






Lustre在底层本地文件系统和Lustre之间提供了一个称为fsfilt的封装层。在上层中,obd_filter使用fsfilter层提供的一般化的函数,而fsfilter曾将这些调用传送到一个文件系统特有的实现中。这些特有的实现是特定的底层文件系统接口。fsfilt通过使用针对特定文件系统的小(tiny)封装(即对ext3使用的fsfilt和对Reiserfs3文件系统使用的fsfilt_reiserfs),调用本地文件系统。这节给出了fsfilt层的细节,并且分析了fsfilt_ext3,作为接口实现的一个实例。
11.1 概述
fsfilt框架大体是由lustre/include/luste_fsfilt.c定义的。在这个文件里,struct fsfilt_operations定义了对底层文件系统要求的操作。在obd_filter注册时,系统告知它建立在什么文件系统之上,而Lustre调用所需的文件系统注册操作。这是在内核模块(即ldiskfs、fsfilt_ext3)初始阶段完成的。对应的对每个文件系统实现的源码放在lustre/lvfs下。然而fsfilt_ldiskfs.c在HEAD CVF checkout的时候将会出现丢失,因为它是在建立时通过取得fsfilt_ext3.c并将所有ext3替换为ldiskfs来从ldiskfs_ext3.c(与在其他CVS branch里一样)产生的。Figure 15给出了Lustre fsfilt层的Linux模块的实现实例,和它们的通信路径。

需要提到的有趣的一点是,虽然在lustre/lvfs/fsfilt.c文件中定义了如下符号:
EXPORT_SYMBOL(fsfilt_register_ops);
EXPORT_SYMBOL(fsfilt_unregister_ops);
EXPORT_SYMBOL(fsfilt_get_ops);
EXPORT_SYMBOL(fsfilt_put_ops);
但是这个文件不是用来创建fsfilt内核模块的;实际上,根本没有这个内核模块。它和lvfs模块链接到一起,用以提供API,这些API用来注册访问文件系统的fsfilt方法。get_ops和put_ops调用允许fsfilt服务的使用者可以通过名字得到指向合适操作表的指针,也可以得到指针和引用,这样它就不被允许来卸载那些正在被使用的fsfilt_*模块了。当这些函数停止被使用后,它们释放相应的指针。
下面的列表给出了定义在lustre/include/linux/lustre_fsfilt.h 文件中的struct fsfilt_operations方法。
structfsfilt_operations {
struct list_head fs_list;
struct module *fs_owner;
char *fs_type;
char *(* fs_getlabel)(struct super_block*sb);
int (* fs_setlabel)(struct super_block*sb, char *label);
char *(* fs_uuid)(struct super_block *sb);
void *(* fs_start)(struct inode *inode,int op, void *desc_private,
int logs);
void *(* fs_brw_start)(int objcount,struct fsfilt_objinfo *fso,
int niocount, struct niobuf_local *nb,
void *desc_private, int logs);
int (* fs_extend)(struct inode *inode,unsigned nblocks, void *h);
int (* fs_commit)(struct inode *inode,void *handle,int force_sync);
int (* fs_commit_async)(struct inode*inode, void *handle,
void **wait_handle);
int (* fs_commit_wait)(struct inode*inode, void *handle);
int (* fs_setattr)(struct dentry *dentry,void *handle,
struct iattr *iattr, int do_trunc);
int (* fs_iocontrol)(struct inode *inode,struct file *file,
unsigned int cmd, unsigned long arg);
int (* fs_set_md)(struct inode *inode,void *handle, void *md,
int size, const char *name);
int (* fs_get_md)(struct inode *inode,void *md, int size,
const char *name);
int (* fs_send_bio)(int rw, struct inode*inode,struct kiobuf *bio);
ssize_t (* fs_readpage)(struct file *file,char *buf, size_t count,
loff_t *offset);
int (* fs_add_journal_cb)(structobd_device *obd, __u64 last_rcvd,
void *handle, fsfilt_cb_t cb_func,
void *cb_data);
int (* fs_statfs)(struct super_block *sb,struct obd_statfs *osfs);
int (* fs_sync)(struct super_block *sb);
int (* fs_map_inode_pages)(struct inode*inode, struct page **page,
int pages, unsigned long *blocks,
int *created, int create,
struct semaphore *sem);
int (* fs_write_record)(struct file *,void *, int size, loff_t *,
int force_sync);
int (* fs_read_record)(struct file *, void*, int size, loff_t *);
int (* fs_setup)(struct super_block *sb);
int (* fs_get_op_len)(int, structfsfilt_objinfo *, int);
int (* fs_quotacheck)(struct super_block*sb,
struct obd_quotactl *oqctl);
__u64 (* fs_get_version) (struct inode*inode);
__u64 (* fs_set_version) (struct inode*inode, __u64 new_version);
int (* fs_quotactl)(struct super_block*sb,
struct obd_quotactl *oqctl);
int (* fs_quotainfo)(structlustre_quota_info *lqi, int type,
int cmd);
int (* fs_qids)(struct file *file, structinode *inode, int type,
struct list_head *list);
int (* fs_get_mblk)(struct super_block*sb, int *count,
struct inode *inode, int frags);
int (* fs_dquot)(struct lustre_dquot*dquot, int cmd);
lvfs_sbdev_type (*fs_journal_sbdev)(struct super_block *sb);
};
11.2 ext3的fsfilt
正如上面所说的,Lustre为每个底层本地文件系统提供了一个特定的fsfilt实现。本节将解释为Linuxext3文件系统提供的fsfilt_ext3实现。lustre/lvfs/fsfilt_ext3.c文件被用来声明为ext3实现的fsfilt。在创建(build)时,fsfilt_ext3以模块的方式加入内核。模块的入口是module_init(fsfilt_ext3_init),出口是module_exit(fsfilt_ext3_exit)。
static int__init *fsfilt_ext3_init(void) {}
被用来在注册时进行初始化。所有本地文件系统特有的fsfilt实现都有这个调用。
在init函数内,首先由cfs_mem_cache_create()为日志提交回调函数创建一个高速缓存。这允许了当特定的日志事务提交时,产生一个回调。当前,Lustre不支持任何没有日志的的文件系统。在init方法中为高速缓存创建而返回的值是fcb_cache变量。这里fcb指出了提交回调数据。
同时,在init方法中,与其他的fsfilt实现一样,fsfilt_ext3.c声明了对特定底层文件系统所允许的操作,声明方法是通过static structfsfilt_operations fsfilt_ext3_ops={}定义,提供一个从fsfilt方法到fsfilt_ext3操作之间的一一映射。一些重要的fsfilt_ext3方法在下面进行更多的细节解释。
static void*fsfilt_ext3_start()
开始了元数据操作的旅行。它通过在该函数调用中前部的switch语句检查调用的是哪种操作。对每个操作,它计算对该特定元数据事务需要的最大块数目(由nblocks指出)。对于ext3,当元数据事务初始化后,要求它指定该事物需要使用多少块。如果请求的块数目少于可用的块数目,文件系统会刷新一些块出来,容纳请求的块大小。对于像ZFS这样的文件系统,并不要求有这个功能。
static char*fsfilt_ext3_get_label()
取得了文件系统标签,而
static char*fsfilt_ext3_set_label()
设置了文件系统标签。
static char*fsfilt_ext3_uuid()
允许fsfilt层询问文件系统的LinuxUUID。
static void*fsfilt_ext3_brw_start()
开始了对块I/O操作的日志事务。它将一个页缓冲作为参数。
Flow wise(?),元数据操作调用*fsfilt_ext3_start()来打开一个日志事务,并进行元数据操作,而块I/O操作则调用*fsfilt_ext3_brw_start()来打开一个日志事务。然而,*fsfilt_ext3_brw_start()并不实际执行块I/O,而是为事务创建一个日志句柄。对两种操作,日志都由*journal指针指定,其类型是journal_t。
同时,正如在源码中可以看到的,两个函数都有一个类型是handle_t的*handle指针。这是为需要日志句柄的任何操作准备的。这个句柄会作为参数传递到它的函数调用中去。
需要提到的重要一点是,在Lustre中,当对一个文件进行I/O时,首先改变索引节点,分配所有请求的块,然后关闭事务,最后分别执行I/O,所以日志事务并不是在实际I/O的整个过程中保持打开状态的。
static intfsfilt_ext3_commit()
提交并且关闭当前打开的日志事务。这个函数有一个称为force_sync的标志,它表明刷新是否应该立即执行。force_sync=0表明仅关闭事务,而不立即刷新;而force_sync=1表明关闭事务,并且立即刷新内存拷贝。
static intfsfilt_ext3_commit_async()
也关闭事务,并向调用者返回一个句柄(**wait_handle),这个句柄将在稍后的实际提交事务时使用。
In the truesense of(?)这两个操作,fsfilt_ext3_commit和fsfilt_ext3_commit_async都是异步的。然而由于可以使用force_sync选项,fsfilt_ext3_commit有可能同步地提交一个给定的日志事务。大多数情况下,使用fsfilt_ext3_commit function而fsfilt_ext3_commit_async则专门使用在DATA模式下。
static intfsfilt_ext3_send_bio()
提交对文件的I/O操作。在调用这个函数之前,I/O已经形成:创建好了一个缓冲链表,它们在磁盘上的目标已经在内核中设置了。这个函数只是用来处理文件数据的,这样这时就没有打开日志事务的必要了。在这个函数调用的时候,基于性能的考虑,日志事务已经关闭了。块I/O的典型流程将在10.3节讨论。这个流程之后,是调用fsfilt_ext3_send_bio函数来执行实际的块I/O。对于Linux 2.6内核,这个函数所做的事情就是调用submit_bio()内核函数。对于Linux 2.4内核,流程就稍微复杂点了,而且超出了这个报告的涉及范围。
static intfsfilt_ext3_extend()
以指定的块数延伸日志事务。请求的额外的块数由unsigned nblocks指定。在延伸之后,通过*handle,事务的句柄将维持不变,因为Lustre维护了单一的事务可见性。这对于那些不可能预测将使用多少块的操作,尤为有用。截短或者unlink操作是这个函数发挥作用的例子。
static intfsfilt_ext3_setattr()
更新了索引节点大小和属性(用户组、访问模式、各种文件时间和文件大小)。
static intfsfilt_ext3_iocontrol()
将iocontrol(或者ioctl)参数传递给底层的文件系统。
static intfsfilt_ext3_set_md()
和
static intfsfilt_ext3_get_md()
用来设置和询问分条信息。对于ext3,这个信息保存在EA中,而其实现是文件系统特有的。
static size_tfsfilt_ext3_readpage()
是用来从underlying文件或者目录中读取页的函数。在这个函数一开始的switch语句里,确定了要读取的是一个文件还是一个目录。如果是普通文件,它只简单地调用read()内核函数,用文件数据信息填充缓冲。然而,如果待读的是一个目录,它将调用ext3文件读函数来从文件中读取。
static intfsfilt_ext3_add_journal_cb()
用来跟新内存中的代表,这个代表是从事务的角度表示哪些东西已经在事实上提交到服务器里的磁盘中去了。对一个客户端,以内存中代表的形式回答如下问题是有用的:该给定客户端的哪些东西已经提交到给定服务器的磁盘上;因为这样,客户端可以丢弃该给定事务号锁对应的所有数据,从而节省内存。有这个功能的优点在于,一旦服务器崩溃了,数据将仍处于客户端的内存中,因为服务器不会回复*cb_data。这里*cb_data保存了上个一提交到磁盘上的事务的指针地址。其缺点是,通过在客户端保存额外的复本(服务器端还有复本),增加了对内存的消耗。
intfsfilt_ext3_map_ext_inode_pages()
是分配块的函数。它用来取得关于某块区间里的块的信息,而如果这些块还没有被分配,则一旦接收到请求了,就分配块。它向请求者送哪些块所处位置的页数组。
static intfsfilt_ext3_write_record()
和
static intfsfilt_ext3_read_record()
是用来跟新特定的LLOG(Lustre LOG)文件的。这个文件会自动跟新。在执行多节点操作时(例如,unlink,它需要从MDS开始,然后在OST上继续),需要LLOG。
static intfsfilt_ext3_setup()
用在ext3文件系统首次挂载时。obd_filter的初始化调用了这个函数。
static intfsfilt_ext3_get_op_len()
用来取得一个特定的操作在日志中需要的块数目。这个函数已经过时了,根本不被调用。
static __u64fsfilt_ext3_get_version()
和
static __u64fsfilt_ext3_set_version()
是用来设置和询问索引节点版本的。在我们所谈论的源码中,索引节点版本还未被使用。但是,在以后的源码中,它将用在进行基于版本的恢复机制里。
11.3 fsfilt的使用实例
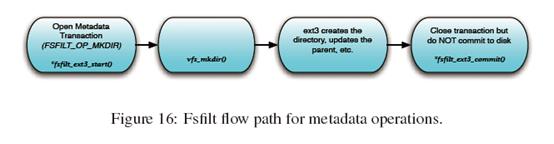
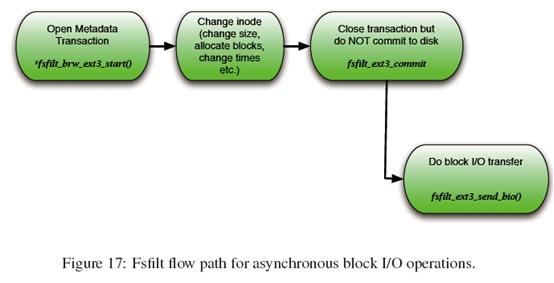
元数据操作、异步块I/O操作和同步块I/O操作的典型流程分别如Figure 16、17和18所示。
Figure 16是元数据操作的一个例子。这种流程在Lustre里使用,有两种情况:要么是当没有文件数据时,要么是当没有可用的客户端来对一组特定的元数据操作作回复时。
11.3.1 Lustre中的DIRECT_IO
Lustre对从obd_filter到磁盘的和从磁盘到obd_filter的文件数据I/O操作使用DIRECT_IO(在任一点都没有缓冲)。而元数据则总是记在日志里。
可以从Figure 17和18中看到,这些流程保证了在日志事务提交之前,数据就已经被实际写入磁盘中了。这写流程代表了使用DIRECT_IO的ORDERED日志模式。而在DATA模式下,块数据首先写入日志,然后在它提交到日志之后,文件数据才传输到磁盘中的。
11.3.2 在服务崩溃之后,重新执行上一个事务
我们考虑如下情况作为一个例子。客户端连接到服务器端,并执行了一些操作。服务器以一个提交向客户端回复,但是在这时,数据实际上没有提交到磁盘上。客户端现在记上一个正在提交的事务号为x+y,而根据服务器磁盘,它只是x。如果此时服务器此时崩溃了,就上一个已提交的事务号而言,在服务器和客户端之间就有冲突。让我们进一步假设如下事件链:服务器重启了,而客户端重新连上了服务器。服务器然后以acknowledgement和事务号作为回复,该事务是上一个从客户端发来的,已提交到服务器磁盘的事务。对于我们这个例子,这个事务号就是x。客户端就以如下内容作为回复:将x+5作为由该服务器提交的上一个事务号,并附以五个丢失了的,需要由服务器执行的事务列表。
11.3.3 客户端连接和重连
在Lustre中以force_sync =1来使用fsfilt_ext3_commit的另外一个例子是客户端连接和重连。每个Lustre服务器维护一个单独的客户端连接/重连操作列表。这个列表在每个服务器中单独存放,并且是日志化的。当客户端连接上时,它将写入一个单独的文件,该文件是完全日志化的。为了维护这个文件,将使用force_sync标志设置为1的fsfilt_ext3_commit,因为可能在客户端断开连接后,就没有客户端回复了。
11.3.4 为什么Lustre里的ls是昂贵的
让我们考虑在基于ext3的Lustre文件系统里的ls作为例子,这实际由幕后的fsfilt_ext3_readpage来完成。从客户端角度看,它连接到MDS,获取了它所感兴趣的目录的上下文和索引节点号。根据上下文信息,客户端接着向MDS发回对该目录里的每个文件的stat请求。MDS对每个stat请求(和其他的文件元数据相关的每个请求)回复分条信息。所有这些都是在几个RPC中完成的,如果,例如,在该目录中有三个文件,在该步结束后,客户端已经向MDS发出了五个不同的RPC(打开目录,读目录,和对每个文件的stat)。(实际上,普通的ls在ls期间不需要文件模式信息,但是大多数Linux发行版现在都提供了“colorls”,即根据文件类型的不同输出不同颜色的文件信息,所以它就需要对每个文件进行stat()。)紧接着这步,打比方说,如果客户端对文件大小信息感兴趣,它需要向所有处在stat信息列表中的OST发送“惊鸿一瞥”型RPC。这一步需要对每个文件反复进行。作为例子,再次假设这三个文件被分条到100个OST上,那么截止这步结束时,客户端将发送3+(3×100)或者说305个 RPC。这不仅对ls –l是对的,对于普通的ls也是对的,因为它需要找出文件模式。
本文章欢迎转载,请保留原始博客链接http://blog.csdn.net/fsdev/article














 629
629

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









