







一、Scala 入门
1. 概述
1.1 为什么学习Scala
- Spark——新一代内存级大数据 计算框架,是大数据的重要内容。
- Spark就是使用Scala编写的。因此为了更好的学习Spark, 需要掌握Scala这门语言。
总而言之,我是为了学习Spark而学习Scala的。
1.2 Scala 发展历史
联邦理工学院的马丁·奥德斯基(Martin Odersky)于2001年开始设计Scala。
1.3 Scala 和 Java 关系
一般来说,学Scala的人,都会Java,而Scala是基于Java的,因此我们需要将Scala和Java以及JVM 之间的关系搞清楚,否则学习Scala你会蒙圈。
1.4 Scala 语言特点
Scala 是一门 以Java虚拟机(JVM)为运行环境并将面向对象和函数式编程的最佳特性结合在一起的静态类型编程语言。
1)Scala是一门多范式的编程语言,Scala支持面向对象和函数式编程。
2)Scala源代码(.scala)会被编译成Java字节码(.class),然后运行于JVM之上,并可以调用现有的Java类库,实现两种语言的无缝对接。
3)Scala单作为一门语言来看,非常的简洁高效。
4)Scala在设计时,马丁·奥德斯基是参考了Java的设计思想,可以说Scala是源于Java,同时马丁·奥德斯基也加入了自己的思想,将函数式编程语言的特点融合到JAVA中, 因此,对于学习过Java的同学,只要在学习Scala的过程中,搞清楚Scala和Java相同点和不同点,就可以快速的掌握Scala这门语言。
2. Scala 环境搭建
-
安装步骤
(1)首先确保jdk1.8安装成功
(2)下载对应的Scala安装文件scala-2.11.8.zip
(3)解压scala-2.11.8.zip,我这里解压到E:\02_software
(4)配置Scala的环境变量
-
测试
3. Scala 插件安装
默认情况下IDEA 不支持 Scala 的开发,需要安装 Scala 插件。
3.1 插件在线安装
先找到安装插件位置点击file->setting
3.2 离线安装
除了可以在线安装还可以选择离线安装,当然还是推荐在线安装的好一点。
然后选择在官网下载好的插件即可。
4. HelloWorld 案例
4.1 IDEA环境创建
1)步骤1:file->new project -> 选择Maven
2)步骤2:添加包名和项目名称
3)步骤3:指定项目工作目录空间
4)为了方便管理,创建项目的源文件目录。点击Directory,写一个名字(比如scala),新建一个写Scala的目录。然后点击该目录右键——>Mark Directory as ——> Sorce Root
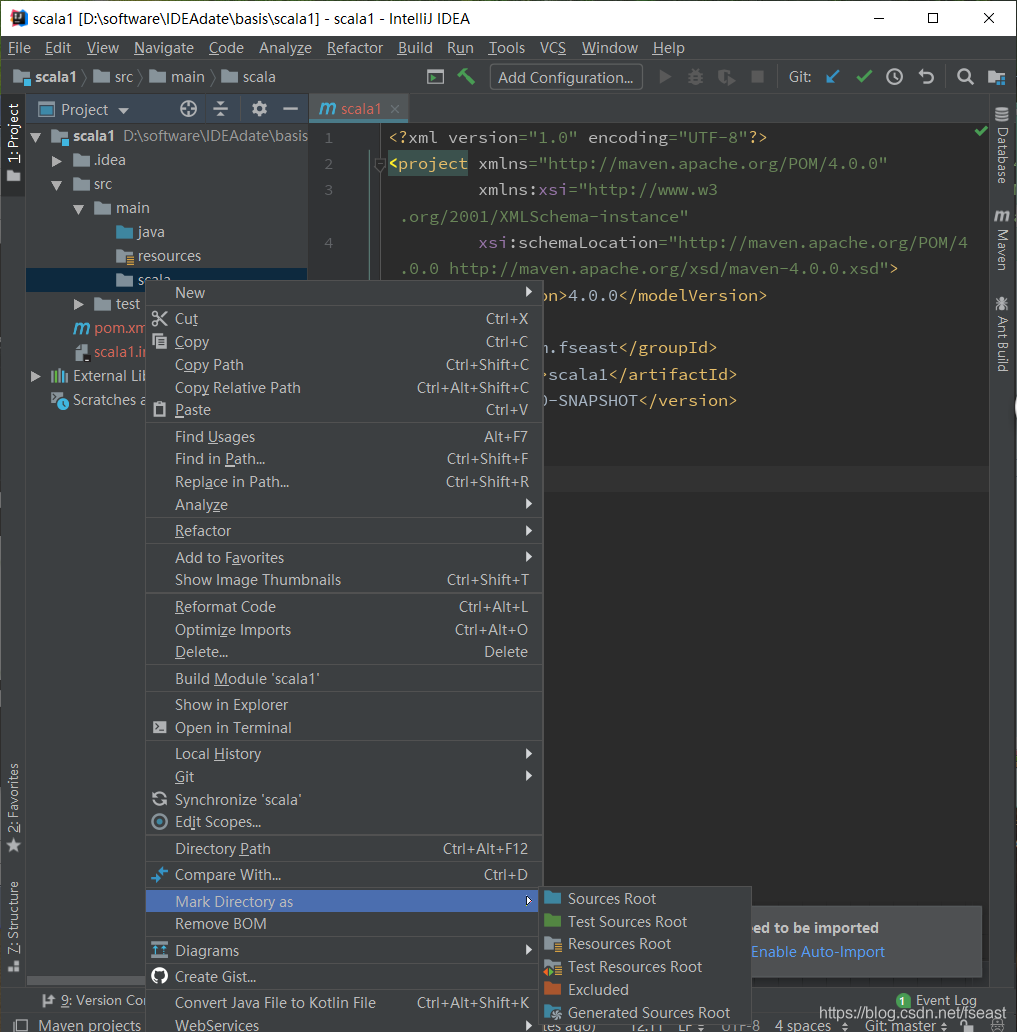
说明:右键main目录->创建一个diretory -> 写个名字(比如scala)->右键scala目录->mark directory ->选择source root即可。
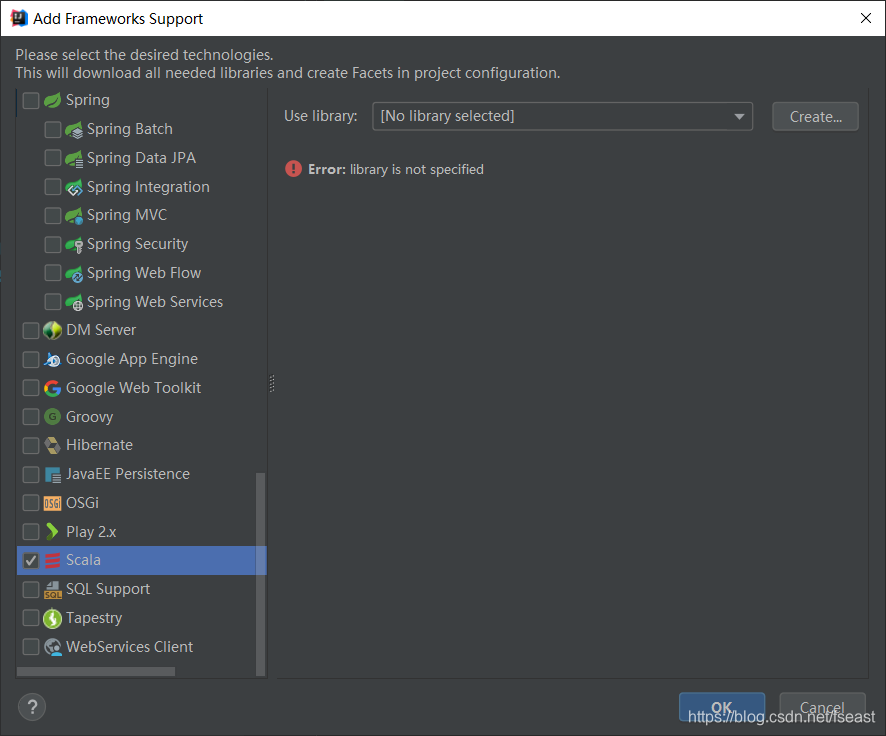
5)步骤5:默认下,maven不支持Scala的开发,需要引入Scala框架。
右键项目点击-> add framework support… ,在下图选择Scala,然后点击create…选择你的安装目录。
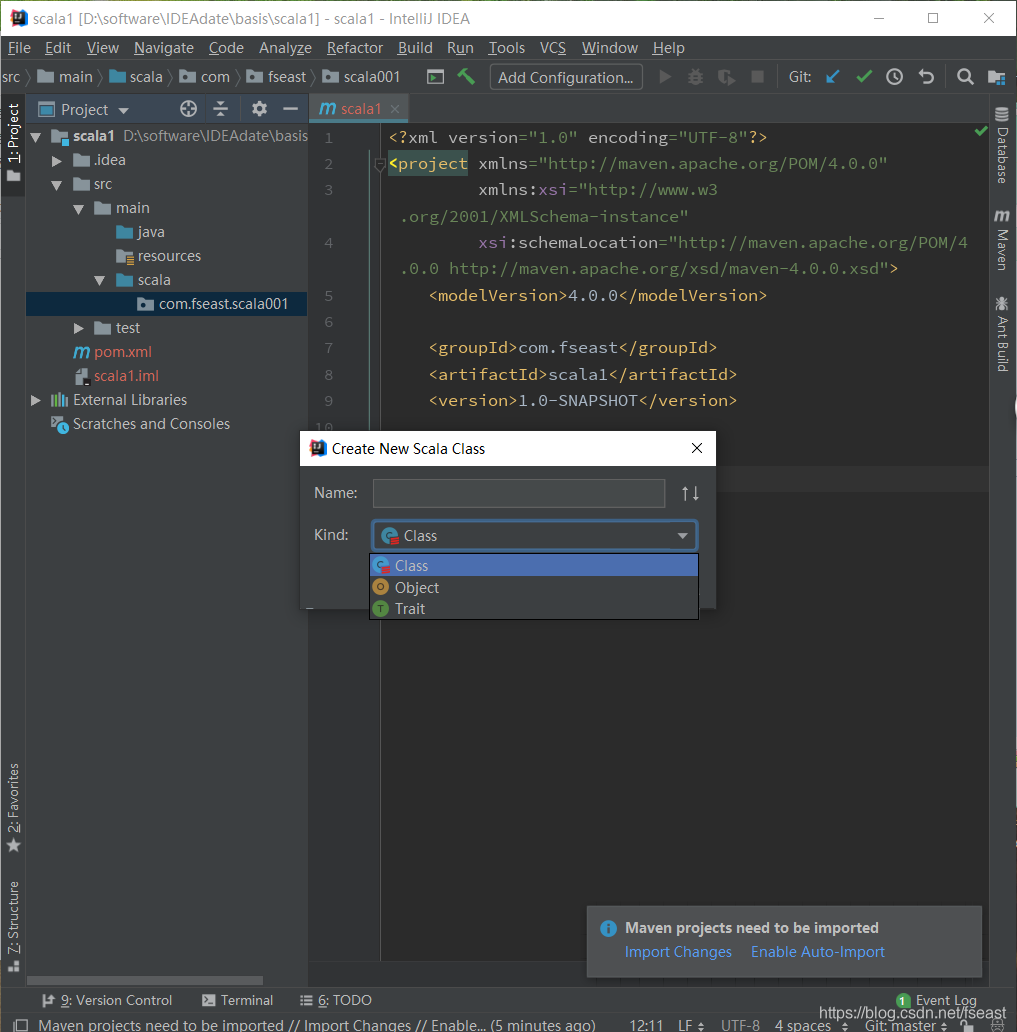
6)步骤6:在scala包下,创建包com.fseast.scala001包名,然后右键,new -> Scala Class,命名为HelloWorld,并创建Object。
7)步骤7:编写输出Hello scala案例
在类中中输入main,然后回车可以快速生成main方法。
package com.fseast.scala001
object HelloWorld {
def main(args: Array[String]): Unit = {
System.out.println("hello world")
println("hello")
}
}
运行后,就可以看到输出。
8)Scala程序基本结构
class Hello {
/*
定义变量:
val/var 变量名:变量类型 = 变量值
*/
val a: Int = 1
/*
定义方法:
def 函数名(参数名:参数类型):返回值类型={方法体}
*/
def hello(arg: String): Unit = {
println(arg)
}
}
4.2 Scala程序反编译
1)object在底层会生成两个类 Hello , Hello$
2)Hello中有个main函数,调用 Hello$ 类的一个静态对象 MODULES$
3)Hello$.MODULE$. 对象时静态的,通过该对象调用Hello$的main函数
4)可以理解我们在main中写的代码在放在Hello$的main,在底层执行Scala编译器做了一个包装
下面我们说明一下Scala程序的执行流程:
1. hello 源代码
object Hello {
def main(args: Array[String]): Unit = {
//4. 可以理解我们在main中写的代码在放在Hello$的main,在底层执行scala编译器做了一个包装
println("hello,scala")
}
}
2. Hello.class类
//package com.atguigu.chapter01
//1. object在底层会生成两个类 Hello , Hello$
//2. Hello中有个main函数,调用 Hello$ 类的一个静态对象 MODULES$
public final class Hello
{
public static void main(String[] paramArrayOfString)
{
Hello$.MODULE$.main(paramArrayOfString);
}
}
2. Hello$.class类
public final class Hello$
{
public static final MODULE$;
static
{
new ();
}
public void main(String[] args)
{
//3. Hello$.MODULE$. 对象是静态的,通过该对象调用Hello$的main函数
Predef..MODULE$.println("hello,scala");
}
private Hello$()
{
MODULE$ = this;
}
}
说明:
(1)Scala中如果使用object关键字声明类,在编译时,会同时生成两个类:当前类,当前类$
(2)使用当前类$的目的在于模拟静态语法,可以通过类名直接访问方法。
(3)Scala将当前类$这个对象称之为“伴生对象”,伴随着类所产生的对象,这个对象中的方法可以直接使用。
4.3 开发注意事项
1)Scala源文件以“.scala" 为扩展名。
2)Scala程序的执行入口是object 中的main()函数。
3)Scala语言严格区分大小写。
4)Scala方法由一条条语句构成,每个语句后不需要分号(Scala语言会在每行后自动加分号)。(至简原则)
5)如果在同一行有多条语句,除了最后一条语句不需要分号,其它语句需要分号。
5. 关联Scala源码
在使用Scala过程中,为了搞清楚Scala底层的机制,需要查看源码,下面看看如何关联和查看Scala的源码包。
1)查看源码,选择要查看的方法或者类,输入ctrl + b
当我们没关联源码时,看到如下图像:

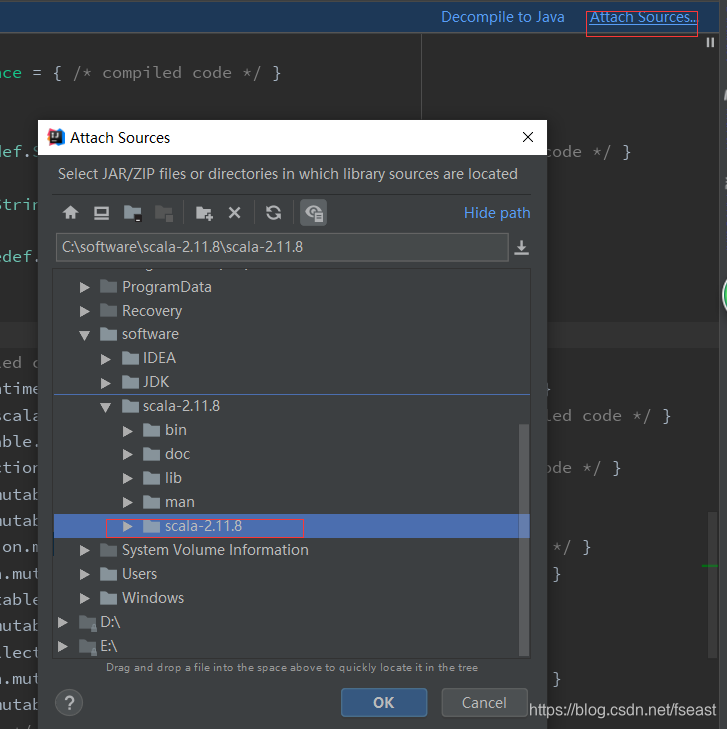
2)关联源码
步骤1:将源码包拷贝到C:\software\scala-2.11.8文件夹下scala-sources-2.12.4
步骤2:关联即可,选中这个文件夹,进行关联,最后,可以看到源码
6. 官方编程指南
查看scala-docs-2.11.8文档,可以获得Scala的API操作。
官方地址:https://docs.scala-lang.org/#
二、变量和数据类型
1. 注释
用于注解说明解释程序的文字就是注释,注释提高了代码的阅读性。
注释是一个程序员必须要具有的良好编程习惯。将自己的思想通过注释先整理出来,再用代码去体现。
1)基本语法
(1)单行注释://
(2)多行注释:/* */
(3)文档注释:/**
*
*/
2)代码规范
(1)使用一次tab操作,实现缩进,默认整体向右边移动,用shift+tab整体向左移
(2)或者使用ctrl + alt + L来进行格式化
(3)运算符两边习惯性各加一个空格。比如:2 + 4 * 5。
(4)一行最长不超过80个字符,超过的请使用换行展示,尽量保持格式优雅
- 标识符的命名规范
Scala对各种变量、方法、函数等命名时使用的字符序列称为标识符。即:凡是自己可以起名字的地方都叫标识符。
1)命名规则
Scala中的标识符声明,基本和Java是一致的,但是细节上会有所变化,有以下四种规则:
(1)以字母或者下划线开头,后接字母、数字、下划线
(2)以操作符开头,且只包含操作符(+ - * / # !等)
(3)第一种和第二种拼接,第一种在前,二者以下划线分隔
(4)用反引号`…`包括的任意字符串,即使是关键字(39个)也可以
2)Scala 关键字(39个)
• package, import, class, object, trait, extends, with, type, for
• private, protected, abstract, sealed, final, implicit, lazy, override
• try, catch, finally, throw
• if, else, match, case, do, while, for, return, yield
• def, val, var
• this, super
• new
• true, false, null
3. 变量和常量
var 变量
val 常量
1)基本语法
var | val 变量名 [: 变量类型] = 变量值
var a:Int = 19 //变量
val b:Int = 20 //常量
说明:在Scala中声明一个变量时,可以不指定类型,编译器根据值确定
大部分情况下用的都是常量。能用常量的地方不用变量。
2)案例实操
(1)声明变量时,类型可以省略(编译器自动推导,即类型推导)
(2)类型确定后,就不能修改,说明Scala是强数据类型语言。
(3)变量声明时,需要初始值
package com.fseast.scala001
object TestVar {
def main(args: Array[String]): Unit = {
//(1)声明变量时,类型可以省略(编译器自动推导,即类型推导)
var age = 18
age = 30
//(2)类型确定后,就不能修改,说明Scala是强数据类型语言。
// age = "tom" // 错误
//(3)变量声明时,需要初始值
// var name //错误
}
}
(4)在声明/定义一个变量时,可以使用var或者val来修饰,var修饰的变量可改变,val修饰的变量不可改。
object TestVar {
def main(args: Array[String]): Unit = {
var num1 = 10 // 可变
val num2 = 20 // 不可变
num1 = 30 // 正确
//num2 = 100 //错误,因为num2是val修饰的
}
}
(5)val修饰的变量在编译后,等同于加上final通过反编译看下底层代码
object TestVar {
var num1 = 10 // 可变
val num2 = 20 // 不可变
def main(args: Array[String]): Unit = {
num1 = 30 // 正确
//num2 = 100 //错误,因为num2是val修饰的
}
}
(6)var修饰的对象引用可以改变,val修饰的则不可改变,但对象的状态(值)却是可以改变的。(比如:自定义对象、数组、集合等等)
object TestVar {
def main(args: Array[String]): Unit = {
// p1是var修饰的,p1的属性可以变,而且p1本身也可以变
var p1 = new Person()
p1.name = "dalian"
p1 = null
// p2是val修饰的,则p2的属性可以变,但是p2本身不可变(即p2的内存地址不能变)
val p2 = new Person()
p2.name="xiaolian"
// p2 = null // 错误的,因为p2是val修饰的
}
}
class Person{
var name : String = "jinlian"
}
4. 字符串输出
1)基本语法
(1)字符串,通过+号连接
(2)printf用法:字符串,通过%传值。
(3)字符串,通过$引用
package com.fseast.scala001
object TestCharType {
def main(args: Array[String]): Unit = {
var name:String = "fseast"
var age:Int = 22
//(1)字符串,通过+号连接
println(name + " " + age)
//(2)printf用法字符串,通过%传值。
printf("name=%s age=%d\n",name,age)
//(3)字符串,通过$引用
println(s"name=$name age=$age")
println(
s"""
|name=${name}
|age=${age}
""".stripMargin
)
}
}
5. 键盘输入
在编程中,需要接收用户输入的数据,就可以使用键盘输入语句来获取。
1)基本语法
StdIn.readLine()、StdIn.readShort()、StdIn.readDouble()
2)案例实操
需求:可以从控制台接收用户信息【姓名,年龄,薪水】。
package com.fseast.scala001
import scala.io.StdIn
object TestInput {
def main(args: Array[String]): Unit = {
//1. 输入姓名
val name = StdIn.readLine("input name:")
//2. 输入年龄
val age = StdIn.readLine("input age:")
//3. 输入薪水
val sal = StdIn.readLine("input sal")
//把输入内容打印出来
println("name:" + name)
println("age:" + age)
println("sal:" + sal)
}
}
6. 数据类型关系
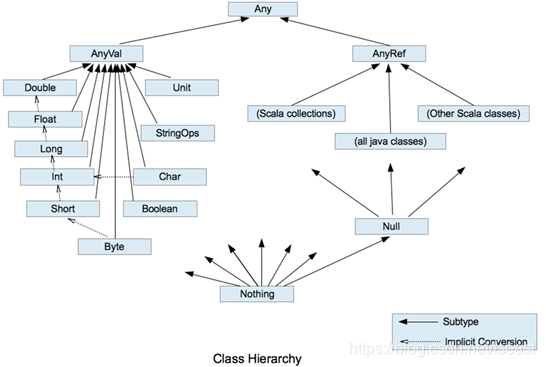
Scala数据类型关系总结
1)Scala中一切数据都是对象,都是Any的子类。
2)Scala中数据类型分为两大类:数值类型(AnyVal)、引用类型(AnyRef),不管是值类型还是引用类型都是对象。
3)Scala数据类型仍然遵守,低精度的值类型向高精度值类型,自动转换(隐式转换)
4) Scala特殊的类型之Null,它只有一个实例就是Null,它是所有引用类型(AnyRef)的子类。
5)Scala特殊类型之Nothing,是所有数据类型的子类,主要在一个函数没有正常返回值使用,因为这样我们可以把抛出的返回值,返回给任何的变量或者函数。
7. 整数类型(Byte、Short、Int、Long)
Scala的整数类型就是用于存放整数值的,比如12,30,3456等等。
1)整型分类
| 数据类型 | 描述 |
|---|---|
| Byte [1] | 8位有符号补码整数。数值区间为 -128 到 127 |
| Short [2] | 16位有符号补码整数。数值区间为 -32768 到 32767 |
| Int [4] | 32位有符号补码整数。数值区间为 -2147483648 到 2147483647 |
| Long [8] | 64位有符号补码整数。数值区间为 -9223372036854775808 到 9223372036854775807 = 2的(64-1)次方-1 |
- Scala各整数类型有固定的表数范围和字段长度,不受具体操作的影响,以保证Scala程序的可移植性。
object TestDataType {
def main(args: Array[String]): Unit = {
// 正确
var n1:Byte = 127
var n2:Byte = -128
// 错误
// var n3:Byte = 128
// var n4:Byte = -129
}
}
- Scala的整型,默认为Int型,声明Long型,须后加‘l’或‘L’
object TestDataType {
def main(args: Array[String]): Unit = {
var n5 = 10
println(n5)
var n6 = 9223372036854775807L
println(n6)
}
}
- Scala程序中变量常声明为Int型,除非不足以表示大数,才使用Long
8. 浮点类型(Float、Double)
Scala的浮点类型可以表示一个小数,比如123.4f,7.8,0.12等等。
- 浮点型分类
| 数据类型 | 描述 |
|---|---|
| Float [4] | 32 位, IEEE 754标准的单精度浮点数 |
| Double [8] | 64 位 IEEE 754标准的双精度浮点数 |
- Scala的浮点型常量默认为Double型,声明Float型常量,须后加‘f’或‘F’。
object TestDataType {
def main(args: Array[String]): Unit = {
// 建议,在开发中需要高精度小数时,请选择Double
var n7 = 2.2345678912f
var n8 = 2.2345678912
println("n7=" + n7)
println("n8=" + n8)
}
}
运行结果:
n7=2.2345679
n8=2.2345678912
9. 字符类型(Char)
1) 基本说明
字符类型可以表示单个字符,字符类型是Char,16位无符号Unicode字符(2个字节),区间值为U+0000到U+FFFF。
2) 案例实操
(1)字符常量是用单引号 ’ ’ 括起来的单个字符。
(2)可以直接给Char赋一个整数,然后输出时,会按照对应的unicode字符输出
object TestCharType {
def main(args: Array[String]): Unit = {
//(1)字符常量是用单引号 ' ' 括起来的单个字符。
var c1: Char = 'a'
println("c1=" + c1)
//(2)可以直接给Char赋一个整数,然后输出时,会按照对应的unicode字符输出
println("c1码值=" + c1.toInt)
}
}
(3)Char类型是可以进行运算的,相当于一个整数,因为它都对应有Unicode码。
object TestCharType {
def main(args: Array[String]): Unit = {
var c2: Char = 98 // 正确,因为直接将一个数值给char,编译器只判断是否越界
var c3: Char = 'a' + 1 // 错误,Int高->char低,编译器判断类型
var c4: Char = ('a' + 1).toChar
}
}
(4)\t :一个制表位,实现对齐的功能
(5)\n :换行符
(6)\ :表示
(7)" :表示"
object TestCharType {
def main(args: Array[String]): Unit = {
//(4)\t :一个制表位,实现对齐的功能
println("姓名\t年龄")
//(5)\n :换行符
println("西门庆\n潘金莲")
//(6)\\ :表示\
println("c:\\岛国\\avi")
//(7)\" :表示"
println("同学们都说:\"大海哥最帅\"")
}
}
10. 布尔类型:Boolean
1)基本说明
(1)布尔类型也叫Boolean类型,Booolean类型数据只允许取值true和false
(2)boolean类型占1个字节。
2)案例实操
object TestBooleanType {
def main(args: Array[String]): Unit = {
var isResult : Boolean = false
var isResult2 : Boolean = true
}
}
11. Unit 类型、Null类型和 Noting类型
1)基本说明
| 数据类型 | 描述 |
|---|---|
| Unit | 表示无值,和其他语言中void等同。用作不返回任何结果的方法的结果类型。Unit只有一个实例值,写成()。 |
| Null | null , Null 类型只有一个实例值null |
| Nothing | Nothing类型在Scala的类层级的最低端;它是任何其他类型的子类型。当一个函数,我们确定没有正常的返回值,可以用Nothing来指定返回类型,这样有一个好处,就是我们可以把返回的值(异常)赋给其它的函数或者变量(兼容性) |
2)实操案例
(1)Null类只有一个实例对象,Null类似于Java中的null引用。Null可以赋值给任意引用类型(AnyRef),但是不能赋值给值类型(AnyVal)
object TestDataType {
def main(args: Array[String]): Unit = {
//null可以赋值给任意引用类型(AnyRef),但是不能赋值给值类型(AnyVal)
var n1: Int = null // 错误
println("n1:" + n1)
var cat = new Cat();
cat = null // 正确
}
}
class Cat {
}
(2)Unit类型用来标识过程,也就是没有明确返回值的函数。
由此可见,Unit类似于Java里的void。Unit只有一个实例——( ),这个实例也没有实质意义
object TestSpecialType {
def main(args: Array[String]): Unit = {
def sayOk : Unit = {// unit表示没有返回值,即void
println("say ok")
}
sayOk
}
}
(3)Nothing,可以作为没有正常返回值的方法的返回类型,非常直观的告诉你这个方法不会正常返回,而且由于Nothing是其他任意类型的子类,他还能跟要求返回值的方法兼容。
object TestSpecialType {
def main(args: Array[String]): Unit = {
def test() : Nothing={
throw new Exception()
}
test
}
}
12. 数值类型转换
12.1 数值类型自动转换
当Scala程序在进行赋值或者运算时,精度小的类型自动转换为精度大的数值类型,这个就是自动类型转换(隐式转换)。数据类型按精度(容量)大小排序为:
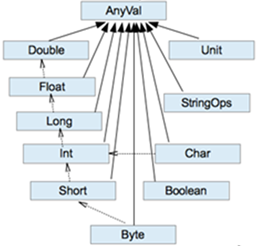
1)基本说明
(1)自动提升原则:有多种类型的数据混合运算时,系统首先自动将所有数据转换成精度大的那种数据类型,然后再进行计算。
(2)当我们把精度大的数值类型赋值给精度小的数值类型时,就会报错,反之就会进行自动类型转换。
(3)(byte,short)和char之间不会相互自动转换。
(4)byte,short,char他们三者可以计算,在计算时首先转换为int类型。
2)案例实操
object TestValueTransfer {
def main(args: Array[String]): Unit = {
//(1)自动提升原则:有多种类型的数据混合运算时,系统首先自动将所有数据转换成精度大的那种数值类型,然后再进行计算。
var n = 1 + 2.0
println(n) // n 就是Double
//(2)当我们把精度大的数值类型赋值给精度小的数值类型时,就会报错,反之就会进行自动类型转换。
var n2 : Long = 1L
//var n3 : Int = n2 //错误,原因不能把高精度的数据直接赋值和低精度。
//(3)(byte,short)和char之间不会相互自动转换。
var n4 : Byte = 1
//var c1 : Char = n4 //错误
//(4)byte,short,char他们三者可以计算,在计算时首先转换为int类型。
var n5 : Byte = 1
var c2 : Char = 1
// var n : Short = n5 + c2 //当n5 + c2 结果类型就是int
// var n6 : Short = 10 + 90 //错误
var n7 : Short = 100 //正确
}
}
12.2 强制类型转换
1)基本说明
自动类型转换的逆过程,将精度大的数值类型转换为精度小的数值类型。使用时要加上强制转函数,但可能造成精度降低或溢出,格外要注意。
java : int num = (int)2.5
scala : var num : Int = 2.7.toInt
2)案例实操
(1)当进行数据的从大——>小,就需要使用到强制转换
(2)强转符号只针对于最近的操作数有效,往往会使用小括号提升优先级
object TestForceTransfer {
def main(args: Array[String]): Unit = {
//(1)当进行数据的从大——>小,就需要使用到强制转换
var n1: Int = 2.5.toInt // 这个存在精度损失
//(2)强转符号只针对于最近的操作数有效,往往会使用小括号提升优先级
var r1: Int = 10 * 3.5.toInt + 6 * 1.5.toInt // 10 *3 + 6*1 = 36
var r2: Int = (10 * 3.5 + 6 * 1.5).toInt // 44.0.toInt = 44
println("r1=" + r1 + " r2=" + r2)
}
}
(3)Char类型可以保存Int的常量值,但不能保存Int的变量值,需要强转
(4)Byte和Short类型在进行运算时,当做Int类型处理。
object TestForceTransfer {
def main(args: Array[String]): Unit = {
//(3)Char类型可以保存Int的常量值,但不能保存Int的变量值,需要强转
var c2: Char = 98 // 正确,因为直接将一个数值给char,编译器只判断是否越界
var c3: Char = 'a' + 1 // 错误,Int高->char低,编译器判断类型
var c4: Char = ('a' + 1).toChar
//(4)Byte和Short类型在进行运算时,当做Int类型处理。
var a : Short = 5
// a = a-2 // 错误, Int->Short
var b : Byte = 3
// b = b + 4 // 错误,Int->Byte
}
}
13. 数值类型和 String 类型间转换
1)基本说明
在程序开发中,我们经常需要将基本数值类型转成String类型。或者将String类型转成基本数值类型。
2)案例实操
(1)基本类型转String类型(语法:将基本类型的值+"" 即可)
(2)String类型转基本数值类型(语法:s1.toInt、s1.toFloat、s1.toDouble、s1.toByte、s1.toLong、s1.toShort)
object TestStringTransfer {
def main(args: Array[String]): Unit = {
//(1)基本类型转String类型(语法:将基本类型的值+"" 即可)
var str1 : String = true + ""
var str2 : String = 4.5 + ""
var str3 : String = 100 +""
//(2)String类型转基本数值类型(语法:调用相关API)
var s1 : String = "12"
var n1 : Byte = s1.toByte
var n2 : Short = s1.toShort
var n3 : Int = s1.toInt
var n4 : Long = s1.toLong
}
}
(3)注意事项
在将String类型转成基本数值类型时,要确保String类型能够转成有效的数据,比如我们可以把"123",转成一个整数,但是不能把"hello"转成一个整数。
三、运算符
运算符是一种特殊的符号,用以表示数据的运算、赋值和比较等。
1. 算术运算符
1)基本语法
| 运算符 | 运算 | 范例 | 结果 |
|---|---|---|---|
| + | 正号 | +3 | 3 |
| - | 负号 | b=4; -b | -4 |
| + | 加 | 5+5 | 10 |
| - | 减 | 6-4 | 2 |
| * | 乘 | 3*4 | 12 |
| / | 除 | 5/5 | 1 |
| % | 取模(取余) | 7%5 | 2 |
| + | 字符串相加 | “He”+”llo” | “Hello” |
(1)对于除号“/”,它的整数除和小数除是有区别的:整数之间做除法时,只保留整数部分而舍弃小数部分。
(2)对一个数取模a%b,和Java的取模规则一样。
2)案例实操
object TestArithmetic {
def main(args: Array[String]): Unit = {
//(1)对于除号“/”,它的整数除和小数除是有区别的:整数之间做除法时,只保留整数部分而舍弃小数部分。
var r1: Int = 10 / 3 // 3
println("r1=" + r1)
var r2: Double = 10 / 3 // 3.0
println("r2=" + r2)
var r3: Double = 10.0 / 3 // 3.3333
println("r3=" + r3)
println("r3=" + r3.formatted("%.2f")) // 含义:保留小数点2位,使用四舍五入
//(2)对一个数取模a%b,和Java的取模规则一样。
var r4 = 10 % 3 // 1
println("r4=" + r4)
}
}
2. 关系运算符(比较运算符)
1)基本语法
| 运算符 | 运算 | 范例 | 结果 |
|---|---|---|---|
| == | 相等于 | 4==3 | false |
| != | 不等于 | 4!=3 | true |
| < | 小于 | 4<3 | false |
| > | 大于 | 4>3 | true |
| <= | 小于等于 | 4<=3 | false |
| >= | 大于等于 | 4>=3 | true |
2)案例实操
object TestRelation {
def main(args: Array[String]): Unit = {
// 测试:>、>=、<=、<、==、!=
var a: Int = 2
var b: Int = 1
println(a > b) // true
println(a >= b) // true
println(a <= b) // false
println(a < b) // false
println("a==b" + (a == b)) // false
println(a != b) // true
}
}
3. 逻辑运算符
1)基本语法
用于连接多个条件(一般来讲就是关系表达式),最终的结果也是一个Boolean值。
假定:变量A为true,B为false
| 运算符 | 描述 | 实例 |
|---|---|---|
| && | 逻辑与 | (A && B) 运算结果为 false |
| || | 逻辑或 | (A || B) 运算结果为 true |
| ! | 逻辑非 | !(A && B) 运算结果为 true |
2)案例实操
object TestLogic {
def main(args: Array[String]): Unit = {
// 测试:&&、||、!
var a = true
var b = false
println("a&&b=" + (a && b)) // a&&b=false
println("a||b=" + (a || b)) // a||b=true
println("!(a&&b)=" + (!(a && b))) // !(a&&b)=true
}
}
4. 赋值运算符
1)基本语法
赋值运算符就是将某个运算后的值,赋给指定的变量。
| 运算符 | 描述 | 实例 |
|---|---|---|
| = | 简单的赋值运算符,将一个表达式的值赋给一个左值 | C = A + B 将 A + B 表达式结果赋值给 C |
| += | 相加后再赋值 | C += A 等于 C = C + A |
| -= | 相减后再赋值 | C -= A 等于 C = C - A |
| *= | 相乘后再赋值 | C *= A 等于 C = C * A |
| /= | 相除后再赋值 | C /= A 等于 C = C / A |
| %= | 求余后再赋值 | C %= A 等于 C = C % A |
| <<= | 左移后赋值 | C <<= 2 等于 C = C << 2 |
| >>= | 右移后赋值 | C >>= 2 等于 C = C >> 2 |
| &= | 按位与后赋值 | C &= 2 等于 C = C & 2 |
| ^= | 按位异或后赋值 | C ^= 2 等于 C = C ^ 2 |
| |= | 按位或后赋值 | C |= 2 等于 C = C | 2 |
注意:Scala中没有++、–操作符,需要通过+=、-=来实现同样的效果
2)案例实操
object TestAssignment {
def main(args: Array[String]): Unit = {
var r1 = 10
r1 += 1 // 没有++
r1 -= 2 // 没有--
}
}
5. 位运算符
1)基本语法
| 运算符 | 描述 | 实例 |
|---|---|---|
| & | 按位与运算符 | (a & b) 输出结果 12 ,二进制解释: 0000 1100 |
| | | 按位或运算符 | (a | b) 输出结果 61 ,二进制解释: 0011 1101 |
| ^ | 按位异或运算符 | (a ^ b) 输出结果 49 ,二进制解释: 0011 0001 |
| ~ | 按位取反运算符 | (~a ) 输出结果 -61 ,二进制解释: 1100 0011, 在一个有符号二进制数的补码形式。 |
| << | 左移动运算符 | a << 2 输出结果 240 ,二进制解释: 1111 0000 |
| >> | 右移动运算符 | a >> 2 输出结果 15 ,二进制解释: 0000 1111 |
| >>> | 无符号右移 | A >>>2 输出结果 15, 二进制解释: 0000 1111 |
2)案例实操
object TestPosition {
def main(args: Array[String]): Unit = {
// 测试:1000 << 1 =>10000
var n1 :Int =8
n1 = n1 << 1
println(n1)
}
}
四、流程控制
1. 分支控制if-else
让程序有选择的的执行,分支控制有三种:单分支、双分支、多分支
1.1 单分支
1)基本语法
if (条件表达式) {
执行代码块
}
说明:当条件表达式为ture时,就会执行{ }的代码。
2)案例实操
需求:输入人的年龄,如果该同志的年龄大于18岁,则输出“age > 18”
object TestIfElse {
def main(args: Array[String]): Unit = {
println("input age:")
var age = StdIn.readShort()
if (age > 18){
println("age>18")
}
}
}
1.2 双分支
1)基本语法
if (条件表达式) {
执行代码块1
} else {
执行代码块2
}
2)案例实操
需求:输入年龄,如果年龄大于18岁,则输出“age >18”。否则,输出“age <= 18”。
object TestIfElse {
def main(args: Array[String]): Unit = {
println("input age:")
var age = StdIn.readShort()
if (age > 18){
println("age>18")
}else{
println("age<=18")
}
}
}
1.3 多分支
1)基本语法
if (条件表达式1) {
执行代码块1
}
else if (条件表达式2) {
执行代码块2
}
……
else {
执行代码块n
}
2)案例实操
(1)需求:岳小鹏参加Scala考试,他和父亲岳不群达成承诺:如果,成绩为100分时,奖励一辆BM;成绩为(80,99]时,奖励一台iphone;其它时,什么奖励也没有。
object TestIfElse {
def main(args: Array[String]): Unit = {
println("请输入成绩")
val grade = StdIn.readInt()
if (grade == 100){
println("成绩为100分,奖励一辆BM")
}else if (grade > 80 && grade <= 90){
println("奖励一台iphone")
}else{
println("什么奖励也没有")
}
}
}
(2)需求:Scala中if else表达式其实是有返回值的,具体返回值取决于满足条件的代码体的最后一行内容。
object TestIfElse {
def main(args: Array[String]): Unit = {
println("input your age")
var age = StdIn.readInt()
var res = if(age > 18){
"您以成人"
}else{
"小孩子一个"
}
println(res)
}
}
(3)注意:
如果大括号{}内的逻辑代码只有一行,大括号可以省略。
Scala中是没有三元运算符,因为可以这样简写
object TestIfElse {
def main(args: Array[String]): Unit = {
// Java
// int result = flag?1:0
// Scala
var flag:Boolean = true
var result = if(flag) 1 else 0
println(result)
}
}
2. 嵌套分支
在一个分支结构中又完整的嵌套了另一个完整的分支结构,里面的分支的结构称为内层。分支外面的分支结构称为外层分支。嵌套分支不要超过3层。
1)基本语法
if(){
if(){
}else{
}
}
2)案例实操
参加百米运动会,根据性别提示进入男子组或女子组。如果是女子组,用时8秒以内进入决赛,否则提示淘汰。
object TestIfElse {
def main(args: Array[String]): Unit = {
println("输入性别:")
var gender = StdIn.readChar()
if (gender == '男'){
println("男子组")
}else{
println("女子组")
println("输入成绩:")
var grade = StdIn.readDouble()
if (grade > 8.0){
println("你被淘汰了")
}else{
println("成功晋级")
}
}
}
}
3. For 循环控制
Scala也为for循环这一常见的控制结构提供了非常多的特性,这些for循环的特性被称为for推导式或for表达式。
3.1 范围数据循环方式1
1)基本语法
for(i <- 1 to 3){
print(i + " ")
}
println()
(1)i 表示循环的变量,<- 规定to
(2)i 将会从 1-3 循环,前后闭合
2)案例实操
需求:输出10句“Hello”
object TestFor {
def main(args: Array[String]): Unit = {
for(i <- 1 to 10){
println("Hello"+i)
}
}
}
3.2 范围数据循环方式2
1)基本语法
for(i <- 1 until 3) {
print(i + " ")
}
println()
(1)这种方式和前面的区别在于i是从1到3-1
(2)即使前闭合后开的范围
2)案例实操
需求:输出10句 “Hello”
object TestFor {
def main(args: Array[String]): Unit = {
for(i <- 1 until 10+1){
println("Hello"+i)
}
}
}
3.3 循环守卫
1)基本语法
for(i <- 1 to 3 if i != 2) {
print(i + " ")
}
println()
说明:
(1)循环守卫,即循环保护式(也称条件判断式,守卫)。保护式为true则进入循环体内部,为false则跳过,类似于continue。
(2)上面的代码等价
for (i <- 1 to 3){
if (i != 2) {
print(i + "")
}
}
2)案例实操
需求:输出1到10中,不等于5的值
object TestFor {
def main(args: Array[String]): Unit = {
for (i <- 1 to 10 if i != 5) {
println(i + "")
}
}
}
3.4 循环步长
1)基本语法
for (i <- 1 to 10 by 2) {
println("i=" + i)
}
说明:by表示步长
2)案例实操
需求:输出1到10以内的所有奇数
for (i <- 1 to 10 by 2) {
println("i=" + i)
}
输出结果:
i=1
i=3
i=5
i=7
i=9
3.5 嵌套循环
1)基本语法
for(i <- 1 to 3; j <- 1 to 3) {
println(" i =" + i + " j = " + j)
}
说明:没有关键字,所以范围后一定要加;来隔断逻辑
上面的代码等价于:
for (i <- 1 to 3) {
for (j <- 1 to 3) {
println("i =" + i + " j=" + j)
}
}
3.6 引入变量
1)基本语法
for(i <- 1 to 3; j = 4 - i) {
println("i=" + i + " j=" + j)
}
说明:
(1)for推导式一行中有多个表达式时,所以要加;来隔断逻辑
(2)for推导式有一个不成文的约定:当for推导式仅包含单一表达式时使用圆括号,当包含多个表达式时,一般每行一个表达式,并用花括号代替圆括号,如下
for {
i <- 1 to 3
j = 4 - i
} {
println("i=" + i + " j=" + j)
}
2)案例实操
上面的代码等价于
for (i <- 1 to 3) {
var j = 4 - i
println("i=" + i + " j=" + j)
}
3.7 循环返回值
1)基本语法
val res = for(i <- 1 to 10) yield i
println(res)
说明:将遍历过程中处理的结果返回到一个新Vector集合中,使用yield关键字
2)案例实操
需求:将原数据中所有值乘以2,并把数据返回到一个新的集合中。
object TestFor {
def main(args: Array[String]): Unit = {
var res = for( i <-1 to 10 ) yield {
i * 2
}
println(res)
}
}
输出结果:
Vector(2, 4, 6, 8, 10, 12, 14, 16, 18, 20)
5. While 循环控制
1)基本语法
循环变量初始化
while (循环条件) {
循环体(语句)
循环变量迭代
}
说明:
(1)循环条件是返回一个布尔值的表达式
(2)while循环是先判断再执行语句
(3)与if语句不同,while语句没有返回值,即整个while语句的结果是Unit类型()
(4)因为while中没有返回值,所以当要用该语句来计算并返回结果时,就不可避免的使用变量,而变量需要声明在while循环的外部,那么就等同于循环的内部对外部的变量造成了影响,也就违背了函数式编程的重要思想(输入=>函数=>输出,不对外界造成影响),所以不推荐使用,而是推荐使用for循环。
2)案例实操
需求:输出10句 “Hello”
object TestWhile {
def main(args: Array[String]): Unit = {
var i = 0
while (i < 10) {
println("Hello" + i)
i += 1
}
}
}
6. do…while循环控制
1)基本语法
循环变量初始化;
do{
循环体(语句)
循环变量迭代
} while(循环条件)
说明:
(1)循环条件是返回一个布尔值的表达式
(2)do…while循环是先执行,再判断
2)案例实操
需求:输出10句 “Hello”
object TestWhile {
def main(args: Array[String]): Unit = {
var i = 0
do {
println("Hello" + i)
i += 1
} while (i < 10)
}
}
7. 多重循环控制
1)基本说明
(1)将一个循环放在另一个循环体内,就形成了嵌套循环。其中,for,while,do…while均可以作为外层循环和内层循环。【建议一般使用两层,最多不要超过3层】
(2)实质上,嵌套循环就是把内层循环当成外层循环的循环体。当只有内层循环的循环条件为false时,才会完全跳出内层循环,才可结束外层的当次循环,开始下一次的循环。
(3)设外层循环次数为m次,内层为n次,则内层循环体实际上需要执行m*n次。
2)案例实操
需求:打印出九九乘法表
object TestWhile {
def main(args: Array[String]): Unit = {
var max = 9
for (i <- 1 to max) {
for (j <- 1 to i) {
print(j + "*" + i + "=" + (i * j) + "\t")
}
println()
}
}
}
输出结果:
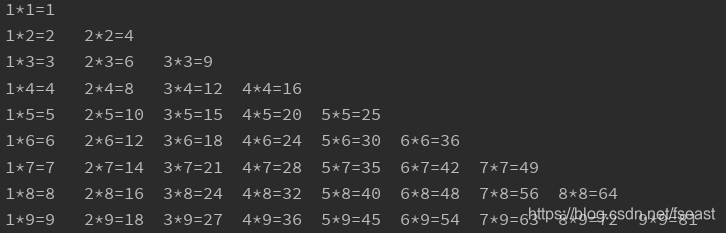
8. While 循环中断
1)基本说明
Scala内置控制结构特地去掉了break和continue,是为了更好的适应函数式编程,推荐使用函数式的风格解决break和continue的功能,而不是一个关键字。scala中使用breakable控制结构来实现break和continue功能。
2)案例实操
需求一:循环遍历10以内的所有数据,数值为5,结束循环(break)
import util.control.Breaks._
object TestBreak {
def main(args: Array[String]): Unit = {
var n = 1
breakable {
while (n < 10) {
println("n=" + n)
n += 1
if (n == 5) {
break()
}
}
}
println("exit")
}
}
需求二:循环遍历10以内的所有数据,奇数打印,偶数跳过(continue)
import util.control.Breaks._
object TestBreak {
def main(args: Array[String]): Unit = {
var n = 0
while (n < 10) {
breakable {
n += 1
if (n % 2 != 0) {
println(n)
} else {
println("continue")
break()
}
}
}
}
}
3)注意事项
(1)break:breakable放在循环外
(2)continue:breakable放在循环内














 3434
3434











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









