







数据分析-用python分析中国五大城市的PM2.5值(ols建立回归模型)
文章目录
分析目的
观察数据
数据清洗
数据整合
数据分析
分析目的
细颗粒物又称PM2.5,指环境空气中空气动力学当量直径小于等于2.5微米的颗粒物。它能较长时间悬浮于空气中,其在空气中含量浓度越高,就代表空气污染越严重。此次分析的目的是通过各城市的气象信息预测该城市的pm2.5值,具体气象信息包含空气湿度、温度等。
观察数据
这个小时数据集包含北京、上海、广州、成都和沈阳的PM2.5数据。同时,还包括各城市的气象资料。

数据清洗
观察数据可以看出每张表都有各自城市分区的pm值,这些值的缺失值较多,而且此次分析的重点是研究整个城市的pm值,因此将这些分区属性数据还有其他有缺失值的元组数据都删掉;同时数据中有no一列,该属性对此次的研究也没有意义,也应该删掉。
数据整合
将五张表都添加城市列,然后整合成一张总表。总表包含的分类变量有年(year)、月(month)、天(day)、小时(hour)、季节(season)、风向(CBWD)、城市(city);连续变量有PM值(PM_US Post)、露点(DEWP)、湿度(HUMI)、压力(PRES)、温度(TEMP)、累计风速(Iws)、降水量(precipitation)、累计降水量(Iprec)。
数据分析
数据预览
pm.info()

这份数据共有161630条观则。
连续变量描述
pm1=pm[['PM_US Post','DEWP','HUMI','PRES','TEMP','precipitation']]
pd.set_option('display.max_columns',500)#全部显示
pm1.describe()
pm1['PRES'].skew()#计算数据的偏度
pm1['PRES'].kurt()#计算数据的峰度

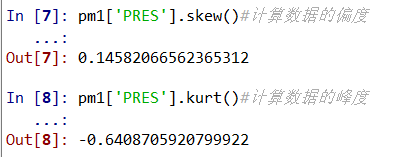
这五个城市有记录的PM值的均值近似为74,中位数为54,均值大于中位数值,说明此列数据呈右偏分布。同样呈右偏分布的还有降水量(precipitation)的值,但右偏幅度很小。相反,这五个城市有记录的露点(DEWP)、湿度(HUMI)、温度(TEMP)三列的值分别的均值均小于各自的中位数,则说明这三列数据都呈左偏分布,幅度较小。较特殊的是压力(PRES)列的值,它的中位数和均值相等,因此需要对对压力做偏度和峰度检验,由检验结果可以看出,偏度为0.14582,峰度为-0.64087,与0都相差不大,故可以将此列数据看作近似服从正态分布。
分季节观察
import matplotlib.pylab as plt
spring=pm[(pm["season"]==1)]
gp1& 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 4719
4719











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









