf("Must supply a database filename.\n");
+ exit(EXIT_FAILURE);
+ }
+
+ char* filename = argv[1];
+ Table* table = db_open(filename);
+
InputBuffer* input_buffer = new_input_buffer();
while (true) {
print_prompt();
还有测试程序的修改
describe 'database' do
+ before do
+ `rm -rf test.db`
+ end
+
def run_script(commands)
raw_output = nil
- IO.popen("./db", "r+") do |pipe|
+ IO.popen("./db test.db", "r+") do |pipe|
commands.each do |command|
pipe.puts command
end
@@ -28,6 +32,27 @@ describe 'database' do
])
end
+ it 'keeps data after closing connection' do
+ result1 = run_script([
+ "insert 1 user1 person1@example.com",
+ ".exit",
+ ])
+ expect(result1).to match_array([
+ "db > Executed.",
+ "db > ",
+ ])
+
+ result2 = run_script([
+ "select",
+ ".exit",
+ ])
+ expect(result2).to match_array([
+ "db > (1, user1, person1@example.com)",
+ "Executed.",
+ "db > ",
+ ])
+ end
+
it 'prints error message when table is full' do
script = (1..1401).map do |i|
"insert #{i} user#{i} person#{i}@example.com"















 1743
1743











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









