









1,关于PySpider工具
http://www.oschina.net/p/pyspider
使用 Python 编写脚本,提供强大的 API
Python 2&3
强大的 WebUI 和脚本编辑器、任务监控和项目管理和结果查看
支持 JavaScript 页面
后端系统支持:MySQL, MongoDB, SQLite, Postgresql
支持任务优先级、重试、定期抓取等
分布式架构
2,Mac下安装
sudo pip install pyspider
#启动直接输入
pyspider在本机开了5000端口:http://localhost:5000
本机访问页面:
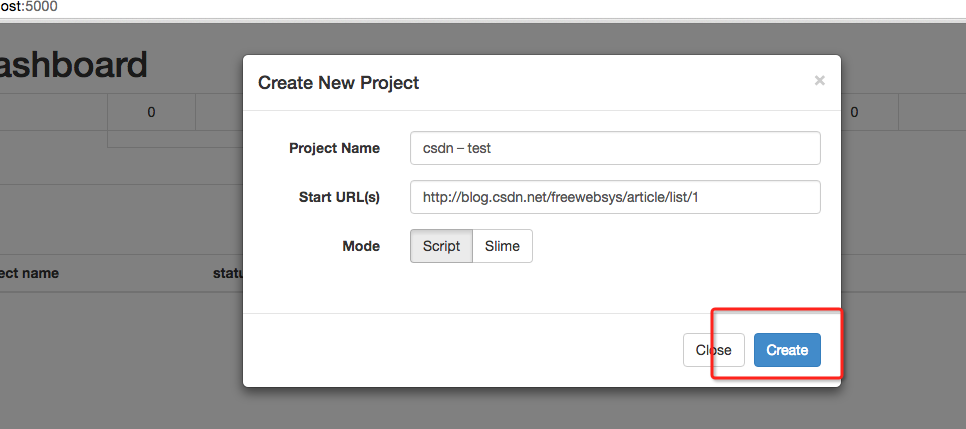
创建一个项目,我要爬自己的csdn博客。
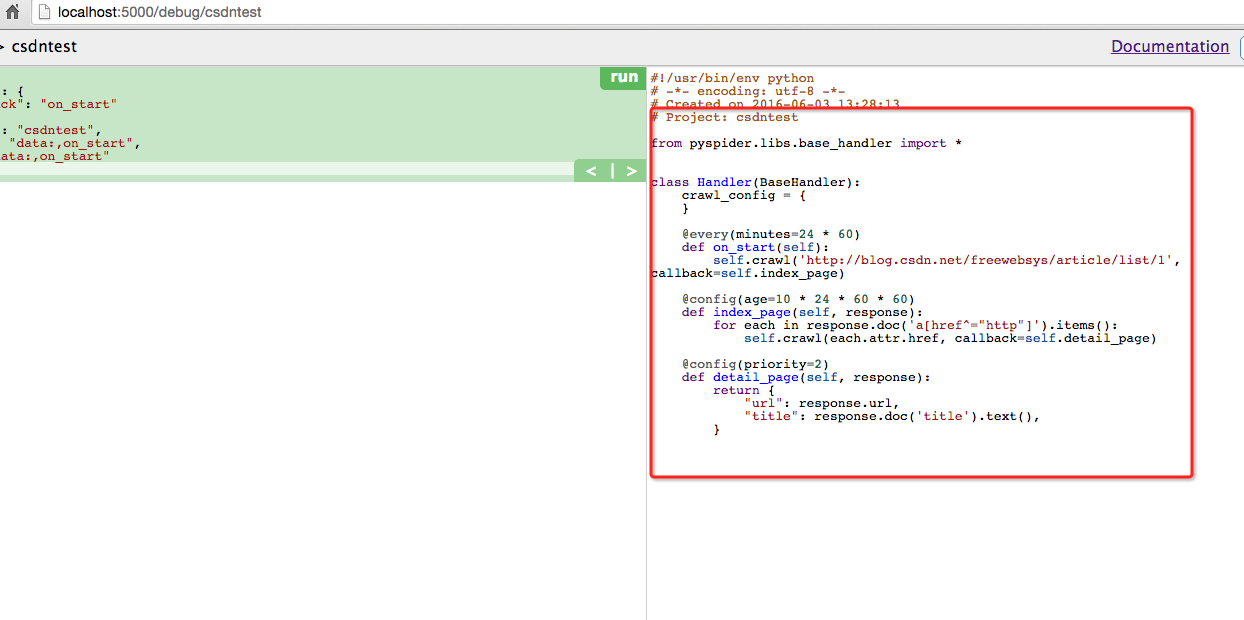
进入编辑页面,可以在web端直接修改代码。保存,然后运行。
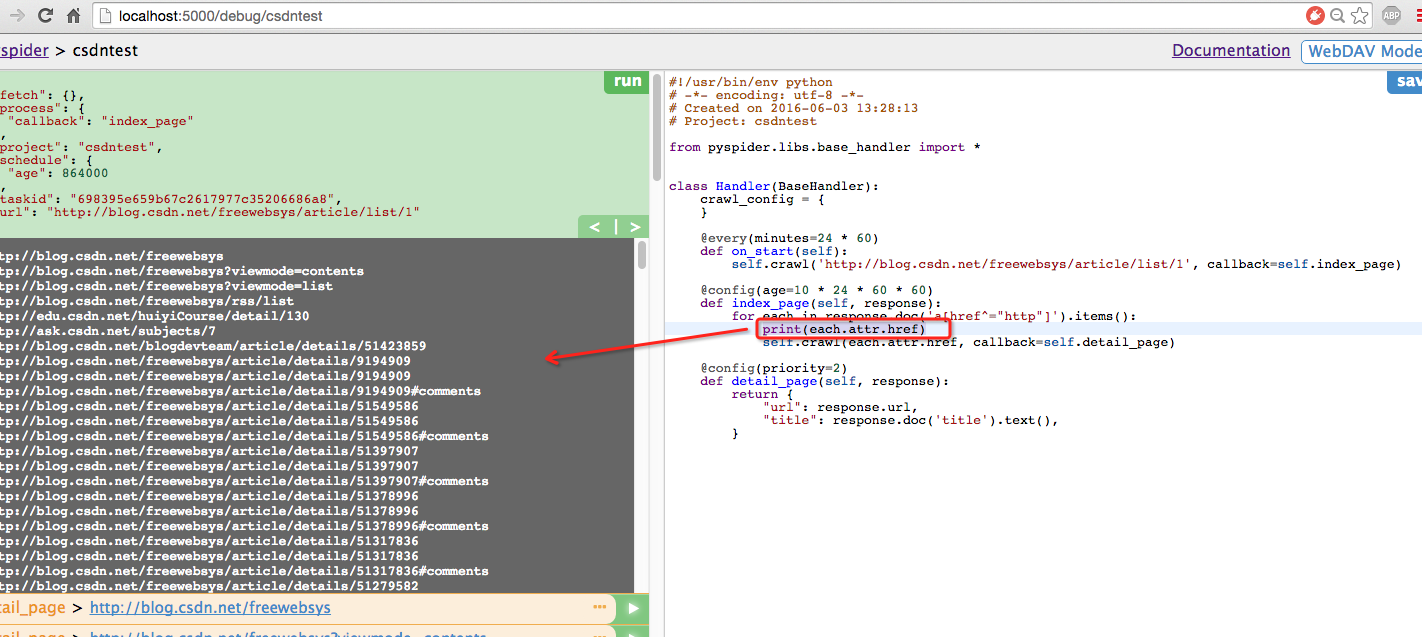
和python一样,并且可以进行print打印日志,也直接输出到页面上了。
做的好神奇,是个很精简的ide开发工具了,同时还有语法高亮显示。
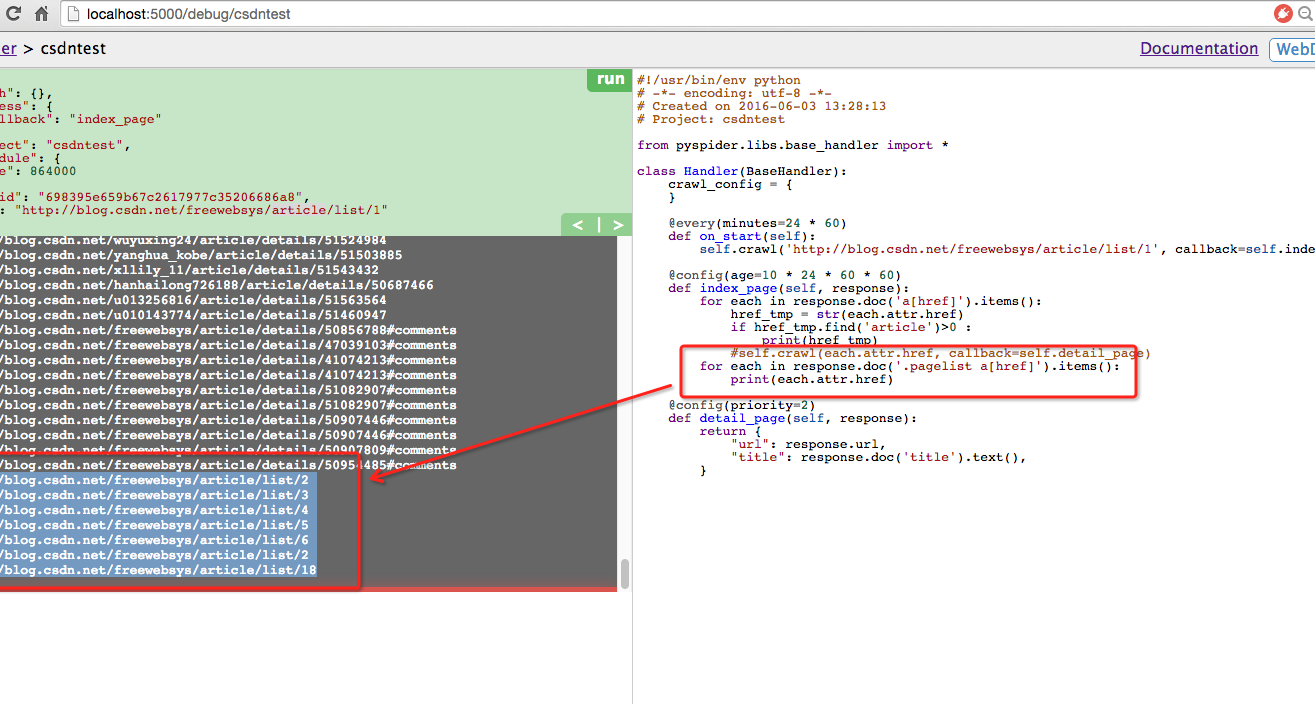
返回doc对象,可以将访问html里面的对象内容。
类似于jquery语法,可以按照id,class 查找链接。
比如我要查找底部的分页链接直接写
response.doc(‘.pagelist a[href]’).items() 就可以获得items数据。然后在进行循环。
更多的html css 选择器参考:
http://docs.pyspider.org/en/latest/tutorial/HTML-and-CSS-Selector/
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2016-06-03 13:28:13
# Project: csdntest
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every(minutes=24 * 60)
def on_start(self):
self.crawl('http://blog.csdn.net/freewebsys/article/list/1', callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc('a[href]').items():
href_tmp = str(each.attr.href)
if href_tmp.find('article')>0 :
print(href_tmp)
self.crawl(each.attr.href, callback=self.detail_page)
for each in response.doc('.pagelist a[href]').items():
print(each.attr.href)
#循环调用。
self.crawl(each.attr.href, callback=self.index_page)
@config(priority=2)
def detail_page(self, response):
return {
"url": response.url,
"title": response.doc('title').text(),
}
首先入口是on_start函数,执行完成之后调回调函数index_page ,
在回调函数里面查找a链接,再继续往下爬数据。
3,主要api函数
http://docs.pyspider.org/en/latest/apis/
主要是分析 Response 这个类的返回结果,然后再进行抓取数据。
剩下的就是写python代码的问题了。
4,总结
PySpider 是非常好用的工具,使用python非常喜欢,简单高效。
而去有个web大图形界面显示,可以直接在浏览器里面编写,调试代码。
最厉害大地方就是工具可以抓取js渲染后的代码,比如百度搜索的结果,ajax渲染后的结果。
本文的原文连接是: http://blog.csdn.net/freewebsys/article/details/51582451 未经博主允许不得转载。
博主地址是:http://blog.csdn.net/freewebsys















 375
375











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









