






本人是某不知名高校的研一渣渣一枚,初学python为了完成导师布置的任务,写文章的目的是为了记录一下过程。希望对读者解决类似问题有一些轻微帮助。
程序使用的库有pandas seaborn matplotlib
所有的数据都是导师打包给的csv文件:

每一个csv文件读取之后都如图所示:

每一年的数据格式都是大差不差
我们不需要把所有的字段全部读取,只需要使用Date(LST)和Value字段即可时间最终目的。
读取所有数据之后我们使用describe来看一下我们读取的数据:

可以发现Value里面最小值是-999,但是PM2.5的值是不可能是负的,我们在原始数据里发现,负的值它的Name字段是Missing,表示这个数据其实是无用数据,所以我们要剔除所有的负数值。

data=data[data['Value']>=0]
剔除之前有75215条记录,剔除之后总共有70760条记录。之后我们需要把Date(LST)设置为日期时间类型:

我们还需要进一步的数据预处理,选取每天的PM最大值作为代表,其他的数据都舍弃,作为后续分析的数据集。
我们可以按日期来分组并选取每日的最大值,所以我们需要对dataframe创建新的一列来存储每日这一个信息,可以用groupby实现这一目的。
将Date (LST)设置为日期时间日期类型之后,所有的都是类似2008-04-08 15:00这样的数据,所以我们可以用split把他从空格左右切开,左边就可以得到日期。
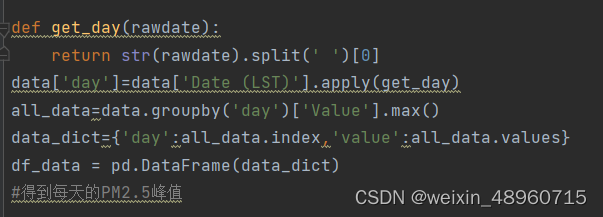
然后我们把Date (LST)设置为索引,数据的预处理就完成了。
接下来我们进行数据分析
首先我们可以分析每个月总共有多少条记录,从而分析每个月的数据确实情况。思路类似上一步按日期分组,我们可以按月来分组。
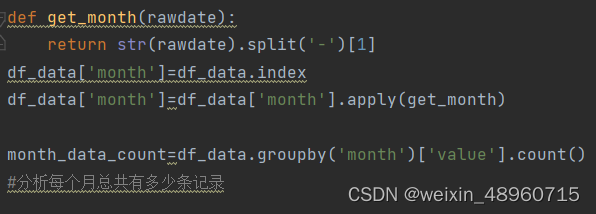
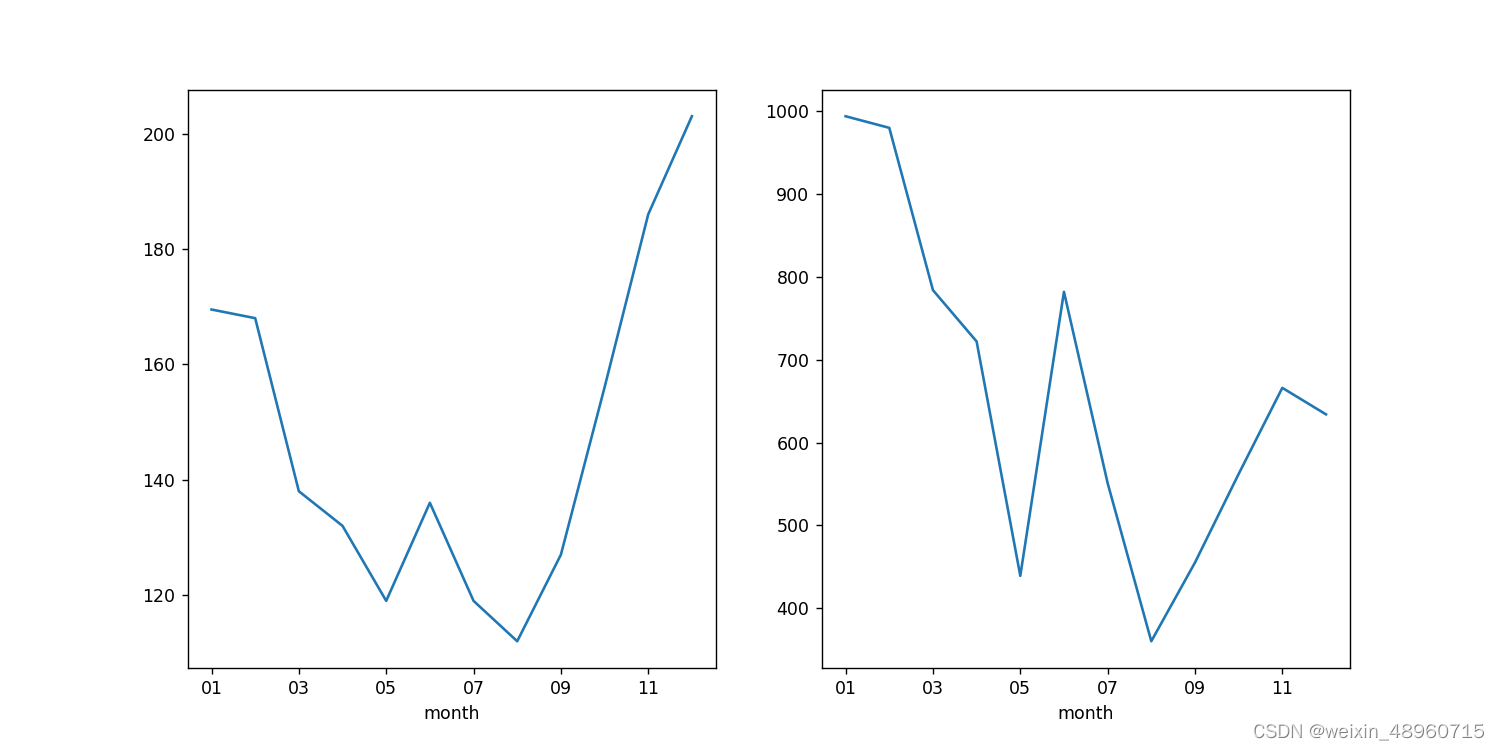
然后我们还可以得到每月的最大值,每月的中位值:
month_data_median=df_data.groupby('month')['value'].median()
month_data_max=df_data.groupby('month')['value'].max()
然后使用matplotlib里面的plot可以绘画折线图,如图:
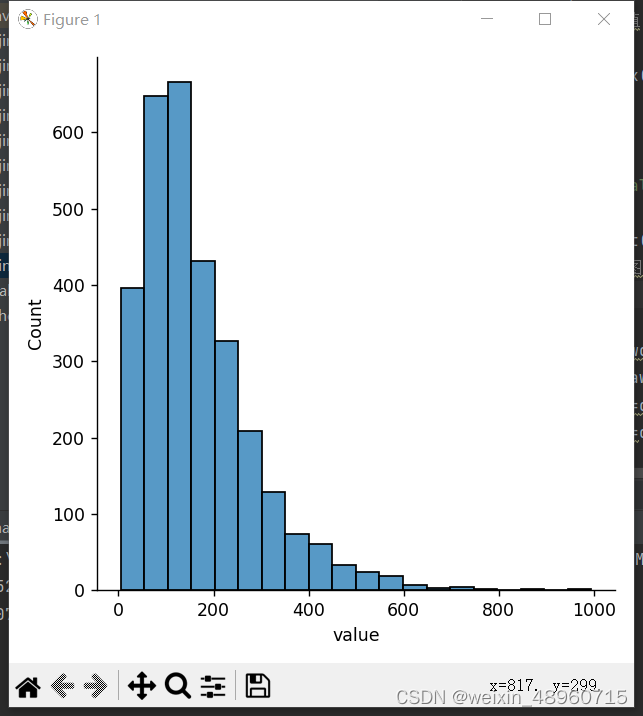
对于 PM的整体分布的直方图,可以使用seaborn库里面的displot来实现:
value=df_data['value'] #series数据 pm_dis=sb.displot(data=value,bins=20) #PM的整体分布的直方图
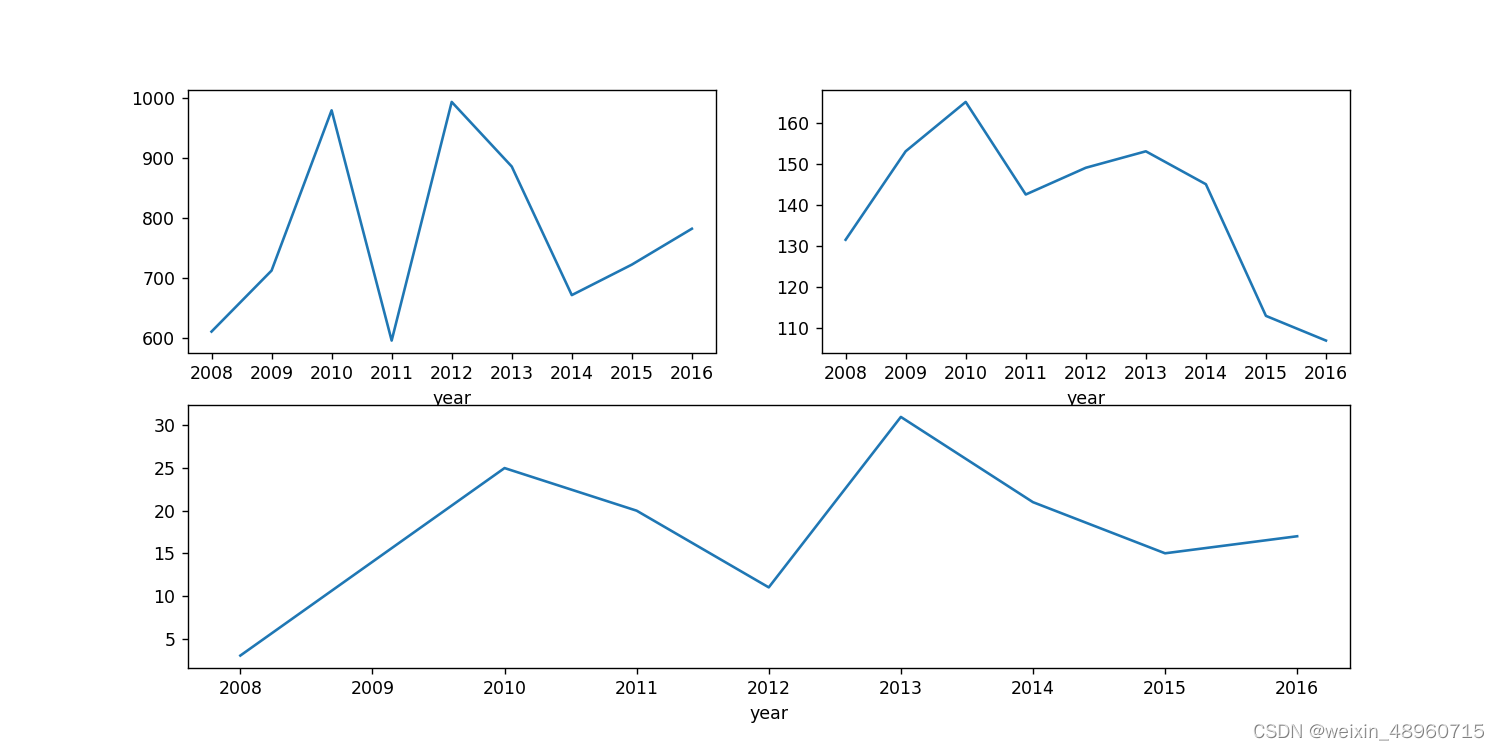
求每年的数据变化规律(中位数、最大值),画出线图。
这一目的需要我们按年来把所有的值分组,所有的date都是类似2008-04-08 15:00,所以我们按照‘-’切片,第一个就是数据对应的年份。
def get_year(rawdate):
return str(rawdate).split('-')[0]
df_data['year']=df_data.index
df_data['year']=df_data['year'].apply(get_year)
plt.figure(4,figsize=(12,6))
year_data_max=df_data.groupby('year')['value'].max()
plt.subplot(221)
year_data_max.plot()
#每年的PM2.5最大值折线图
计算每年报表的天数(value>400),并画出条图
对这一要求我们可以使用我们剔除无效数据的方法
data=data[data['Value']>=400]
然后再根据年份分组使用count计算需要报表的天数并画出折线图
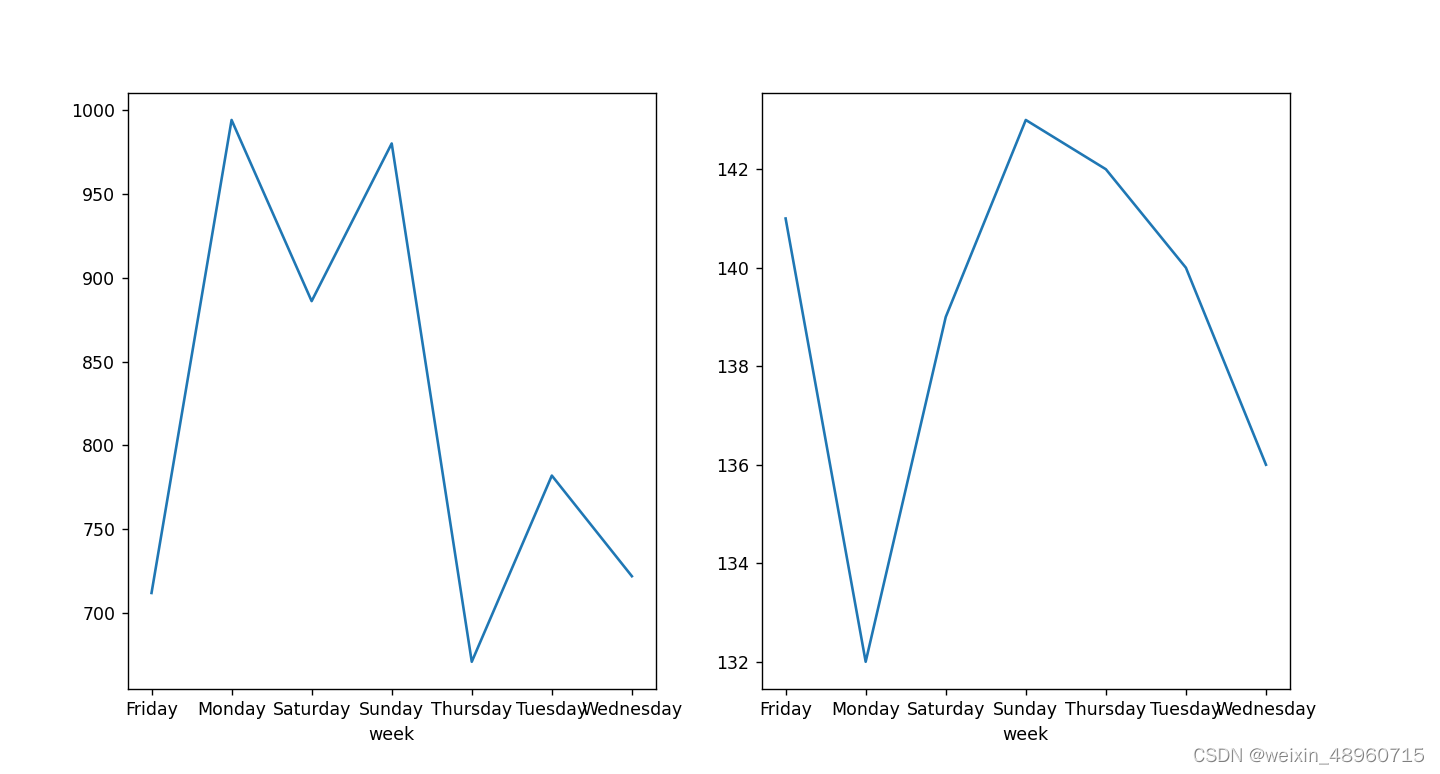
每周(7天)的数据变化规律(中位数、最大值),画出线图。
这一目的需要我们按周来把所有的值分组,我们可以先使用datetime里面的day_name方法得到每一天他所对应的星期几的名称,然后按照星期几来分组然后进行求最大值和中位数的计算并且画出线图
df_data['week'] = df_data.index
df_data['week'] = pd.to_datetime(df_data['week'])
df_data['week'] =df_data['week'].dt.day_name()
plt.figure(3,figsize=(12,6))
week_data_max=df_data.groupby('week')['value'].max()
plt.subplot(121)
week_data_max.plot()
week_data_median=df_data.groupby('week')['value'].median()
plt.subplot(122)
week_data_median.plot()
plt.show()
#每周的数据变化规律
其实对每周每月每年的数据处理都大同小异,都是先得到每一天它对应的周,月,年,然后再进行数据分组求最大值 中位值 进行画图。
整体代码如下:
import pandas as pd
import seaborn as sb
import matplotlib.pyplot as plt
data_path=['D:\pythonProject\PM2.5\Beijing_2009_HourlyPM25_created20140709.csv',
'D:\pythonProject\PM2.5\Beijing_2010_HourlyPM25_created20140709.csv',
'D:\pythonProject\PM2.5\Beijing_2011_HourlyPM25_created20140709.csv',
'D:\pythonProject\PM2.5\Beijing_2012_HourlyPM2.5_created20140325.csv',
'D:\pythonProject\PM2.5\Beijing_2013_HourlyPM2.5_created20140325.csv',
'D:\pythonProject\PM2.5\Beijing_2014_HourlyPM25_created20150203.csv',]
data=pd.read_csv('D:\pythonProject\PM2.5\Beijing_2008_HourlyPM2.5_created20140325.csv',encoding='ISO-8859-1',skiprows=2,usecols=[2,7])
for i in data_path:
data1=pd.read_csv(i,encoding='ISO-8859-1',skiprows=2,usecols=[2,7])
data= pd.concat([data, data1], axis=0)
data2015=pd.read_csv('D:\pythonProject\PM2.5\Beijing_2015_HourlyPM25_created20160201.csv',encoding='ISO-8859-1',skiprows=3,usecols=[2,7])
data= pd.concat([data, data2015], axis=0)
data2016=pd.read_csv('D:\pythonProject\PM2.5\Beijing_2016_HourlyPM25_created20170201.csv',encoding='ISO-8859-1',skiprows=3,usecols=[2,7])
data=pd.concat([data, data2016], axis=0)
#读取2008到2016的数据
data=data[data['Value']>=0]
#删除数据中的缺失值
data['Date (LST)'] = pd.to_datetime(data['Date (LST)'])
# date(LST)转为时间格式
#print(data)
def get_day(rawdate):
return str(rawdate).split(' ')[0]
data['day']=data['Date (LST)'].apply(get_day)
all_data=data.groupby('day')['Value'].max()
data_dict={'day':all_data.index,'value':all_data.values}
df_data = pd.DataFrame(data_dict)
#得到每天的PM2.5峰值
df_data.set_index('day',inplace = True)
#把时间设置成索引
value=df_data['value']
#series数据
pm_dis=sb.displot(data=value,bins=20)
#PM的整体分布的直方图
plt.show()
def get_month(rawdate):
return str(rawdate).split('-')[1]
df_data['month']=df_data.index
df_data['month']=df_data['month'].apply(get_month)
month_data_count=df_data.groupby('month')['value'].count()
#分析每个月总共有多少条记录
plt.figure(2,figsize=(12,6))
month_data_median=df_data.groupby('month')['value'].median()
plt.subplot(121)
month_data_median.plot()
#每个月的中位值折线图
month_data_max=df_data.groupby('month')['value'].max()
plt.subplot(122)
month_data_max.plot()
#每个月的最大值折线图
plt.show()
df_data['week'] = df_data.index
df_data['week'] = pd.to_datetime(df_data['week'])
df_data['week'] =df_data['week'].dt.day_name()
plt.figure(3,figsize=(12,6))
week_data_max=df_data.groupby('week')['value'].max()
plt.subplot(121)
week_data_max.plot()
week_data_median=df_data.groupby('week')['value'].median()
plt.subplot(122)
week_data_median.plot()
plt.show()
#每周的数据变化规律
def get_year(rawdate):
return str(rawdate).split('-')[0]
df_data['year']=df_data.index
df_data['year']=df_data['year'].apply(get_year)
plt.figure(4,figsize=(12,6))
year_data_max=df_data.groupby('year')['value'].max()
plt.subplot(221)
year_data_max.plot()
#每年的PM2.5最大值折线图
year_data_median=df_data.groupby('year')['value'].median()
plt.subplot(222)
year_data_median.plot()
#每年中位数据折线图
df_data=df_data[df_data['value']>=400]
year_data_over_400=df_data.groupby('year')['value'].count()
plt.subplot(212)
year_data_over_400.plot()
#每年需要报表的天数折线图
plt.show()














 1051
1051











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









