







kaggle比赛案例1:Elo Merchant Category Recommendation
学习深度学习之前,机器学习也是不可少的一个基础,鉴于没有时间写一个个经典的机器学习模型,这里我就写一个kaggle比赛案例,以此来回顾一下机器学习的内容。
之所以使用这个案例是因为,一是这个案例是真实场景的案例,当时有大约四千多个参赛者,奖金池也高达5万美元,属于算法竞赛中的大型赛事,所以值得复现;二是目前网上有很多人分享了很多关于这个案例的心得和总结,这样我们就会有一个baseline,在实际动手过程中不会太迷茫。整个案例写下来,内容也是超多,都有一种录制视频的冲动,因为码字毕竟没有口述更清晰和高效嘛。
Elo Merchant Category Recommendation | Kaggle
Elo Merchant Category Recommendation | Kaggle
14.特征工程通用组合特征代码实现_哔哩哔哩_bilibili
一、数据获取
获取数据有如下3种方式:
其中,方法2和方法3都是点击下载。方法1是使用kaggle命令下载,推荐使用这种方式,因为以后也可以用这种方式提交你的模型结果。但是要安装kaggle,具体步骤如下: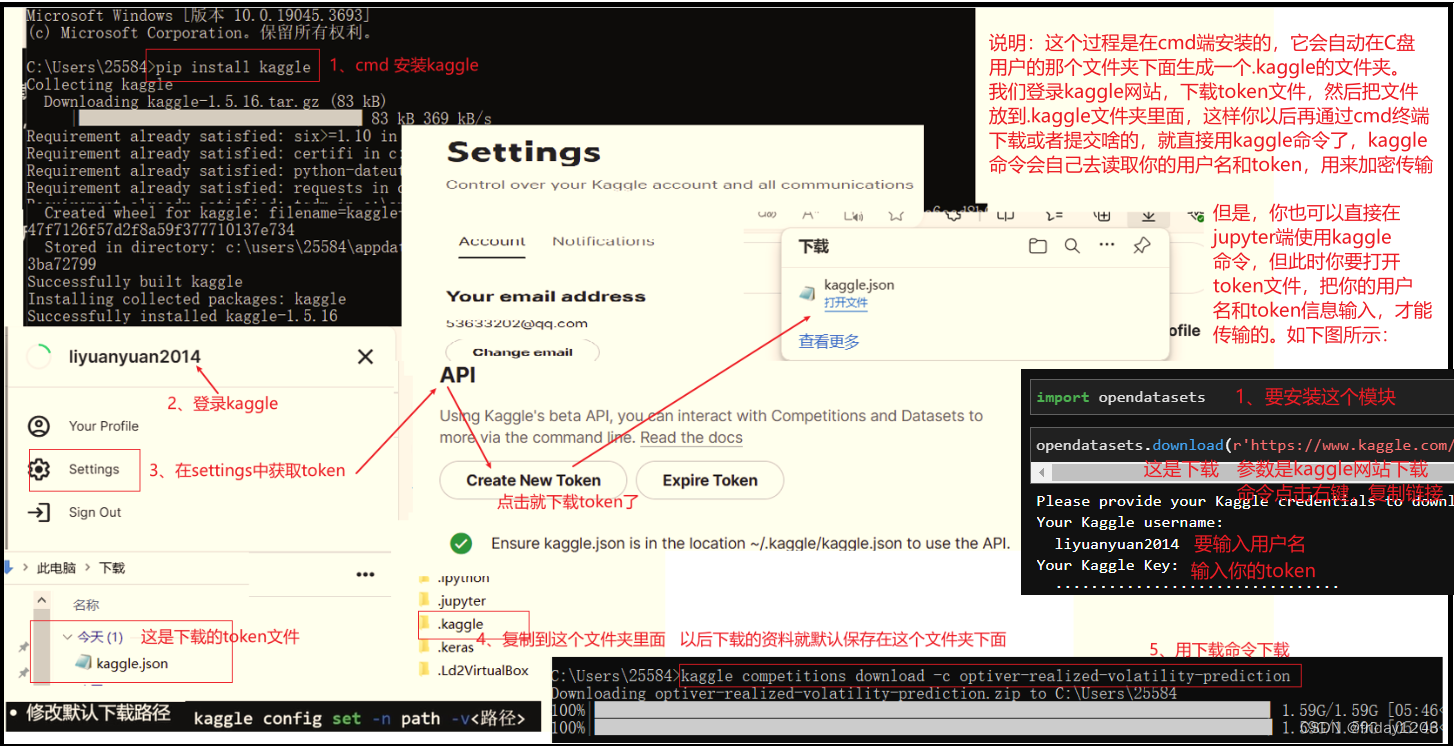
小结:
这里有非常多坑,但百度基本都能解决。坑1:注册kaggle会员时,要给浏览器安装一个插件Head Editor,这个插件可以使注册kaggle时的验证码显示出来,才能顺利注册。坑2:即使你各个环节都没有问题,还有可能是你家的网络不行,此时没有别的办法,只能换一个网络试试。
二、数据解读
本步骤主要是看看都有哪些文件,看看说明文档,看看kgggle让提交的结果文档的结构,大致看看训练集和测试集的数据,确认建模任务。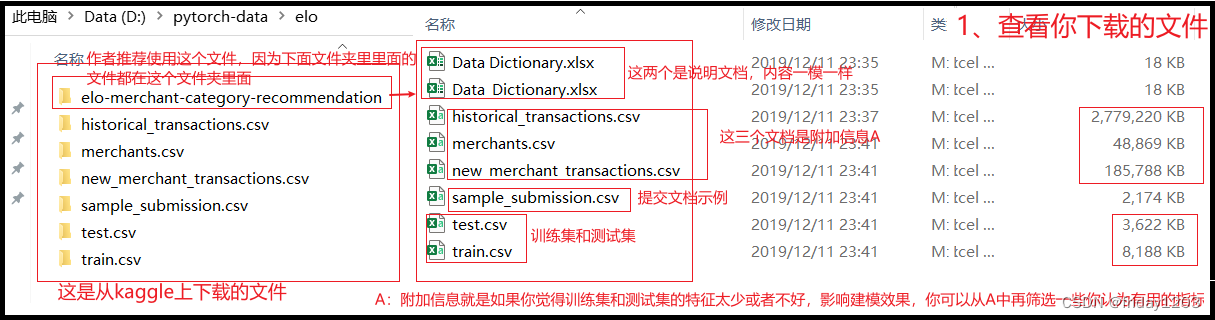
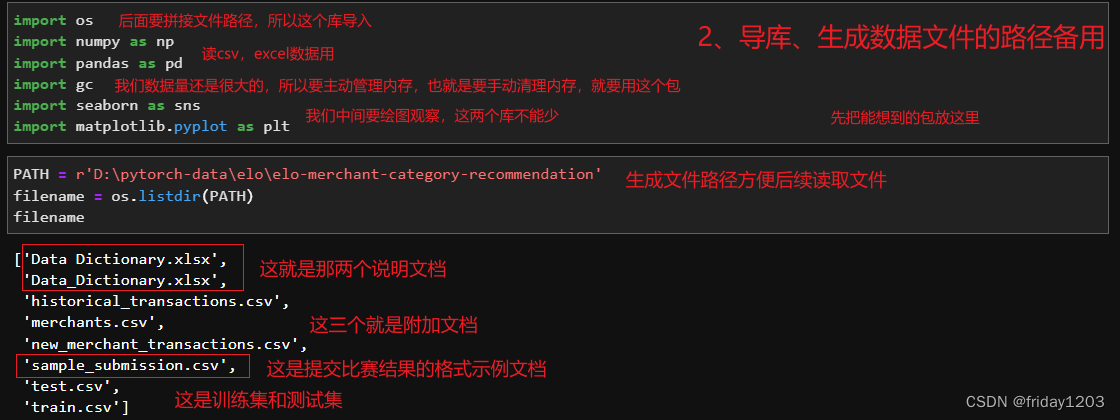
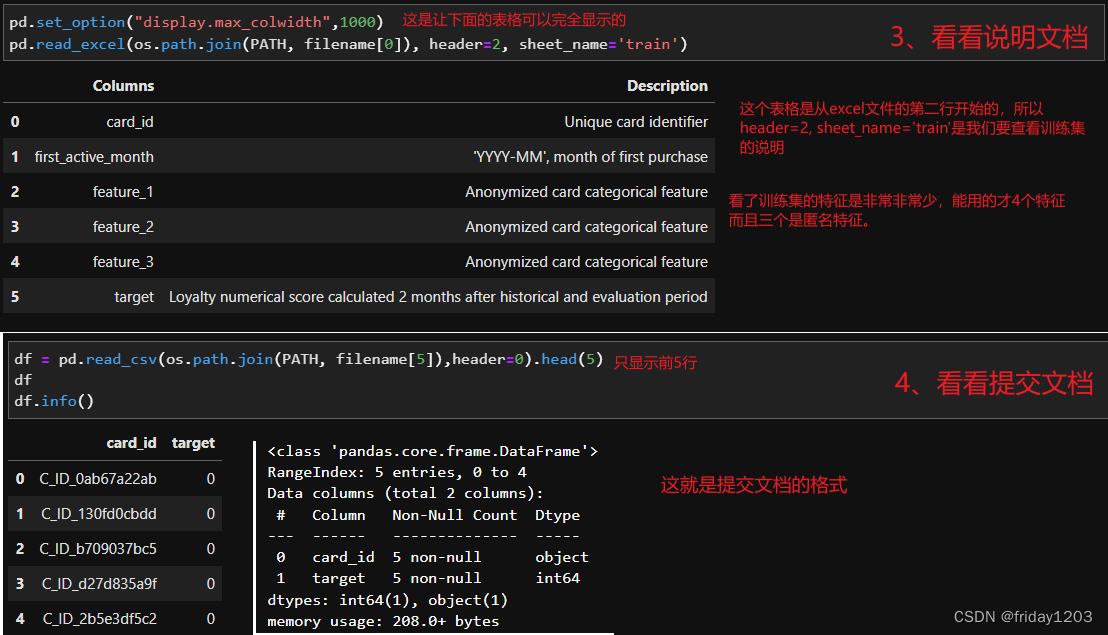
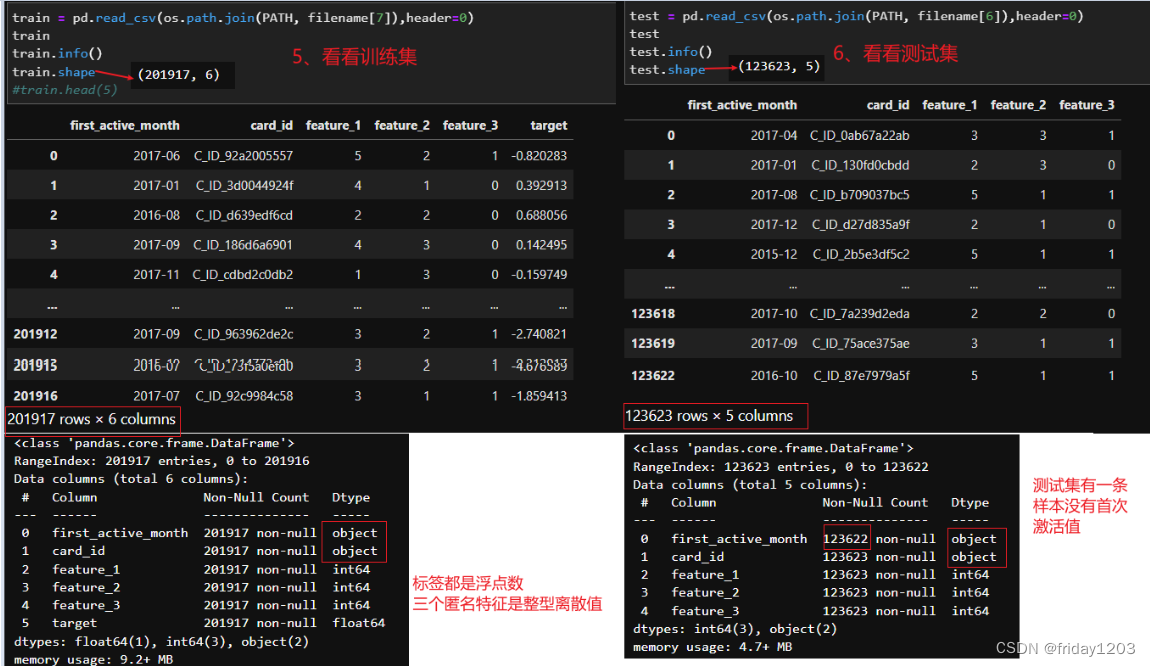
小结:
训练集中的card_id是信用卡的卡号,这里我们推断卡号应该是唯一的(后面需要进一步确认),是该样本的标识,所以card_id不能作为特征来使用。所以本案例训练集中的特征其实只有4个,其中first_active_mouth特征该卡首次被激活的年月,是日期型特征,object类型,需要处理才能带入模型训练。其他三个特征feature_1,feature_2,feature_3都是离散特征,而且都是匿名特征,就是没有业务背景,说明这三个特征是经过处理后生成的特征,就是通过某个公式得到的值,或者是涉及到卡用户隐私的特征。
训练集的标签是一个连续性的标签,是card_id(就是每张信用卡,或者说每个卡用户)的评分,这个评分是根据历史和评估期2个月后计算出来的(loyalty numerical score calculated 2 months after historical and evaluation period),这个说明非常模糊。暂时也不知道它的含义,只能后面继续深入探索。
小结:该项目训练集样本量还可以,但是特征太少,很明显后期要用到其他表中的信息。所以需要很高的特征工程技巧。从标签上看,本项目本质上是一个回归问题。所以建模方向就是建一个回归类模型。就是本案例就是一个回归模型,和项目的名称商品推荐(Merchant Category Recommendation)截至目前看不到有什么联系。
三、数据探索
数据探索就是对数据的正确性、缺失值、异常值、重复值、以及数据的统计特征的查看和分析。一般从下面两个方面进行探索:
一是,分析数据质量,也就是分析数据的正确性、缺失值、异常值、重复值。比如看训练集的测试集的样本id是不是不重复?如果重复要单独拎出来看怎么处理。看看有没有缺失值,大面积缺失值是要采取手段填充的。看看数据是否有异常值,确认异常值是否是真异常,再看怎么处理。看看有没有重复的样本,把重复的样本找出来看看是什么情况,看是删除还是进行某种stick处理后再放回等等。
二是,分析数据规律,也就是分析数据的统计特征。当然统计特征非常多,但我们一般重点看看训练集和测试集的分布规律是否一致;如果是分类模型,还要重点看看样本的均衡性问题。
分析训练集和测试集分布规律一致性,就是看训练集和测试集是不是采用于同一个总体,就是看看二者的单变量分布和多变量联合分布情况。传统的统计手段有KDE分布图(核密度估计)、KS检验、甚至最简单的占比指标等都可以,但目前比较流行的检验方法是用“对抗性验证”来检验训练集和测试集的分布是否一致,具体做法是将训练集和测试集合并成一个数据集,新增一个标签列,训练集样本的标签置为0,测试集样本的标签置为1。然后重新划分新的训练集和测试集,然后跑一个二分类模型,比如LR\RF\XGBoost\LightGBM等,然后以AUC作为模型指标。如果AUC在0.5左右,说明模型无法区分原来的训练集和测试集,也就是原来的测试集和训练集分布是一致的。如果AUC比较大,说明原训练集和测试集差异比较大,分布不一致。如果二者分布有差异,就要重点考虑特征工程环节的trick了。因为不管是机器学习还是深度学习,我们的大前提就是假设训练数据和测试数据是从同一个总体中抽样出来的,就是二者服从同一个规律,这样我们模型学习训练集的规律,才能应用到测试集上进行有效预测,否则是没法预测的,不如瞎猜了。就是要求训练集和测试集的数据要受到相同规律的影响。因为数据和特征决定了机器学习项目的上限,而不同的算法只是不同程度的逼近这个上限而已。
至于样本不均衡性问题,是针对分类模型来说的,本案例是回归类问题,所以这里不展开说了,百度可以获取大量的相关信息。
1、探索train和test两张表
(1)数据质量探索
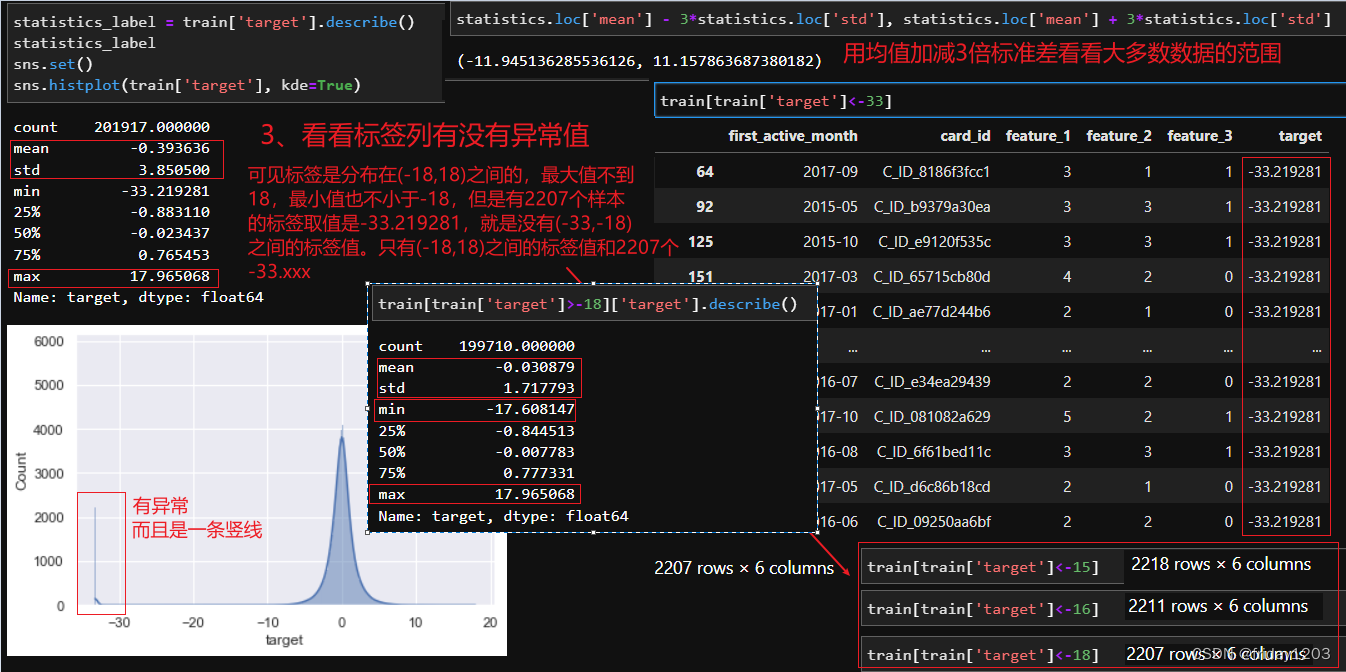
小结:
-
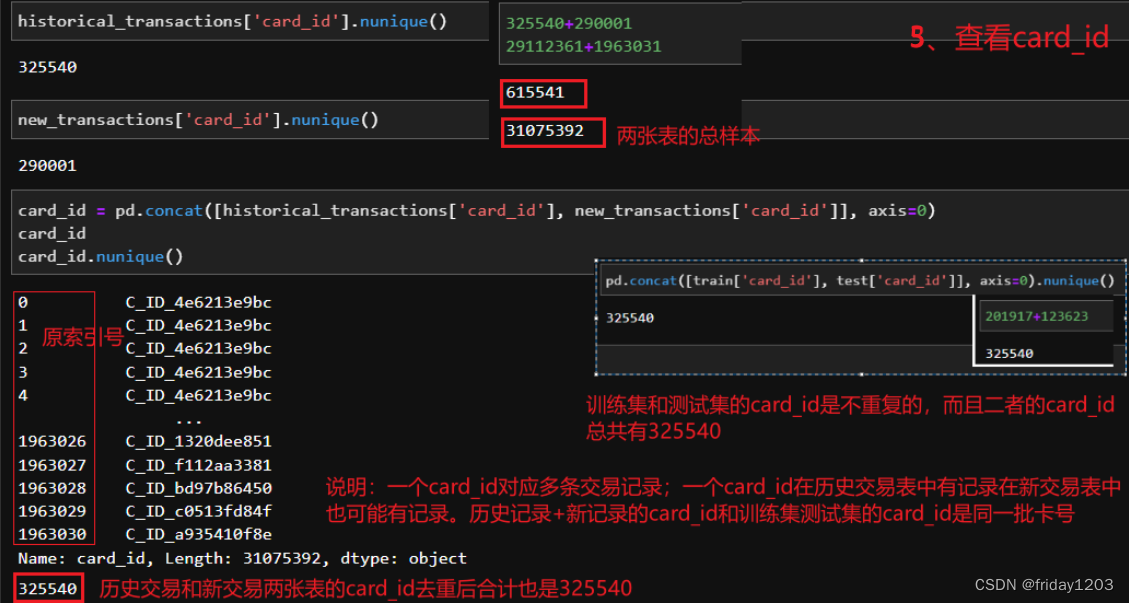
训练集和测试集的card_id都是样本的唯一标识,而且训练集的card_id和测试集的card_id直接没有重复的卡号。也就是说训练集是一批用户的数据,我们要用这批用户的数据训练一个模型,来预测其他用户的target。
-
训练集没有缺失值。但是测试集的第11578条样本的首次激活时间没有值。后续我们在特征工程中还会深入分析这条数据,这里先只要记住有一个缺失值即可。
-
再看target:训练集的标签列其实是呈正态分布的,均值几乎为0,标准差1.7左右,数据全部分布在(-18,18)之间。但是有2207个样本的标签是-33.219281,这么一个特殊的值!鉴于对这个竞赛论坛上各种讨论的挖掘,我们推断,这个数据集的标签应该是elo公司根据某个公式计算出来的。也就是这个数据集的标签不是统计值,是根据某个计算过程计算出来的。那既然是计算出来的,那结果不可能是绝大部分的是(-18,18)之间,突然又有2207个样本就等于-33.xxx。这样的计算结果只能说明这2207个样本是基于另外一套计算过程计算出来的值。说明这2207个样本还具有某些其他特殊特征,所以使用了另外一套计算公式。所以我们不能把这2207条异常样本简单的删除了事,我们得把这类样本单独视为一类,在后续建模时候单独对此类样本进行特征提取和建模分析。
此外,这些target又是和商品推荐相关的,因为本案例就是商品推荐嘛,所以我猜测计算这些target的公式中应该重点包含交易商品的信息,大概是不同商品对应不同的分值吧,这样就可以根据预处结果去推荐商品了,也就是本案例的任务和目标。
(2)数据规律探索
- 单变量分析
由于我们的四个变量都是离散型变量,所以用相对占比这个统计量来对比。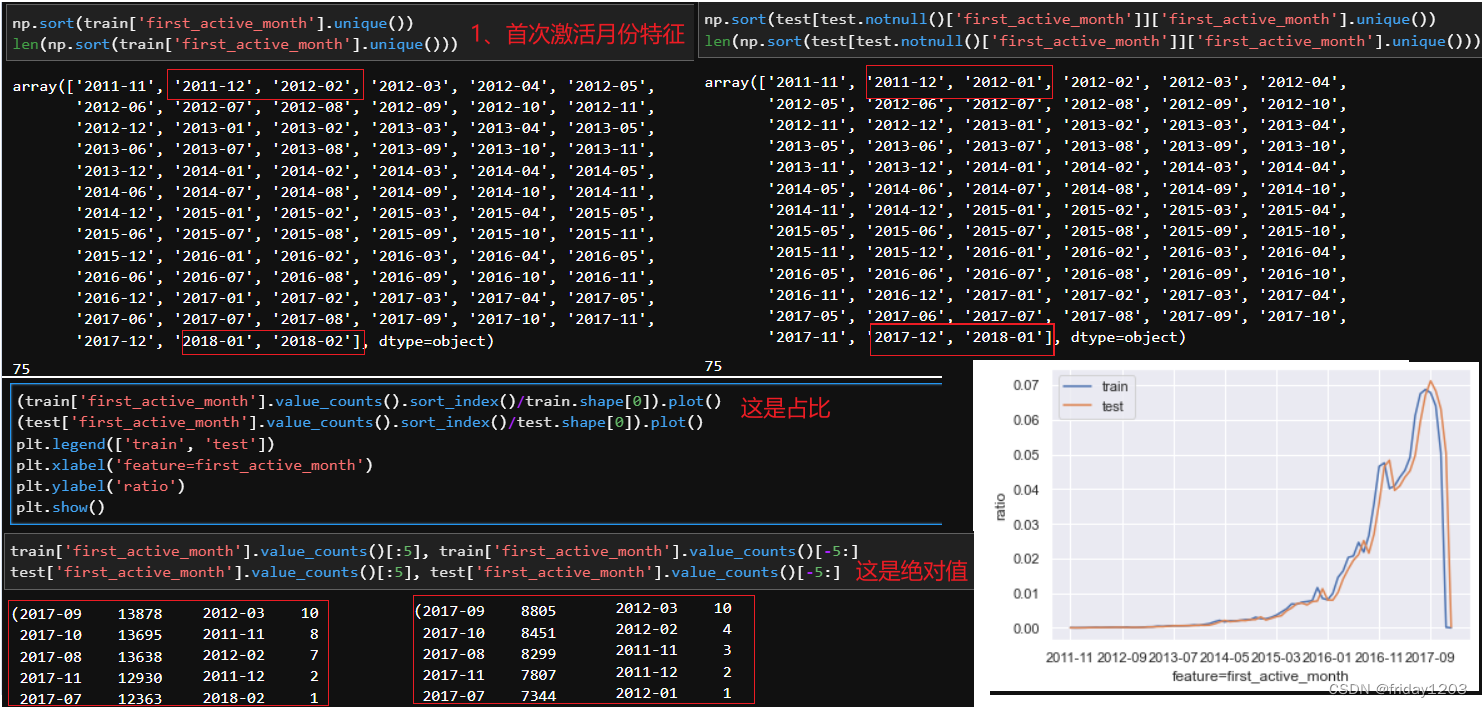
小结:
训练集和测试集的first_active_month特征,就是信用卡的首次激活时间,都是分布在75个月份中的某个月,但是只有一点点差异。训练集和测试集的每个月的激活次数占比高度一致。同时也可以看出16、17年信用卡激活的次数是出现了爆发的情况。
feature_1有5种取值(1,2,3,4,5),feature_2有3种取值(1,2,3),feature_3有2种取值(0,1)。训练集和测试集的feature_1,feature_2,feature_3的分布也是高度一致。所以从单变量看,训练集和测试集的数据分布高度一致,说明训练集和测试集的规律高度一致。所以我们可以一定把握的说,这个项目的最后得分一定很高才行,如果得分不高就是就是模型不行,需要尝试更加强大的模型。
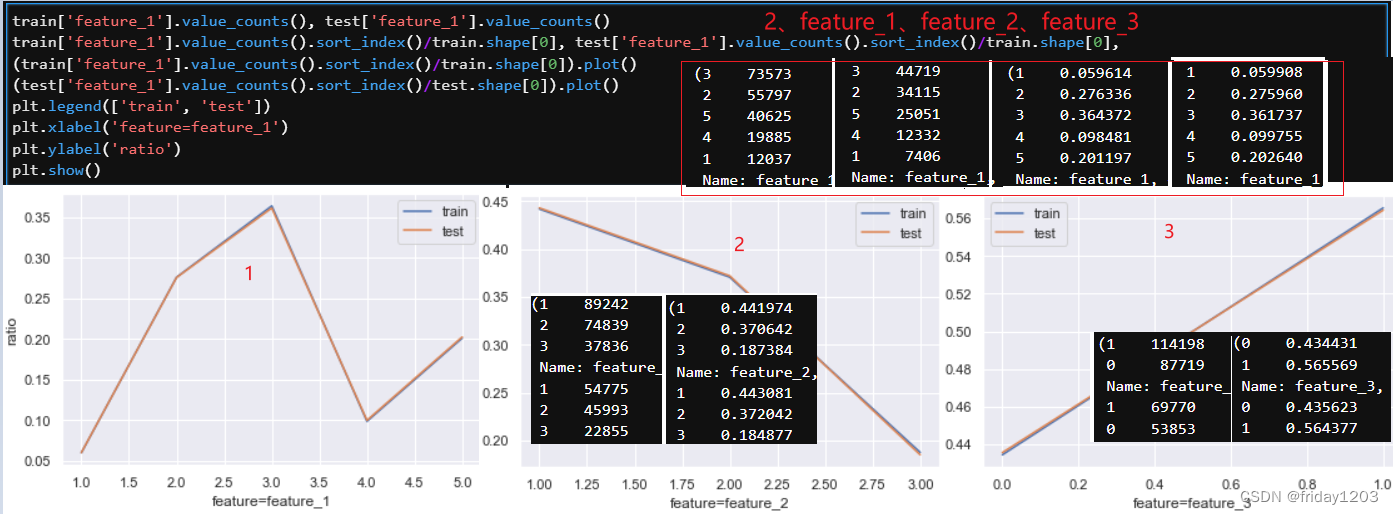
- 多变量联合分布
就是将特征两两组合,看它们的联合概率分布。我们这里的4个特征都是离散变量,所以看两两组合的时候还用相对占比这个统计量来衡量。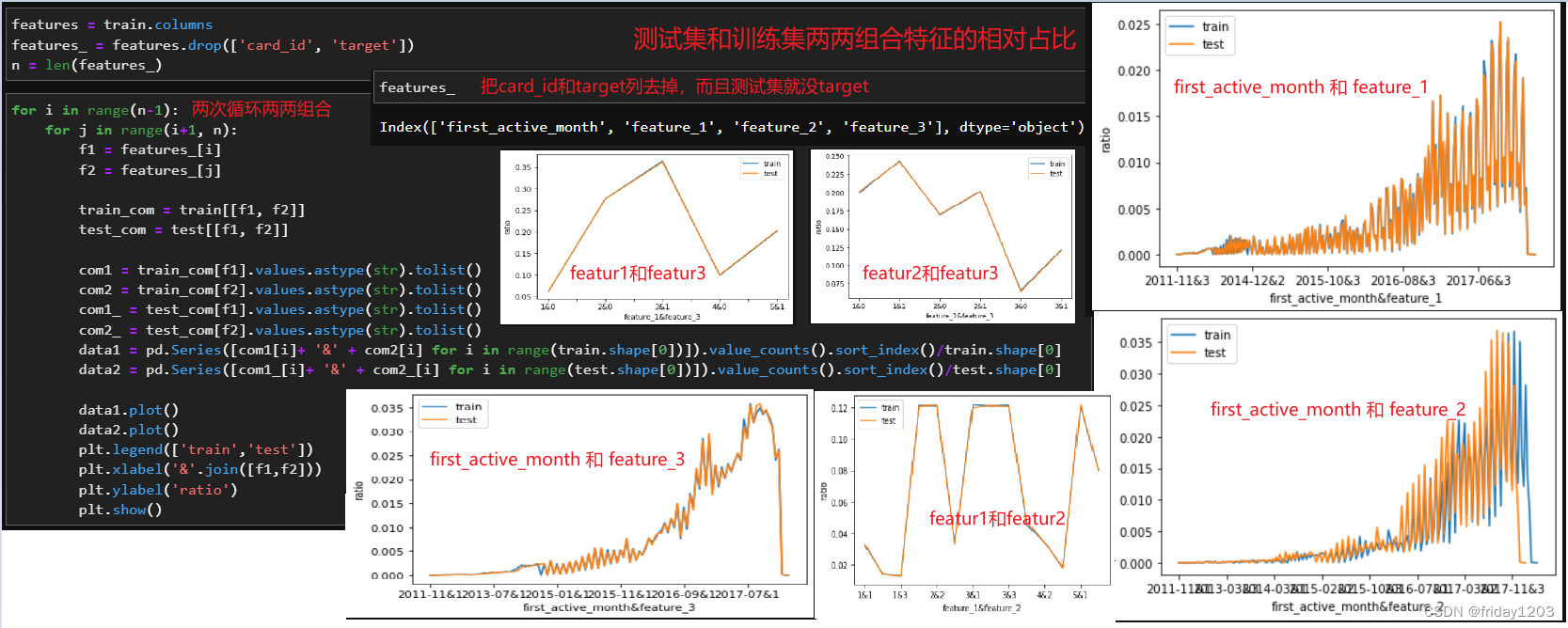
小结:
数据分布非常一致,说明我们的所有特征都取自于同一整体,就是训练集和测试集的规律高度一致。所以我们的模型上限应该比较高,所以我们建模过程中只要我们使用了很好的特征工程以及强大的模型,就应该能把模型训练到一个非常高的分值。
如果数据分布不一致,那就说明训练集和测试集的规律不太一致,那这个项目的上限就比较低,那模型训练过程中大概率会走向过拟合,测试集效果不好,此时在建模过程中就考虑使用交叉验证等方式来防止过拟合,并且除了使用通用的特征工程外,需要考虑更多的trick的使用。
2、探索historical_transaction表和new_merchant_transaction表
这两张表的列名都是一样的,所以我们放到一起探索。但是这两张表的表名一个是历史交易一个是新商户交易,从名字上看非常迷惑。而且网上很多说这两张表一个是历史交易数据,另一个是最近交易数据。其实不是的!当你把表的交易时间和card_id都拉出来看,你会发现不是的。我个人的猜测是,new_merchang_transaction表中的card_id的交易数据很可能是有异常的交易数据,当然也可能与训练集测试集中的那2207个异常样本有关,但是也可能没关系,因为前面分析target的时候,我们推断target是与不同的商品挂钩的,所以target中异常的样本也可能是特殊商品推荐吧。anyway,截至目前也仅仅是我的猜测,下面开始探索这两张表: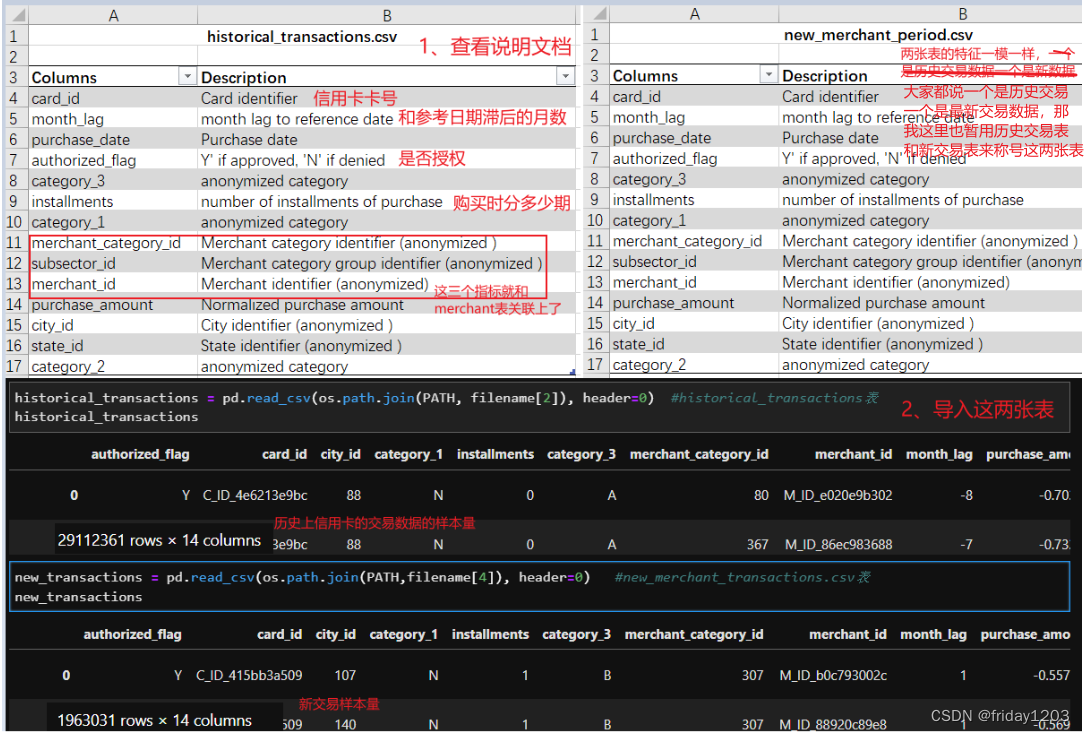


小结:
-
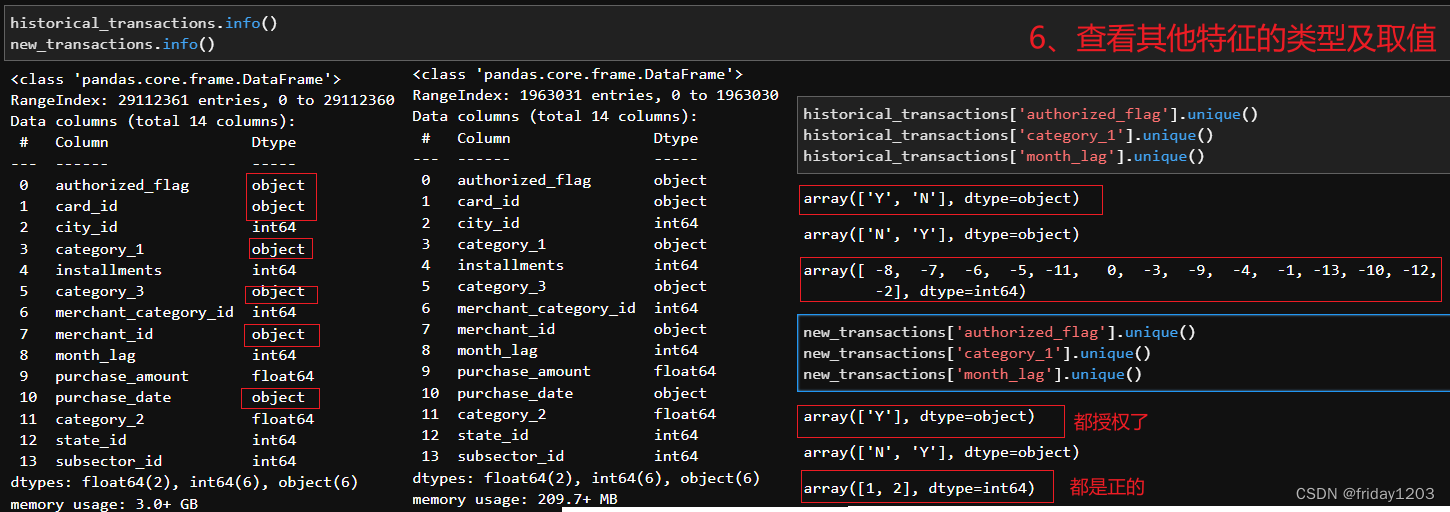
两张表中没有重复样本,但是category_3、category_2、merchant_id三个特征有大量缺失值。其中:
categroy_3是['B', nan, 'C', 'A'],是个匿名分类特征,应该是一个分类变量。
category_2是[ 1., nan, 3., 2., 4., 5.],应该是个有序分类变量。这个特征虽然表merchant中也有,但是不建议用Merchant表中的该特征,因为merchant表是商户信息表,其特征应该是描述商户的特性,而本案例的训练集target是信用卡用户的商品推荐评分,所以一切特征都应该围绕信用卡用户的特性来构建,所以这里的category_2的缺失值不建议从merchant表中互补有无。但如果模型效果不好了,也是可以尝试的。 -
对于merchant_id缺失的样本,暂时先不用删除,因为我电脑内存有限,所以交易表关联商户表的时候,我只能挑商户表很少的几个特征关联一下,所以到时可以把这些样本的商户信息都置为0即可。
-
敲重点:我发现旧交易表中的month_lag指标都取的是0到-12这几个值,而新交易表中的month_lag指标都取得是1和2!所以我猜测新交易表是一个违约信息表。可能是信用卡如果不发生违约,那它得month_log就是0或者负几,可能该行的信用卡规定的授信期限是一年,所以不违约就是0到负12,如果违约就是违约1个月或者2个月,超过2个月的可能就是不记录了,就不是违约了而是违法了,该卡就不能再交易了,所以也就没有更多月份的违约记录了。同时也容易联想到训练集有2207个样本的特殊离群值,但是我发现这些离群值的卡有的在历史交易表中有很多交易数据但在新交易表中没有,就是说离群点中也有没有违约的卡,并不是所有的离群点都有违约记录。也证明了训练集target中的离群点其实和新交易表是没关系,其最大的关系还是背后的商品吧,可能这2207个离群点推荐的就是特殊商品吧。从这里也可以推断出,商品信息很重要!凡是涉及到商品信息的特征都尽量保留。
-
截至目前,虽然我们依然没有弄明白mew_merchant_transacction表的含义,但是historical_transaction表和new_merchant_transaction表的特征是一样,所以只能先将两张表纵向合并了。上图中我单独把特征purchase_data又拎出来,是因为bilibili里面有这个比赛的讲解视频,视频里面说这两张表的区别只是时间的不同,这里证明一下,其实不是的。新旧交易表的purchase_data几乎是重合的,唯一的区别就是month_lag指标的取值不同。所以更可以推断出新交易表是个违约表。比如一张信用卡card_id,它可以多次交易无违约,而多次交易只违约1个月或者2个月,就赶紧把钱还了,那它就可以继续交易了。而如果有的卡它违约了2个月以上,那它就不可以交易了,所以新旧交易表中都不显示这个卡号的交易信息了。暂时只能猜测这么多。
3、探索merchants表
merchants表是商户信息表,记录的都是商户的信息,是站在商户的角度的记录数据。前面我们推测出商品的信息非常重要,而这张表有很多商品信息。我们先看看这张表吧。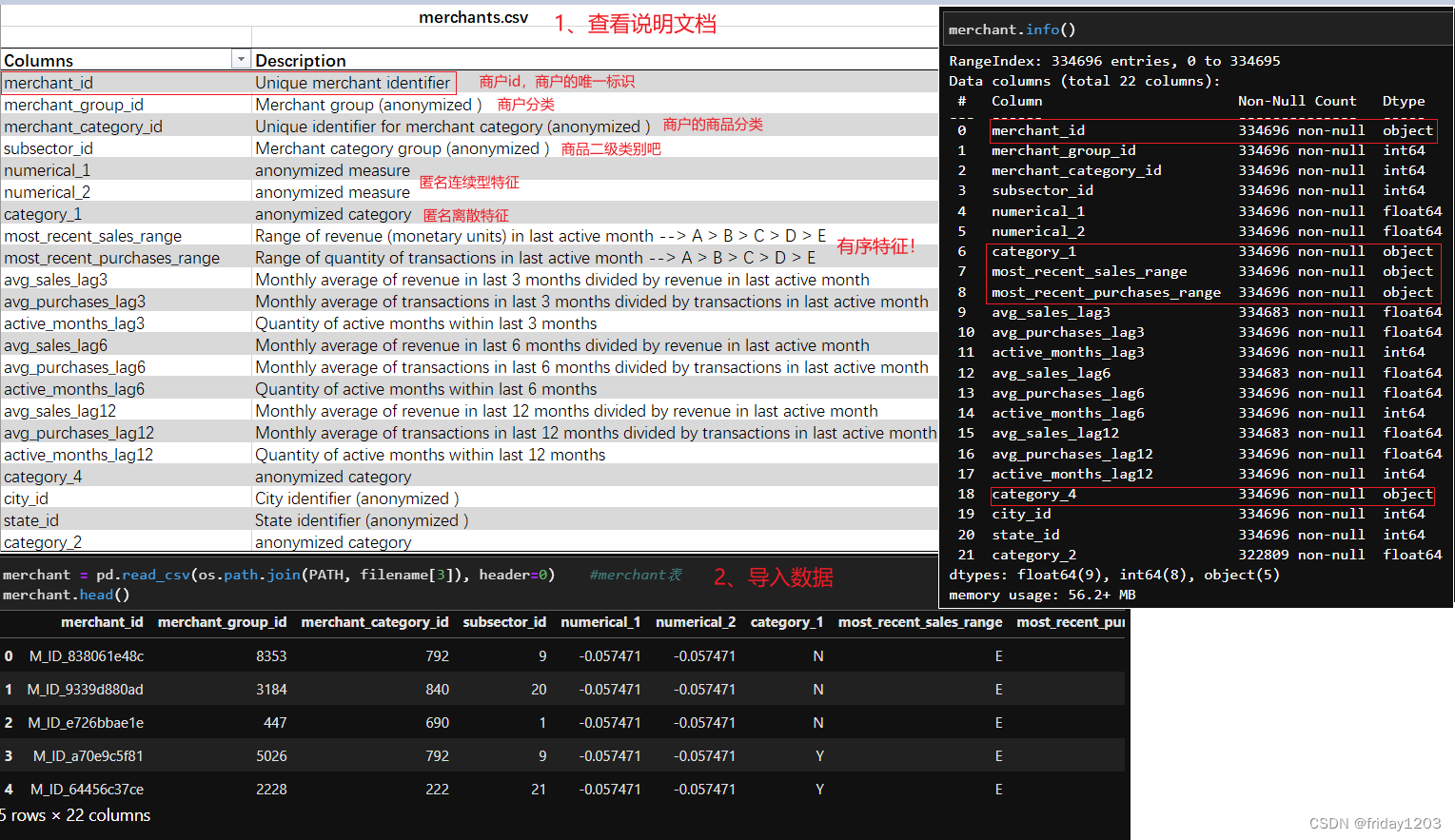
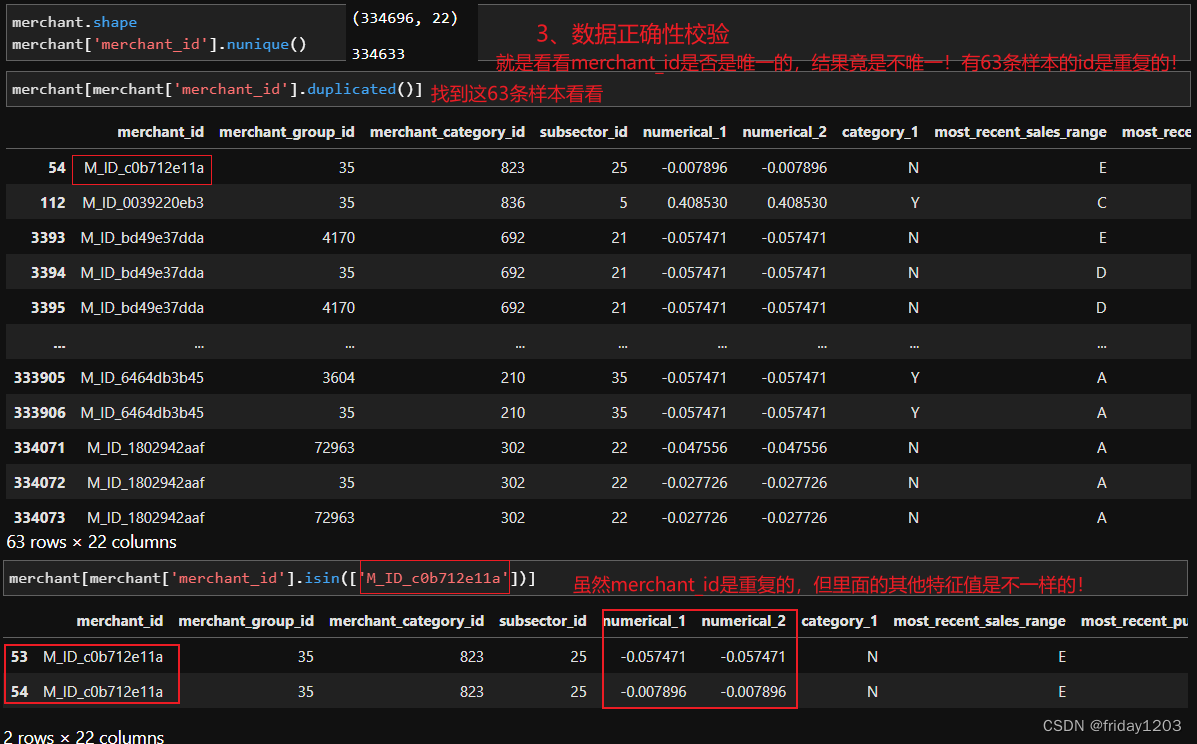
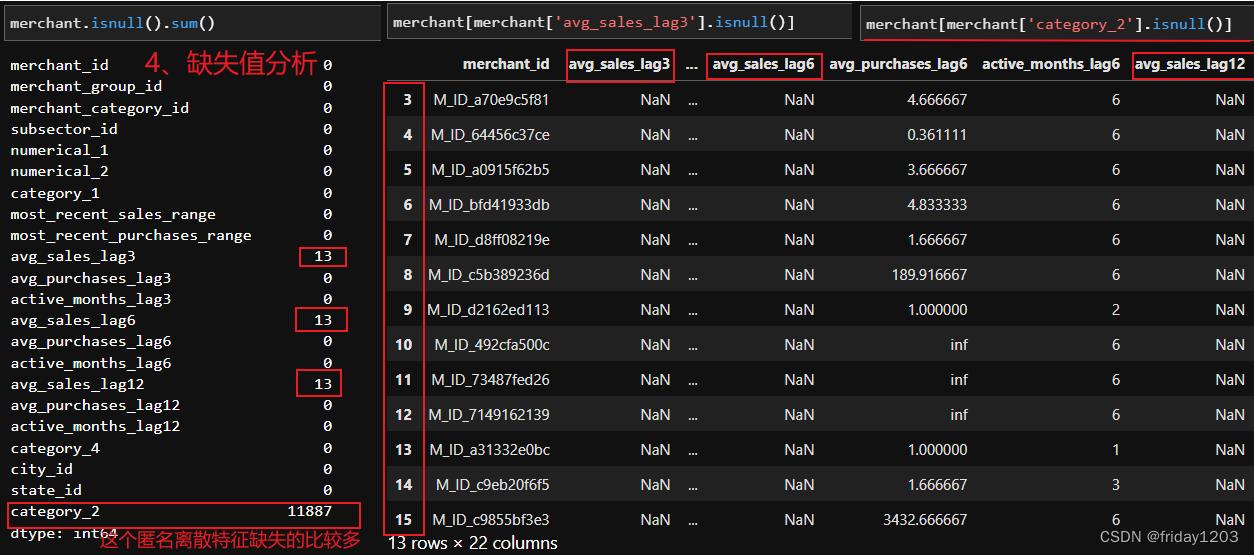
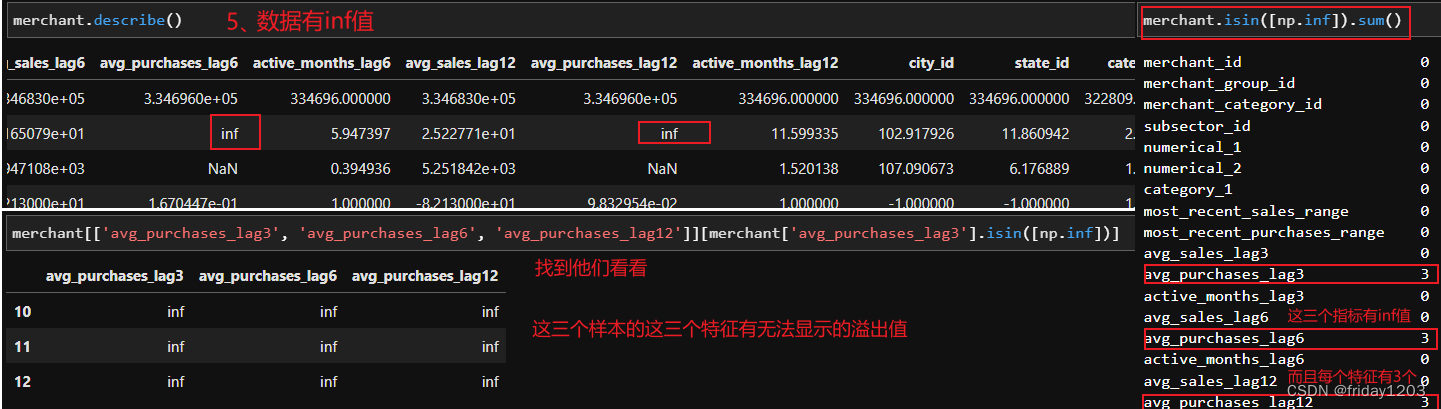
小结:
-
merchant表中的商户id有63个id是重复的,是需要删除这63条数据的,但是这63条样本中,其他特征的值是不同的,所以先简单删除这63条样本,后续模型效果不好的话,再尝试删除与这63条样本重复的其他样本。
-
特征avg_sales_lag3、avg_sales_lag6、avg_sales_lag12三个特征缺失13个值,由于他们都是连续性特征,并且缺失值比较少,所以用均值填充即可。
-
特征category_2缺失11887个值,由于这个特征是个离散特征,建议用-1填充,相当于先标注一下,后续如果效果不好再修改。
-
特征avg_purchase_lag3、avg_purchase_lag6、avg_purchase_lag12分布有3个inf值,无法显示的最大值,就是大到溢出了而无法显示了,建议用自身列的最值填充。
4、联表探索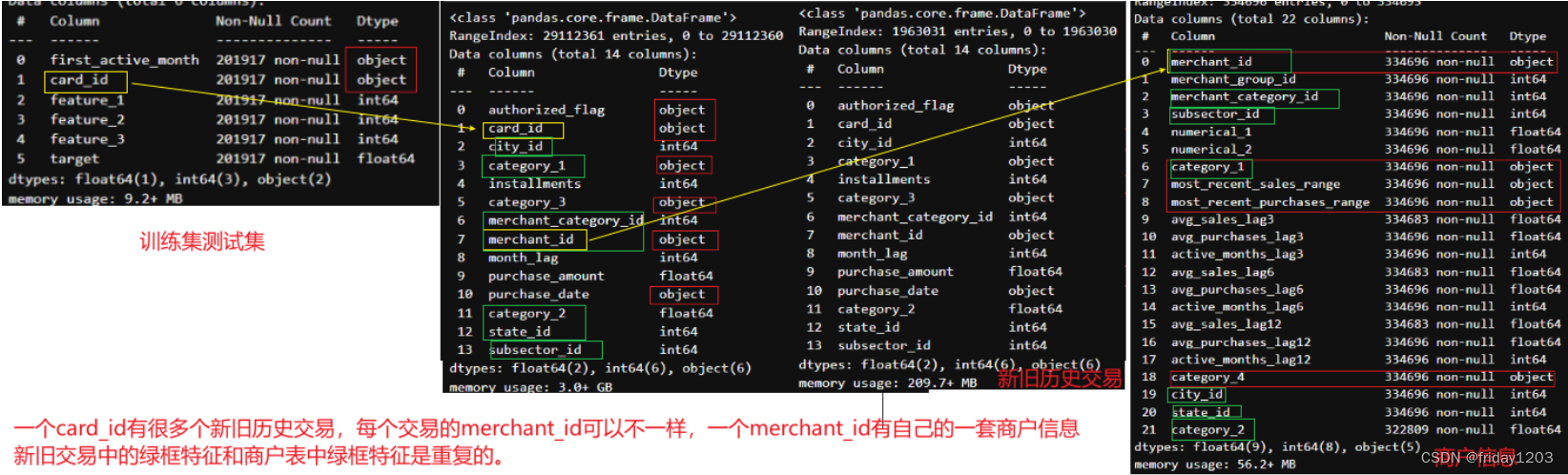
小结:
-
我们的训练集和测试集是以card_id为一个个样本,项目的任务是用card_id的特征进行建模,目标是预测对每个card_id进行商品推荐的分值。可能就是不用的分值对应不同的商品,如果你预测的分值对应的商品客户非常感兴趣,那就是说明你预测非常准确。
-
两张交易表的数据是训练集和测试集中的card_id在2011-11到2018-2之间的所有刷卡记录。区别只是month_lag指标的取值有所差别。
-
merchant表是商户信息表。
-
训练集特征只有4个,太少,得到新旧历史交易表和商户表提取更多的辅助信息放入到训练集去建模。而提取辅助信息要以训练集的card_id为主键。训练集和测试集中的card_id都是唯一的,没有重复的。所以从交易表和商户表提取的信息都应该是围绕信用卡这个主体来提取。而且涉及到商品的特征尽量都保留。
-
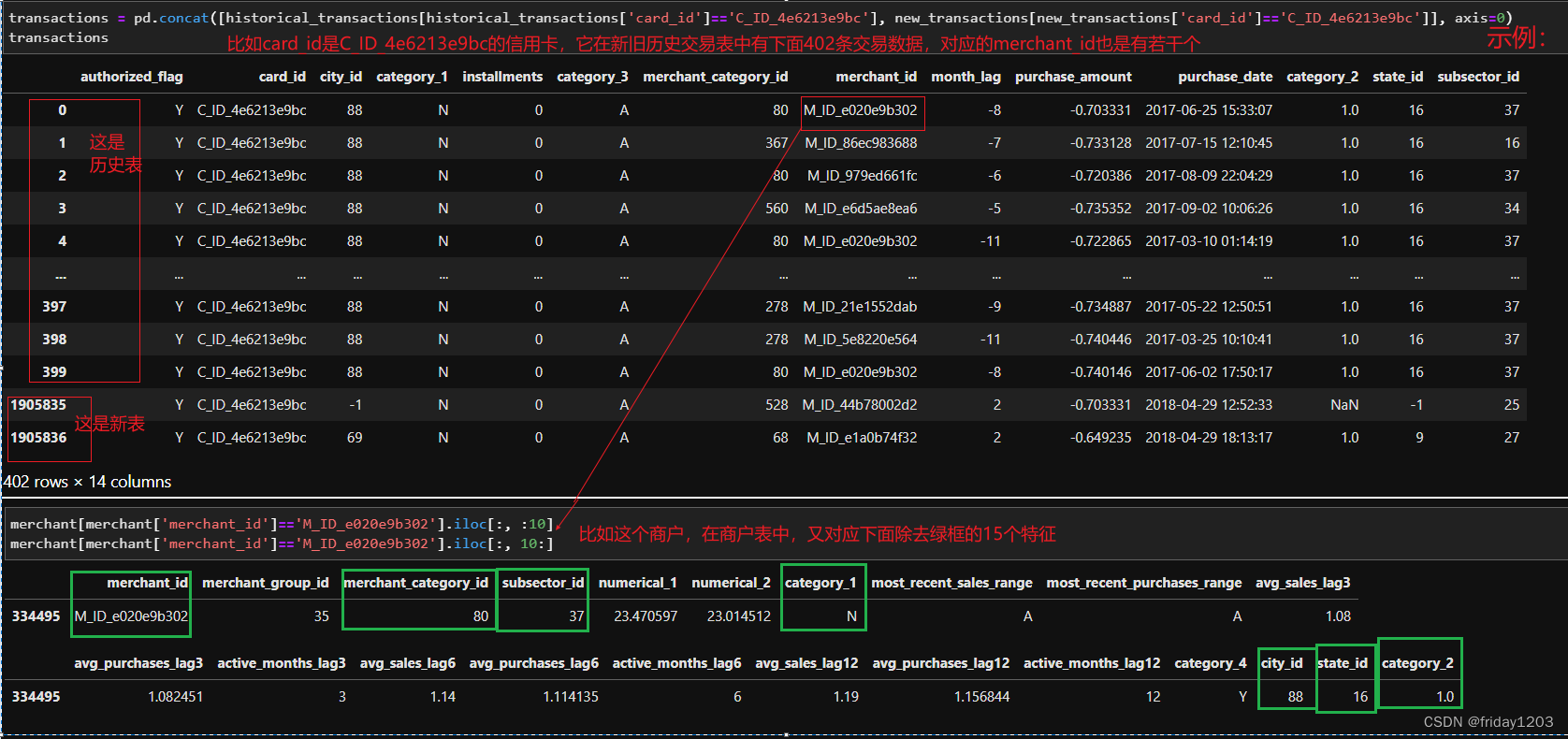
新旧历史交易和商户表重复的特征有:category_1, category_2, merchant_id, merchant_category_id, subsector_id, city_id, state_id七个特征。也就是说一张card_id它在新旧历史交易表中的上述七个特征的值和商户表中的商户七个特征是一样的。也就是说新旧历史交易表和商户表联表的时候可以把删除其中一个表的上述七个特征。具体删除哪个表的上述七个特征,我认为删除商户表中的特征更合适,因为我们是从训练集中的card_id映射到交易表的交易数据,然后从交易表的merchant_id映射到商户表的商户信息的。而我们的任务是预测每个card_id的商品推荐分值,所以尽量保留交易数据是合理的。
但是这里还有个小问题就是:
交易表中是有部分merchant_id和category_2缺失的,而商户表也是有部分category_2是缺失的。对于交易表中缺失的merchant_id样本自然就无法映射到对应的商户信息了,而对于merchant_id不缺失但是category_2缺失的样本来说,是可以对应到商户表的商户信息,而商户信息里面就可能会有category_2的信息。所以我们最好是能把两个表中的category_2互补有无一下,这样信息就会损失最少。但是我尝试了一下,3100多万条的数据量实在是太大,执行一个步骤都需要很多时间,所以就放弃了。最后采取的方法是:直接删除商户表中的七个重复特征,交易表中的category_2的缺失全部用-1填充。这里我想说的是,数据预处理以及特征工程都是极度消耗算力的,如果电脑硬件跟不上,很容易报下面的错误,即使你再捯饬你的虚拟内存,效果也不大,所以必须要在算力之内做事。![]()


















 955
955

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











