






本期内容全程手撕代码、逐帧剖析💥带你“从零到一”【开发】MCP工具,再将自己开发的MCP工具【部署上线】,并进行本地的MCP工具【维护】!
一、MCP技术快速入门回顾
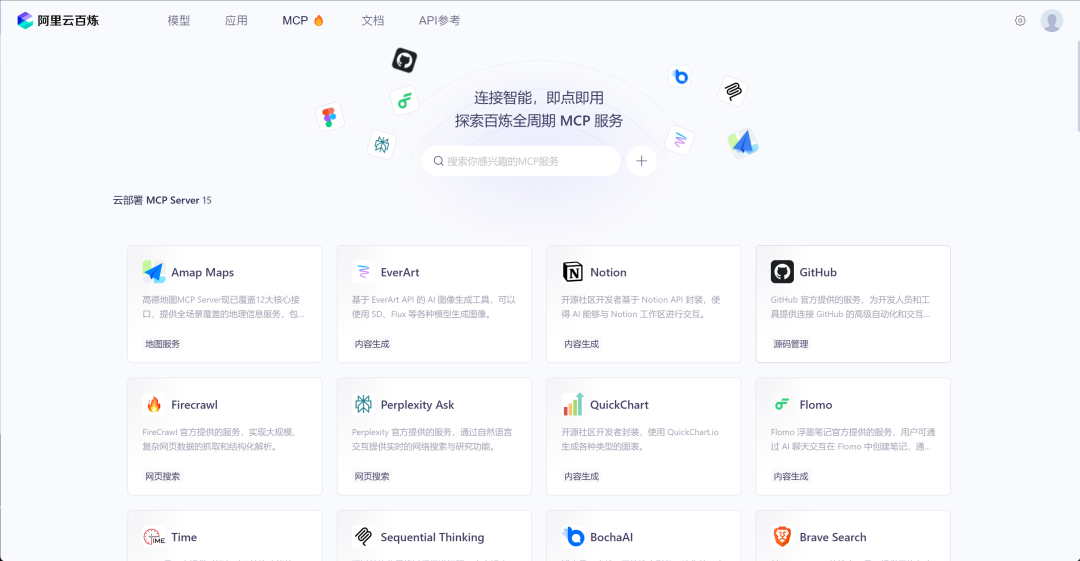
1.MCP服务器Server合集
-
MCP官方服务器合集:https://github.com/modelcontextprotocol/servers
-
MCP Github热门导航:https://github.com/punkpeye/awesome-mcp-servers
-
Smithery:https://smithery.ai/
-
MCP导航:https://mcp.so/
-
阿里云百炼:https://bailian.console.aliyun.com/?tab=mcp
2. MCP热门客户端Client
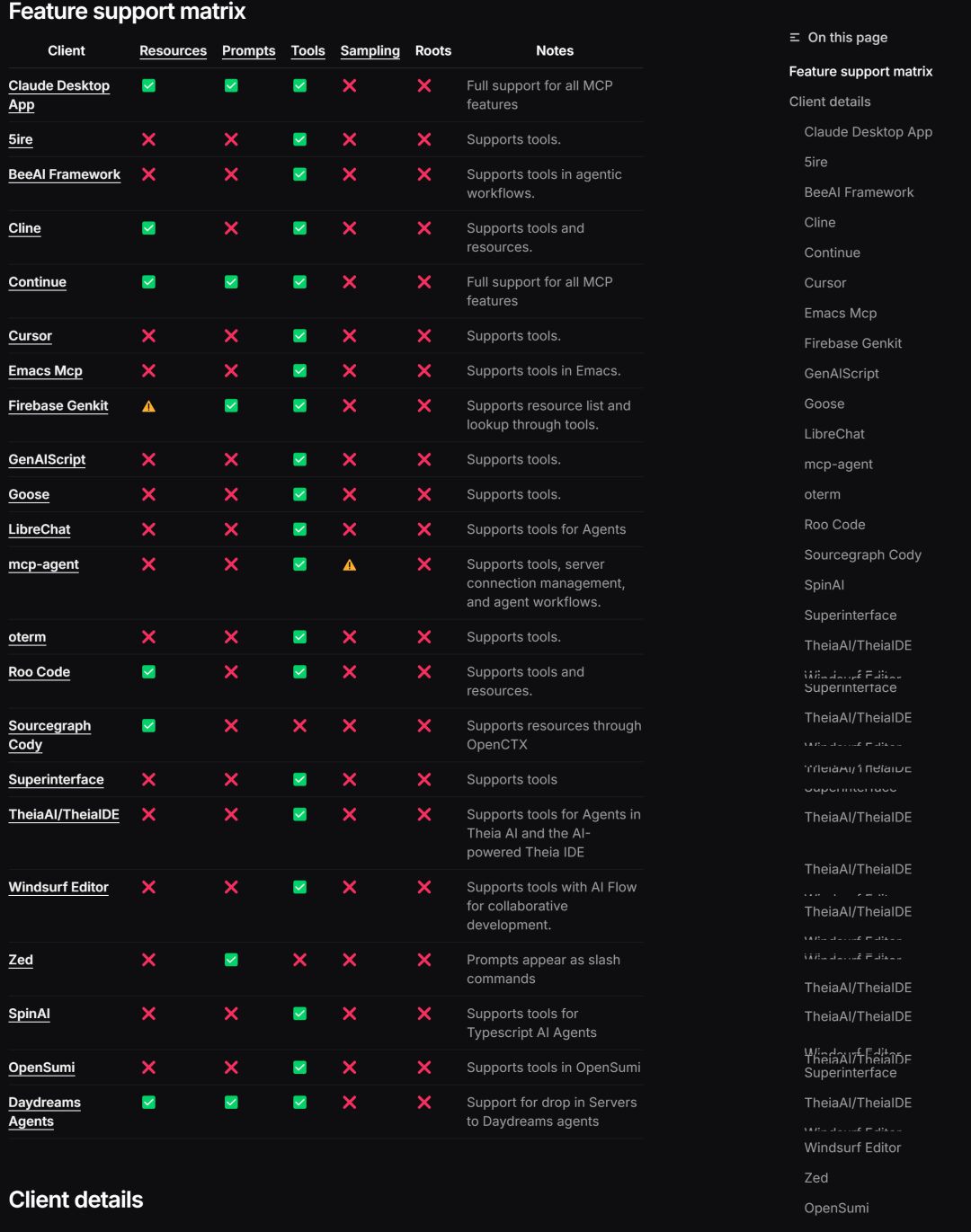
除了能在命令行中创建MCP客户端外,还支持各类客户端的调用:https://modelcontextprotocol.io/clients
3.MCP工具快速接入示例
以下是一个将高德地图导航MCP(服务器)接入Cherry Studio(客户端)的示例:
-
CherryStudio主页:https://github.com/CherryHQ/cherry-studio

-
CherryStudio文档页:https://docs.cherry-ai.com/cherry-studio/download
下载完即可进入对话页面:
然后我们可以将模型切换为DeepSeek官方的模型API:
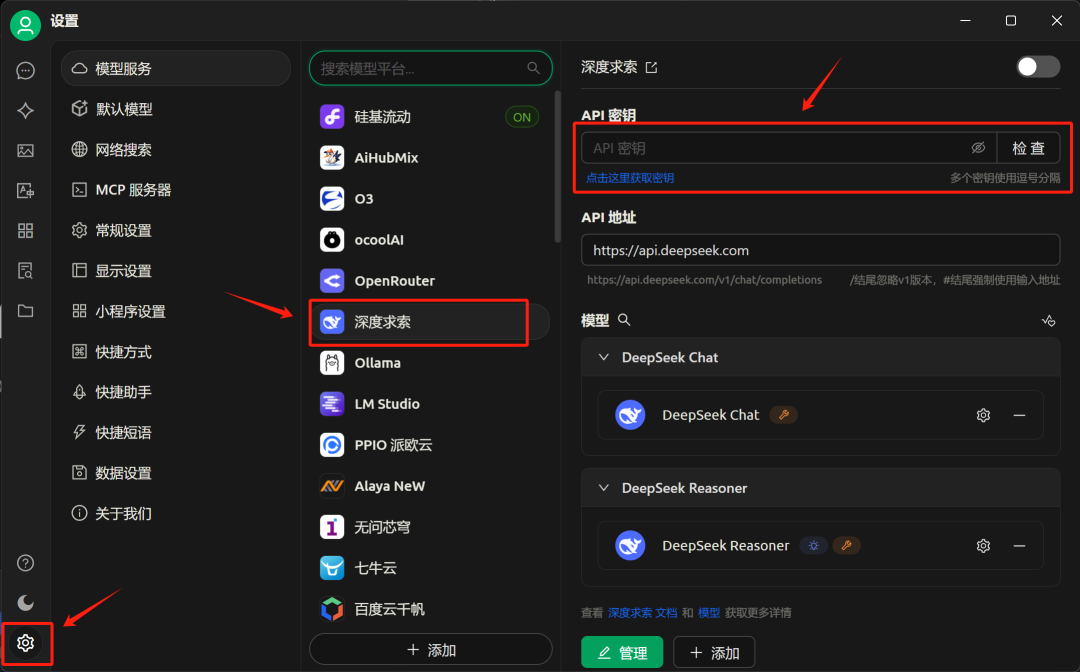
然后开启:
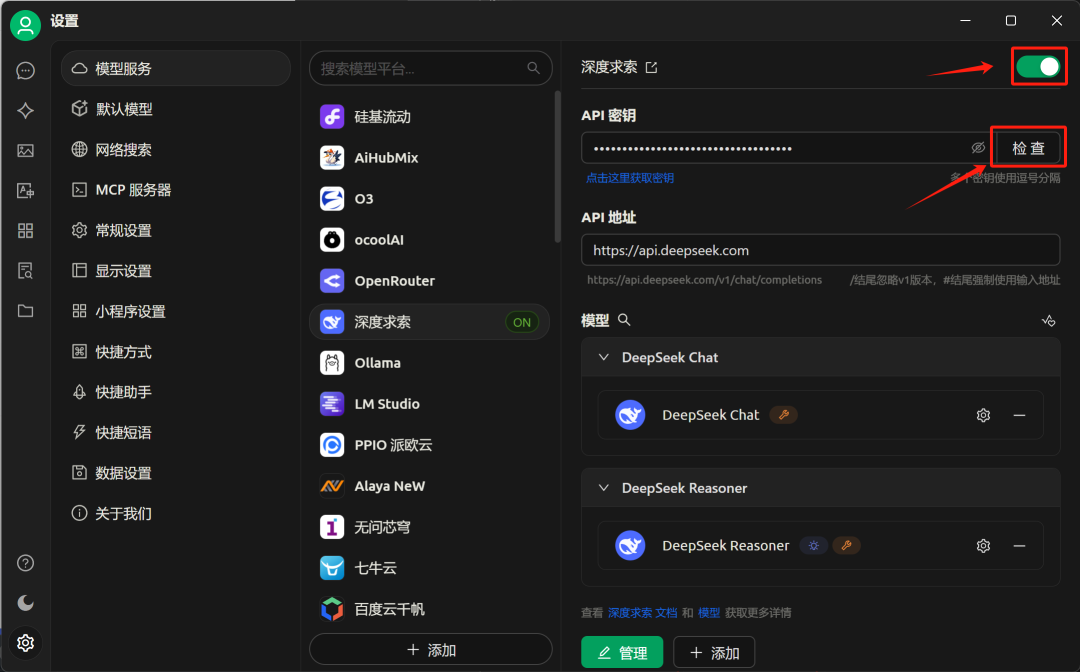
并尝试进行使用:
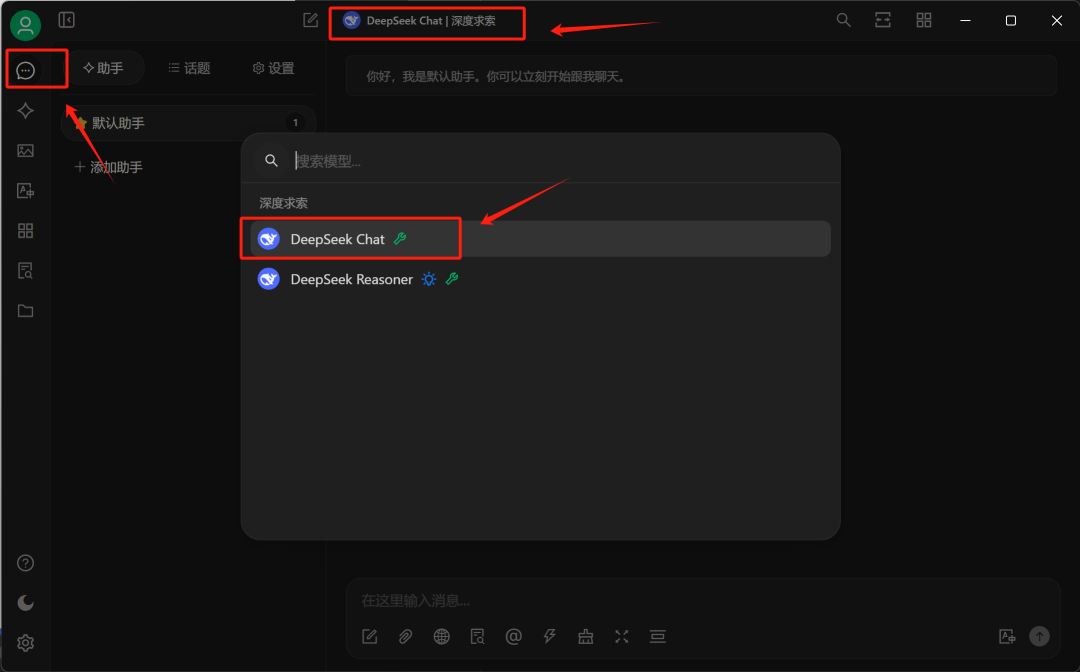
同时,为了能顺利调用MCP工具,我们还需要安装uv和bun文件:
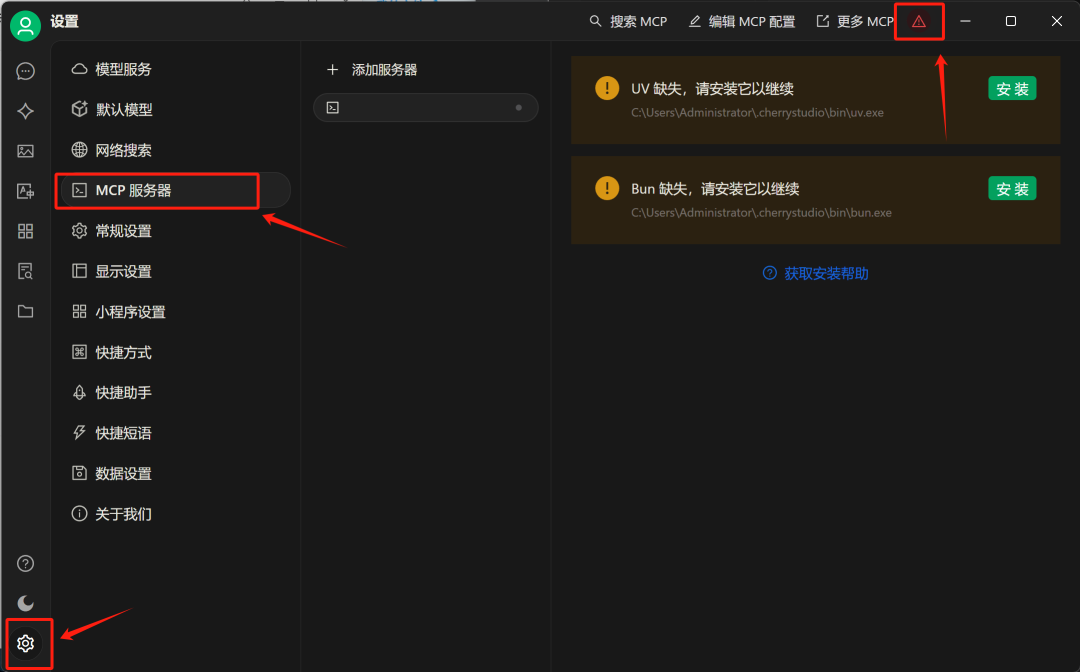
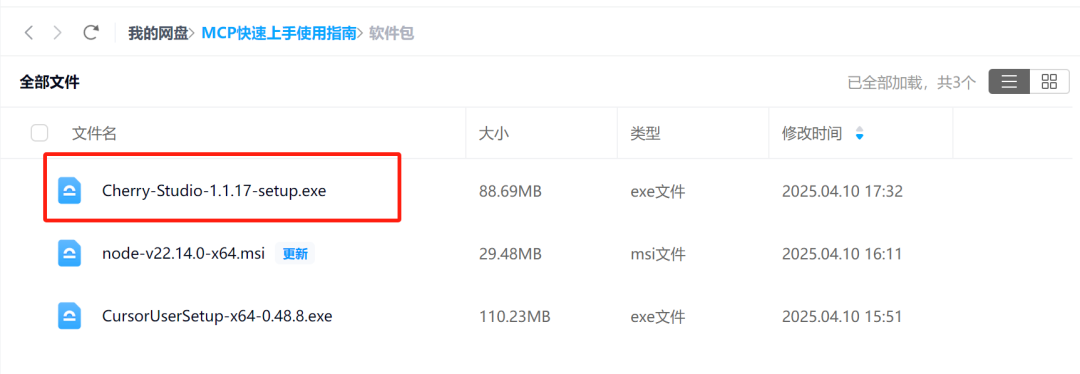
这里推荐最快速的方法是直接从网盘中进行下载:
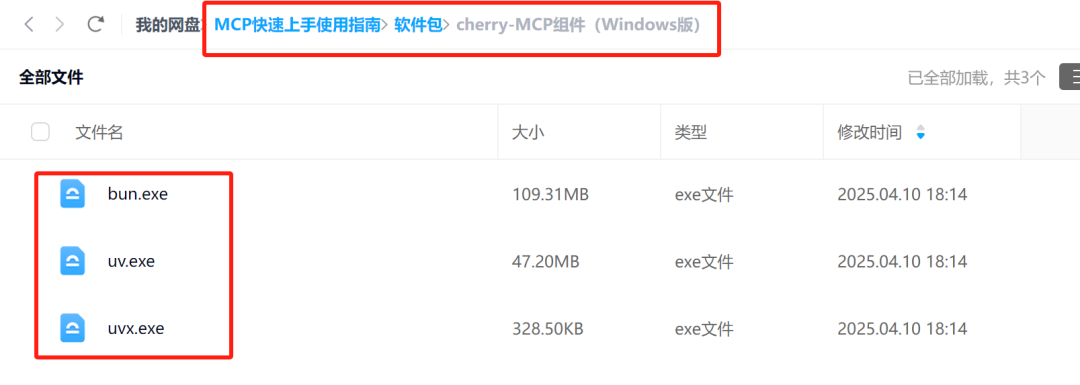
然后在C:\Users{用户名}下创建.cherrystudio\bin目录,并将上面三个.exe文件移入即可。
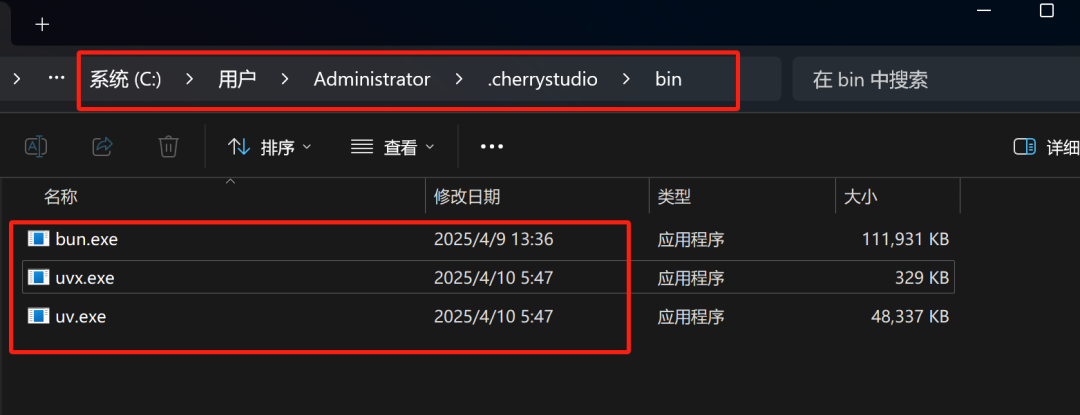
其他操作系统配置详见:https://docs.cherry-ai.com/advanced-basic/mcp/install
-
Cherry Studio接入MCP流程
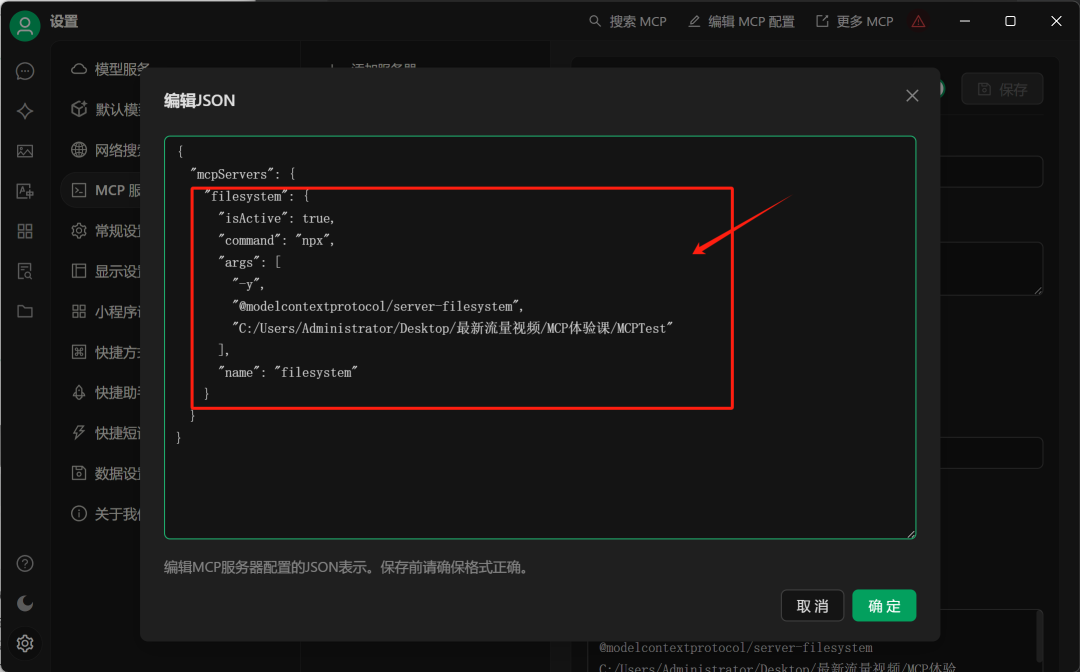
接下来尝试接入filesystem MCP工具:https://github.com/modelcontextprotocol/servers/tree/main/src/filesystem 。
需要在编辑MCP配置页面输入如下内容:
{
"mcpServers": {
"filesystem": {
"isActive": true,
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"C:/Users/Administrator/Desktop/最新流量视频/MCP体验课/MCPTest"
],
"name": "filesystem"
}
}
}
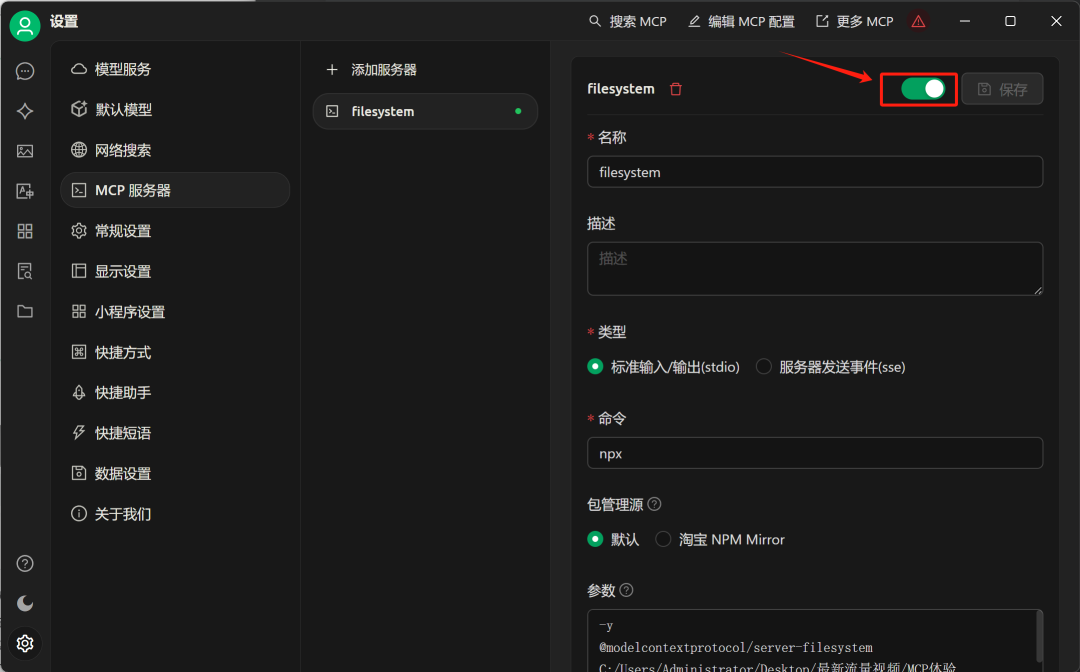
然后点击开启:
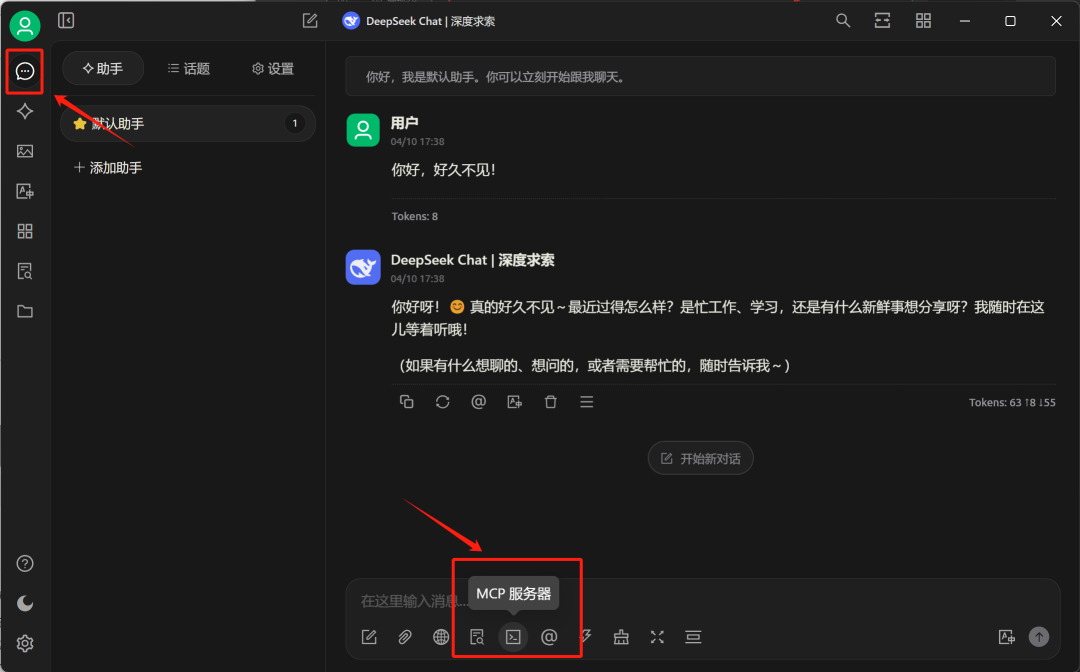
然后在对话中开启MCP工具,这里可选一个或者多个工具:
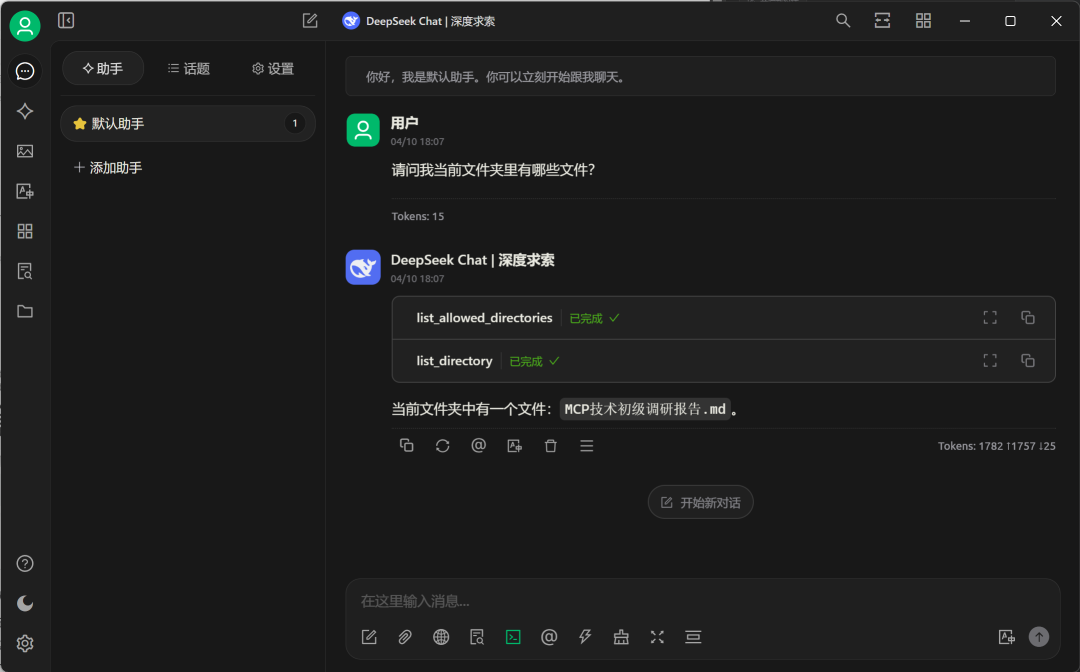
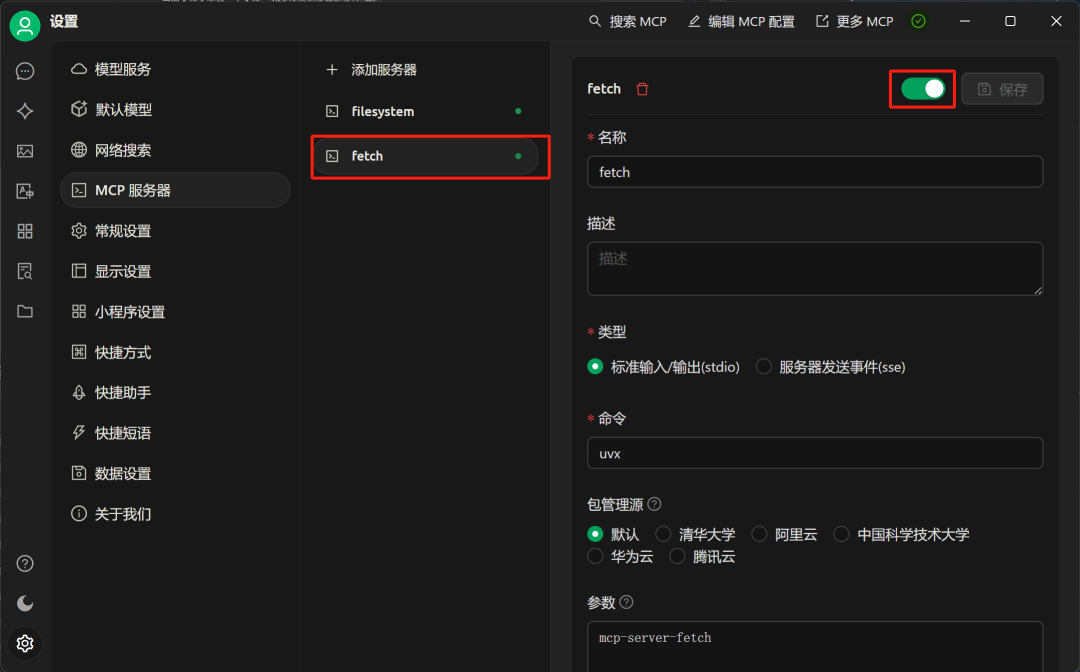
同时再尝试接入fetch MCP工具,https://github.com/modelcontextprotocol/servers/tree/main/src/fetch:
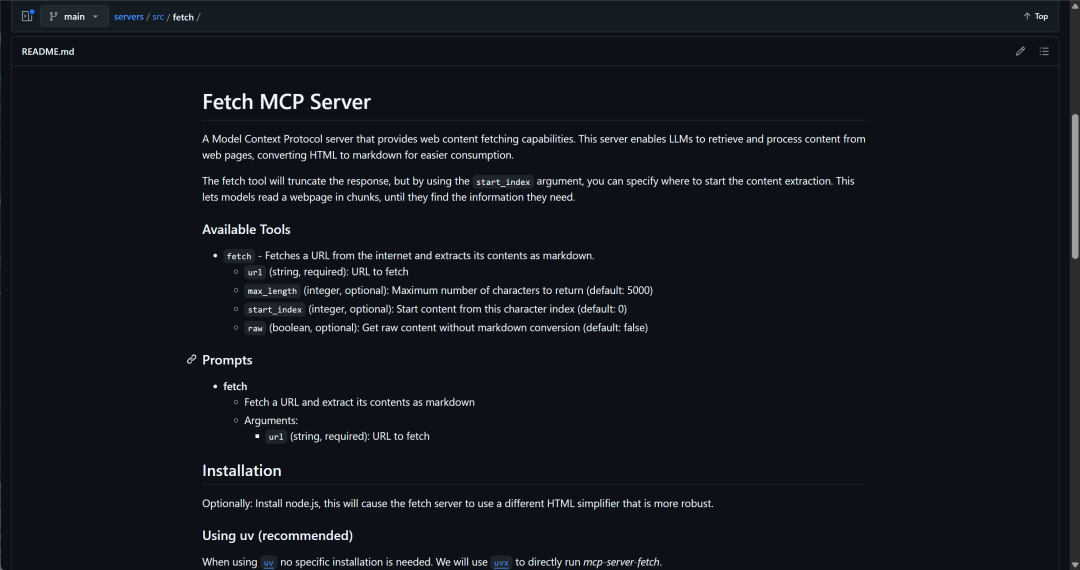
Fetch MCP 服务器是一个遵循模型上下文协议(Model Context Protocol,MCP)的服务器工具,旨在为大型语言模型(LLMs)提供从互联网检索和处理网页内容的能力。通过将网页的 HTML 内容转换为 Markdown 格式,Fetch MCP 使得 LLMs 能够更高效地理解和利用网页信息。
主要功能:
-
网页内容获取与转换:Fetch MCP 提供了 fetch 工具,可从指定的 URL 获取网页内容,并将其提取为 Markdown 格式,方便 LLMs 消化和处理。
-
支持多种内容格式:除了 Markdown,Fetch MCP 还支持获取网页的 HTML、JSON 和纯文本格式,满足不同应用场景的需求。
-
内容截取与分页:通过 start_index 参数,用户可以指定从网页内容的特定位置开始提取,允许模型分段读取网页,直到找到所需信息。
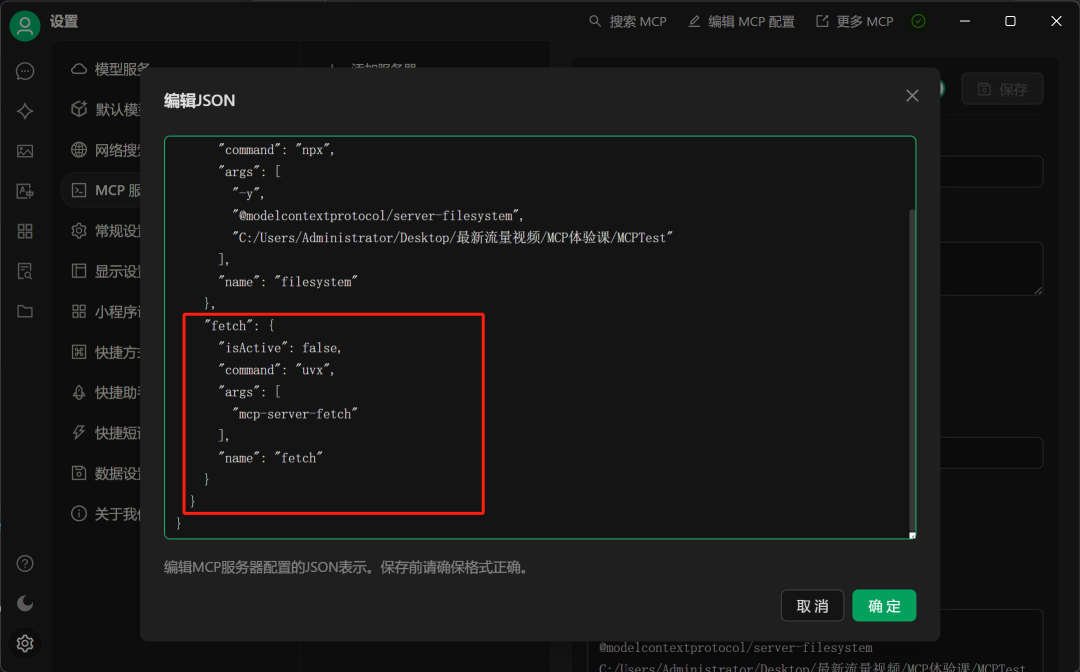
同样我们需要在MCP配置页面写入如下内容
"fetch": {
"command": "uvx",
"args": ["mcp-server-fetch"]
}
然后开启工具:
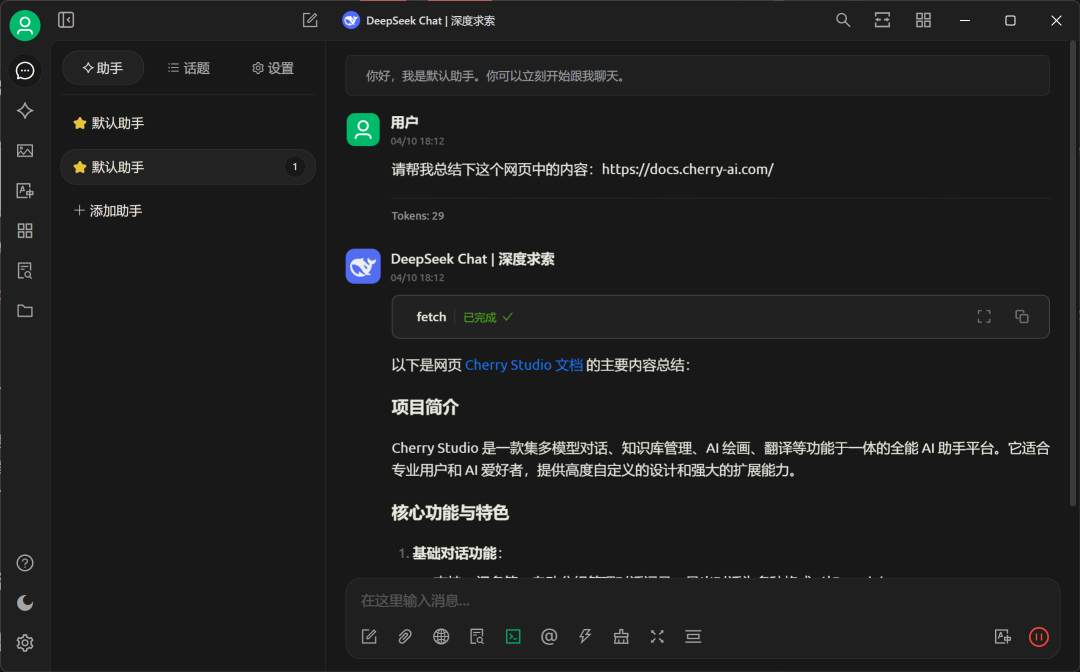
并尝试进行调用:
全套代码、相关软件和参考资料已上线至赋范大模型技术社区⬇️。

二、MCP服务器标准调用流程
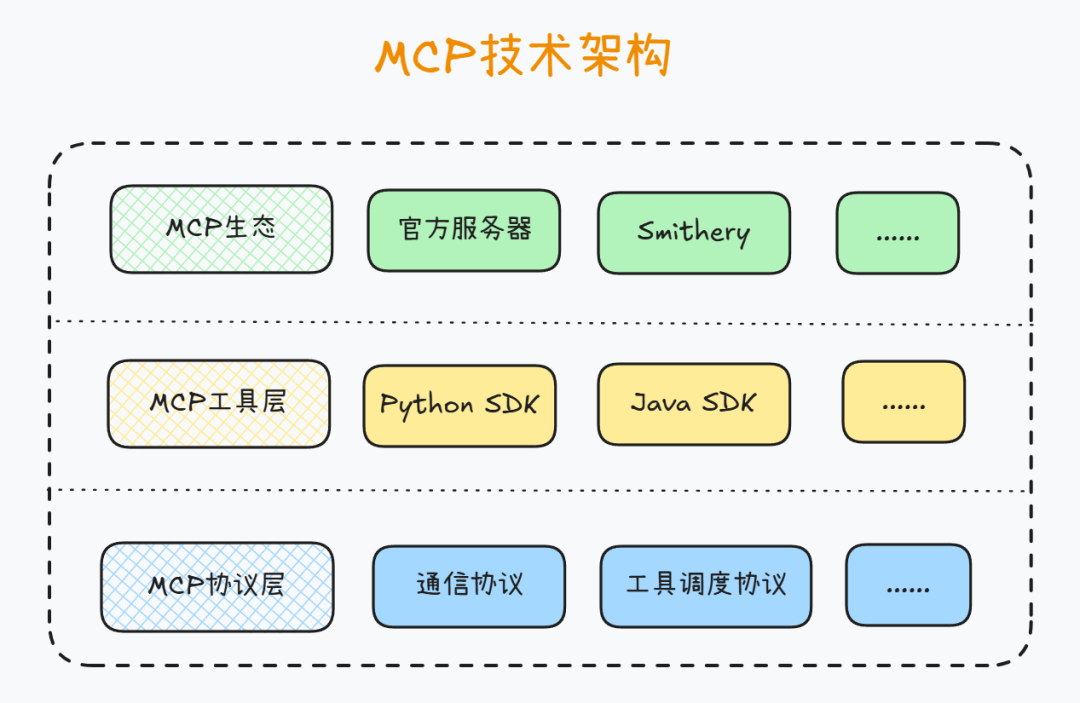
1.MCP技术生态介绍
MCP基础技术生态结构如下所示。
1.1 MCP通信协议介绍
MCP(Model Context Protocol)是一种为了统一大规模模型和工具间通信而设计的协议,它定义了消息格式和通信方式。MCP 协议支持多种传输机制,其中包括 stdio、Server-Sent Events(SSE) 和 Streamable HTTP。每种通信方法在不同的应用场景中具有不同的优劣势,适用于不同的需求。
1.1.1 Stdio 传输(Standard Input/Output)
stdio 传输方式是最简单的通信方式,通常在本地工具之间进行消息传递时使用。它利用标准输入输出(stdin/stdout)作为数据传输通道,适用于本地进程间的交互。
-
工作方式:客户端和服务器通过标准输入输出流(stdin/stdout)进行通信。客户端向服务器发送命令和数据,服务器执行并通过标准输出返回结果。
-
应用场景:适用于本地开发、命令行工具、调试环境,或者模型和工具服务在同一进程内运行的情况。
1.1.2 Server-Sent Events(SSE)
SSE 是基于 HTTP 协议的流式传输机制,它允许服务器通过 HTTP 单向推送事件到客户端。SSE 适用于客户端需要接收服务器推送的场景,通常用于实时数据更新。
-
工作方式:客户端通过 HTTP GET 请求建立与服务器的连接,服务器以流式方式持续向客户端发送数据,客户端通过解析流数据来获取实时信息。
-
应用场景:适用于需要服务器主动推送数据的场景,如实时聊天、天气预报、新闻更新等。
1.1.3 Streamable HTTP
-
MCP更新公告:https://modelcontextprotocol.io/development/updates
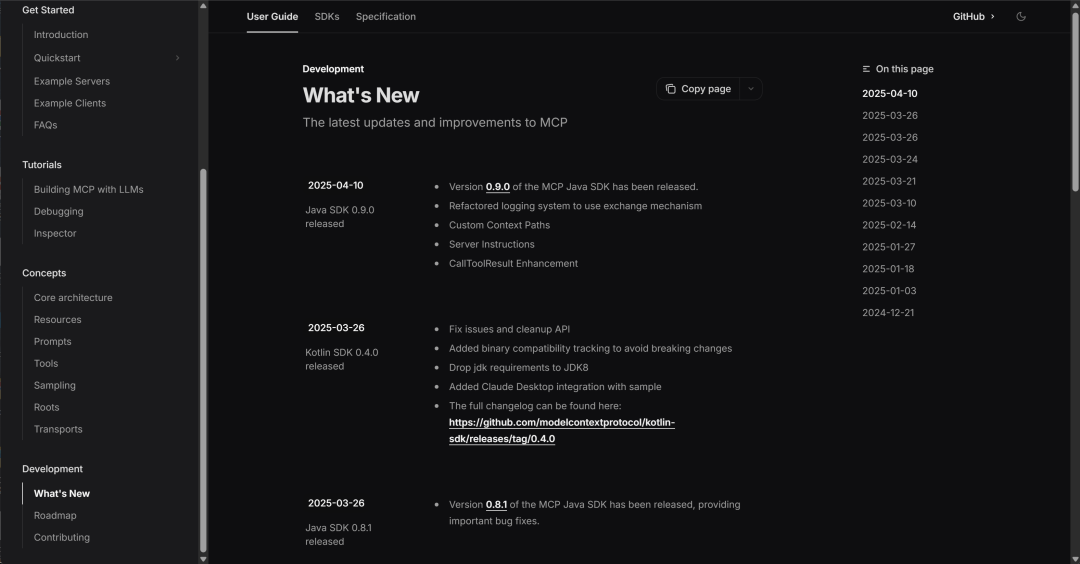
-
Streamable HTTP更新公告:https://github.com/modelcontextprotocol/modelcontextprotocol/blob/main/docs/specification/2025-03-26/basic/transports.mdx#streamable-http
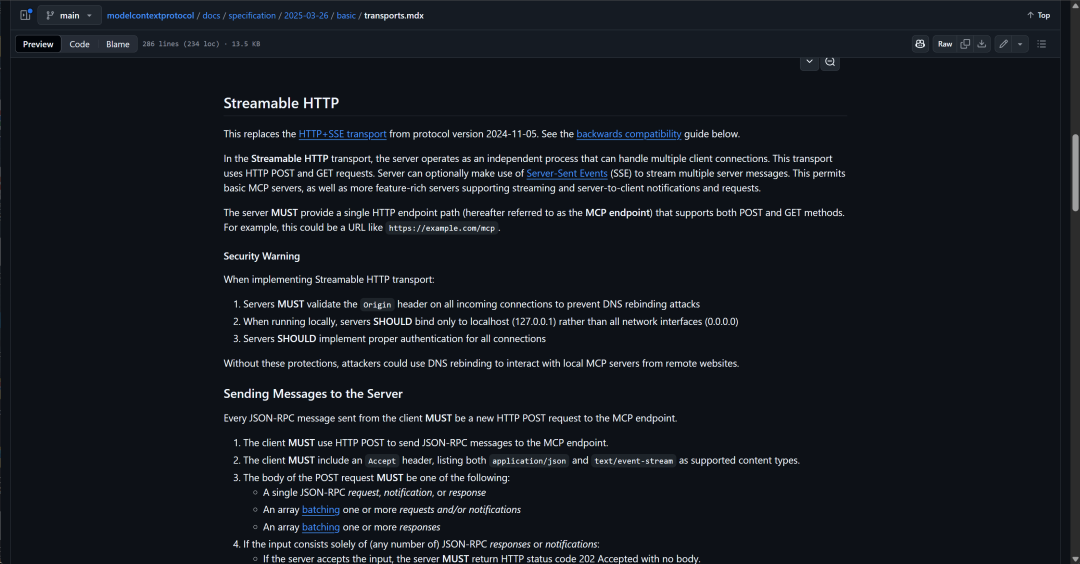
Streamable HTTP 是 MCP 协议中新引入的一种传输方式,它基于 HTTP 协议支持双向流式传输。与传统的 HTTP 请求响应模型不同,Streamable HTTP 允许服务器在一个长连接中实时向客户端推送数据,并且可以支持多个请求和响应的流式传输。
不过需要注意的是,MCP只提供了Streamable HTTP协议层的支持,也就是规范了MCP客户端在使用Streamable HTTP通信时的通信规则,而并没有提供相关的SDK客户端。开发者在开发Streamable HTTP机制下的客户端和服务器时,可以使用比如Python httpx库进行开发。
-
工作方式:客户端通过 HTTP POST 向服务器发送请求,并可以接收流式响应(如 JSON-RPC 响应或 SSE 流)。当请求数据较多或需要多次交互时,服务器可以通过长连接和分批推送的方式进行数据传输。
-
应用场景:适用于需要支持高并发、低延迟通信的分布式系统,尤其是跨服务或跨网络的应用。适合高并发的场景,如实时流媒体、在线游戏、金融交易系统等。
1.1.4 MCP 传输方式优劣势对比
| 特性 | Stdio | SSE | Streamable HTTP |
| 通信方向 | 双向(但仅限本地) | 单向(服务器到客户端) | 双向(适用于复杂交互) |
| 使用场景 | 本地进程间通信 | 实时数据推送,浏览器支持 | 跨服务、分布式系统、大规模并发支持 |
| 支持并发连接数 | 低 | 中等 | 高(适合大规模并发) |
| 适应性 | 局限于本地环境 | 支持浏览器,但单向通信 | 高灵活性,支持流式数据与请求批处理 |
| 实现难度 | 简单,适合本地调试 | 简单,但浏览器兼容性和长连接限制 | 复杂,需处理长连接和流管理 |
| 适合的业务类型 | 本地命令行工具,调试环境 | 实时推送,新闻、股票等实时更新 | 高并发、分布式系统,实时交互系统 |
三种传输方式总结如下:
-
Stdio 传输:适合本地进程之间的简单通信,适合命令行工具或调试阶段,但不支持分布式。
-
SSE 传输:适合实时推送和客户端/浏览器的单向通知,但无法满足双向复杂交互需求。
-
Streamable HTTP 传输:最灵活、最强大的选项,适用于大规模并发、高度交互的分布式应用系统,虽然实现较复杂,但能够处理更复杂的场景。
1.2 MCP SDK介绍
截至目前,MCP SDK已支持Python、TypeScript、Java、Kotlin和C#等编程语言进行客户端和服务器创建。
2. MCP服务器标准接入流程
2.1 MCP服务器基本接入流程
一个标准的MCP工具接入客户端流程如图所示:

这种通过 JSON 配置文件 来定义服务的启动命令(如 npx、python、node 等),是一个通用且可扩展的方式。只要在配置文件中指定合适的命令、参数和环境变量,MCP 服务就可以根据配置启动,并与其他服务进行交互。例如配置文件定义了一个 filesystem MCP服务:
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"C:\\Users\\username\\Desktop",
"C:\\Users\\username\\Downloads"
]
}
}
}-
mcpServers:根节点,包含所有 MCP 服务的定义。
-
filesystem:服务名称,可以是任意标识符,表示这个 MCP 服务的类型或功能。
-
command:用于启动服务的命令,这里是 npx,表示使用 npx 来执行某个工具或包。
-
args:命令参数列表,具体用于启动该服务的工具或进程。@modelcontextprotocol/server-filesystem 是指定的 MCP 工具包,后面跟着的是路径参数,表示要处理的文件夹或目录。
这种通过修改配置文件的方式具有较强的通用性和灵活性:
-
服务类型不限:可以根据不同的服务需求,替换 command 和 args 部分。比如:
-
对于文件系统服务,可以使用 server-filesystem;
-
对于其他服务(如数据库、Web 服务器等),也可以使用相应的工具包(如 npx、python、node 等)来启动。
-
-
灵活的路径和环境配置:可以根据需要指定不同的目录或资源路径作为服务的启动参数。
-
示例中使用的是路径 C:\\Users\\username\\Desktop 和 C:\\Users\\username\\Downloads,这可以是任何需要由 MCP 服务处理的路径。
-
-
支持多服务配置:可以在同一个配置文件中定义多个服务。例如:
{
"mcpServers": {
"filesystem": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"C:\\Users\\username\\Desktop"
]
},
"database": {
"command": "python",
"args": [
"server_database.py",
"--db-path",
"C:\\Users\\username\\Data"
]
}
}
}-
这样,你可以同时启动多个不同类型的 MCP 服务,满足多种需求。
-
与外部工具集成:通过这种方式,你还可以将 MCP 服务与外部工具结合,比如运行 Python 脚本、Node.js 工具包,甚至其他命令行工具,只需要在配置文件中定义相应的启动命令和参数即可。
需要注意的是,这种配置MCP工具的方法也正是MCP官方说明文档中推荐的配置方法:https://modelcontextprotocol.io/quickstart/user#windows
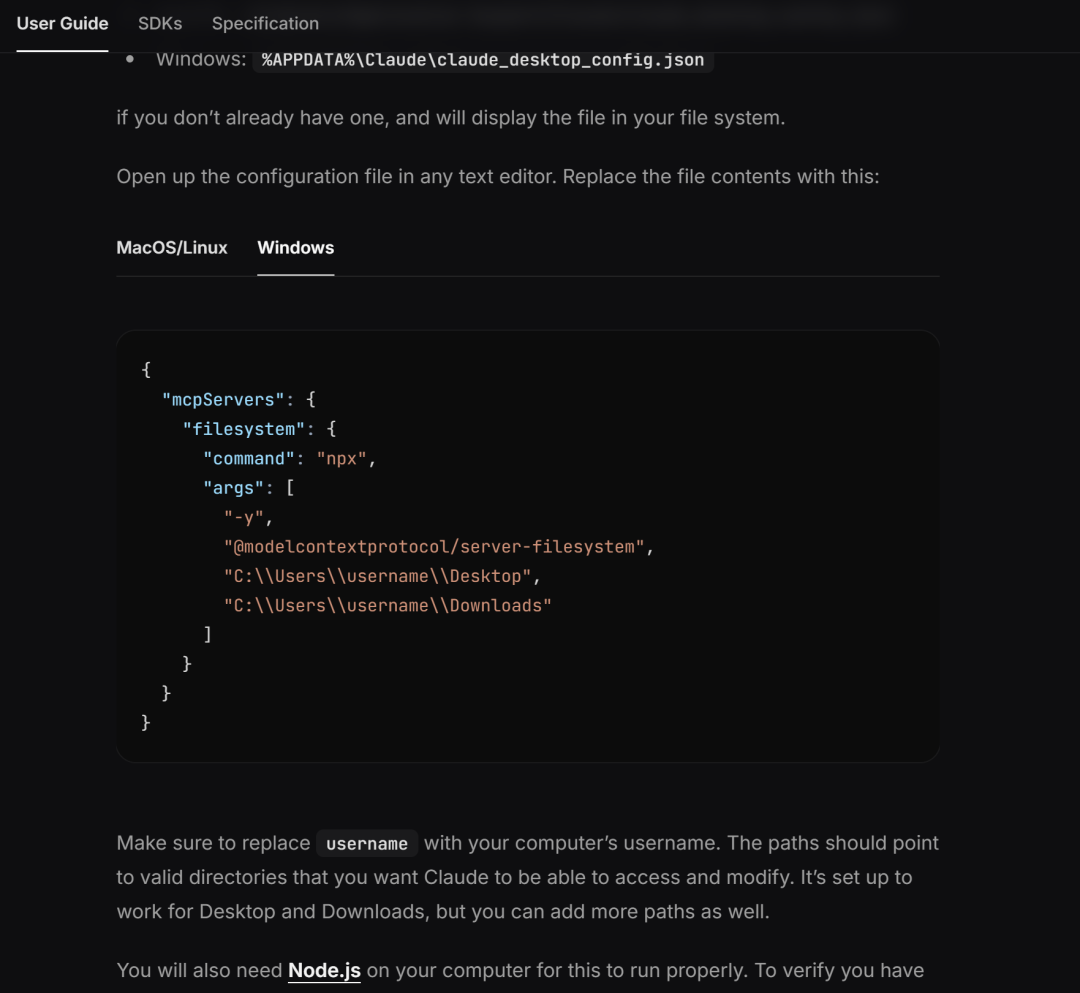
同时也是目前主流客户端如Cursor、Clien等配置MCP服务器的基本方法:
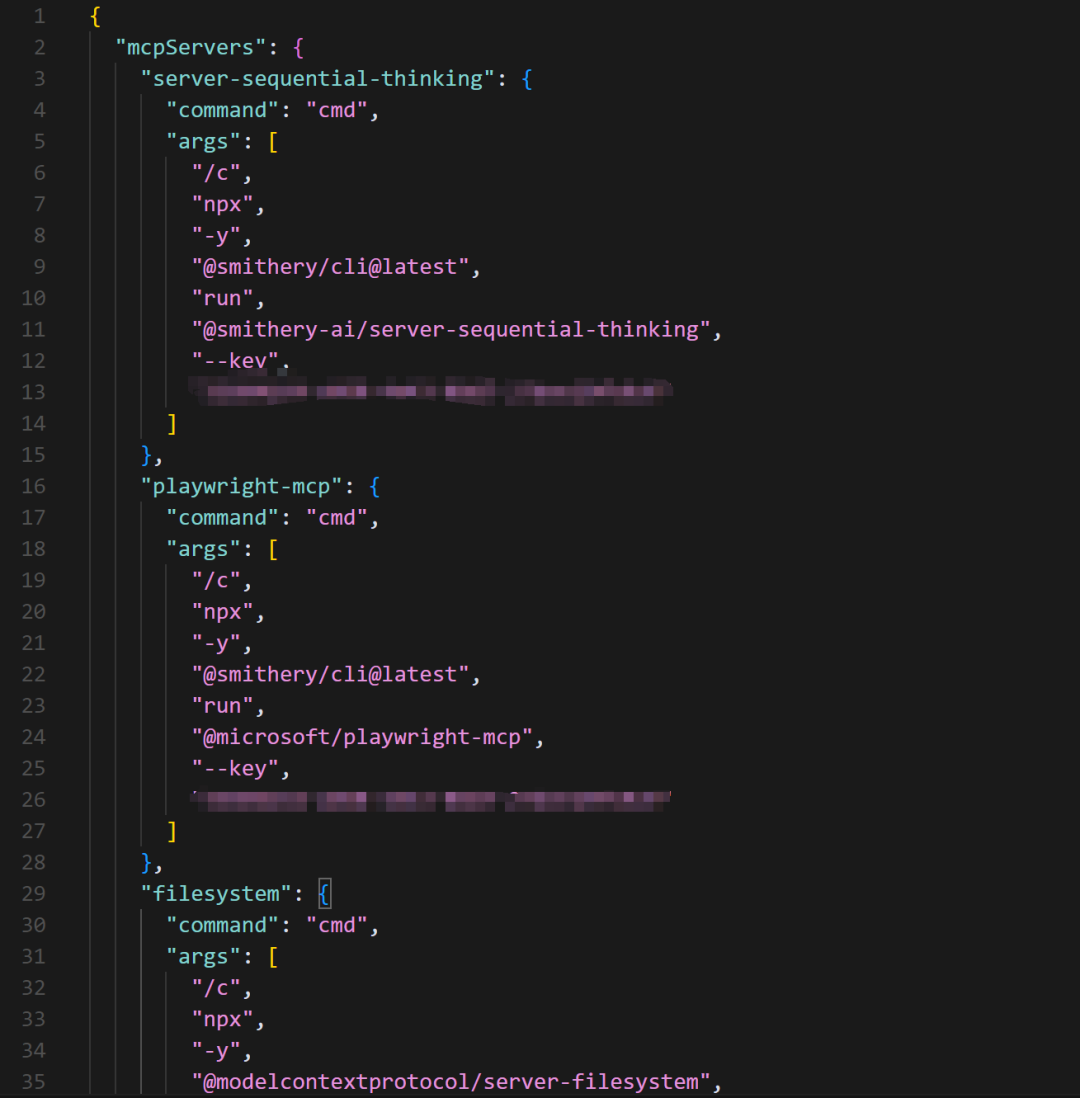
同时也是目前主流的MCP平台所支持的调用方法:
-
smithery:
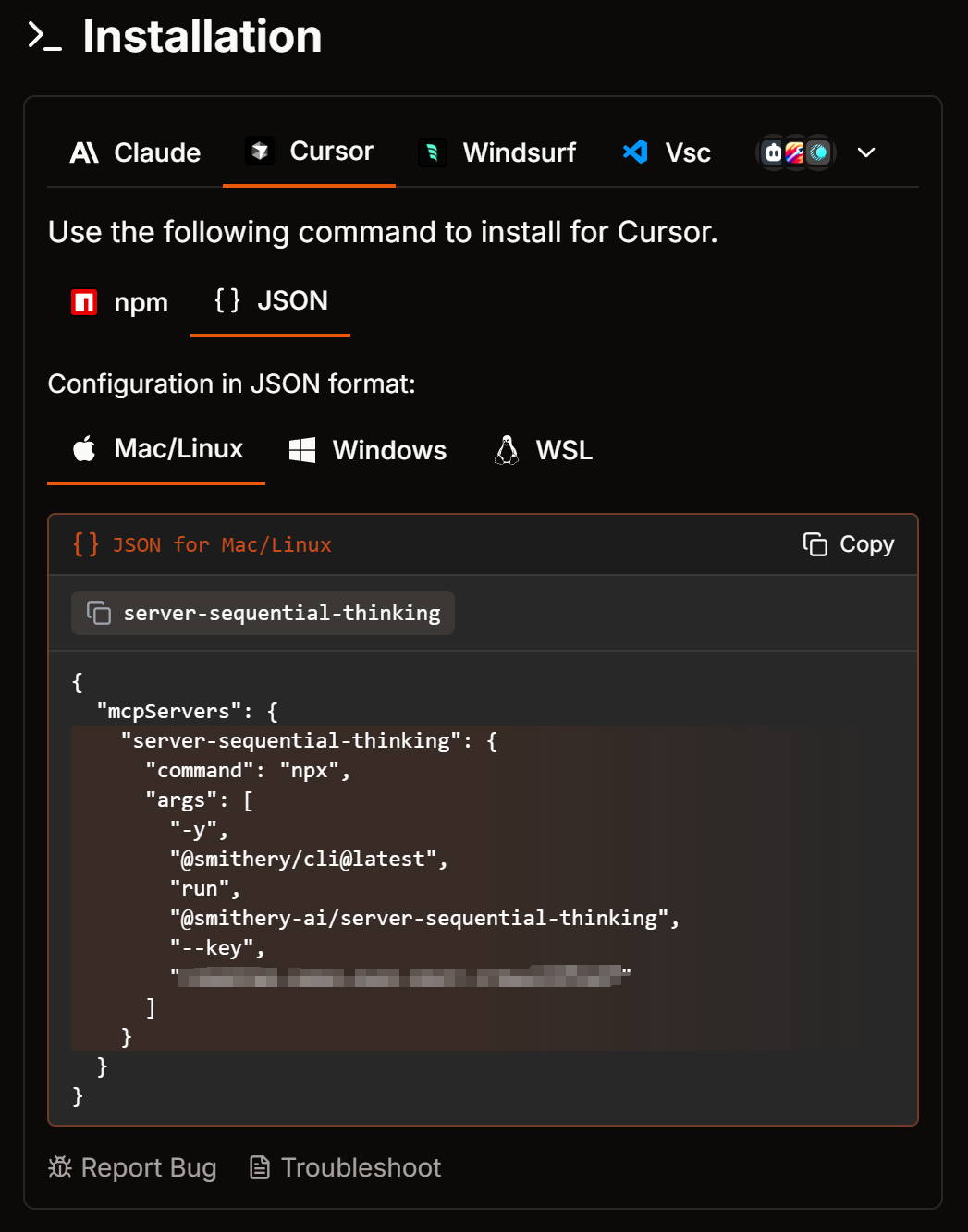
-
mcp.so
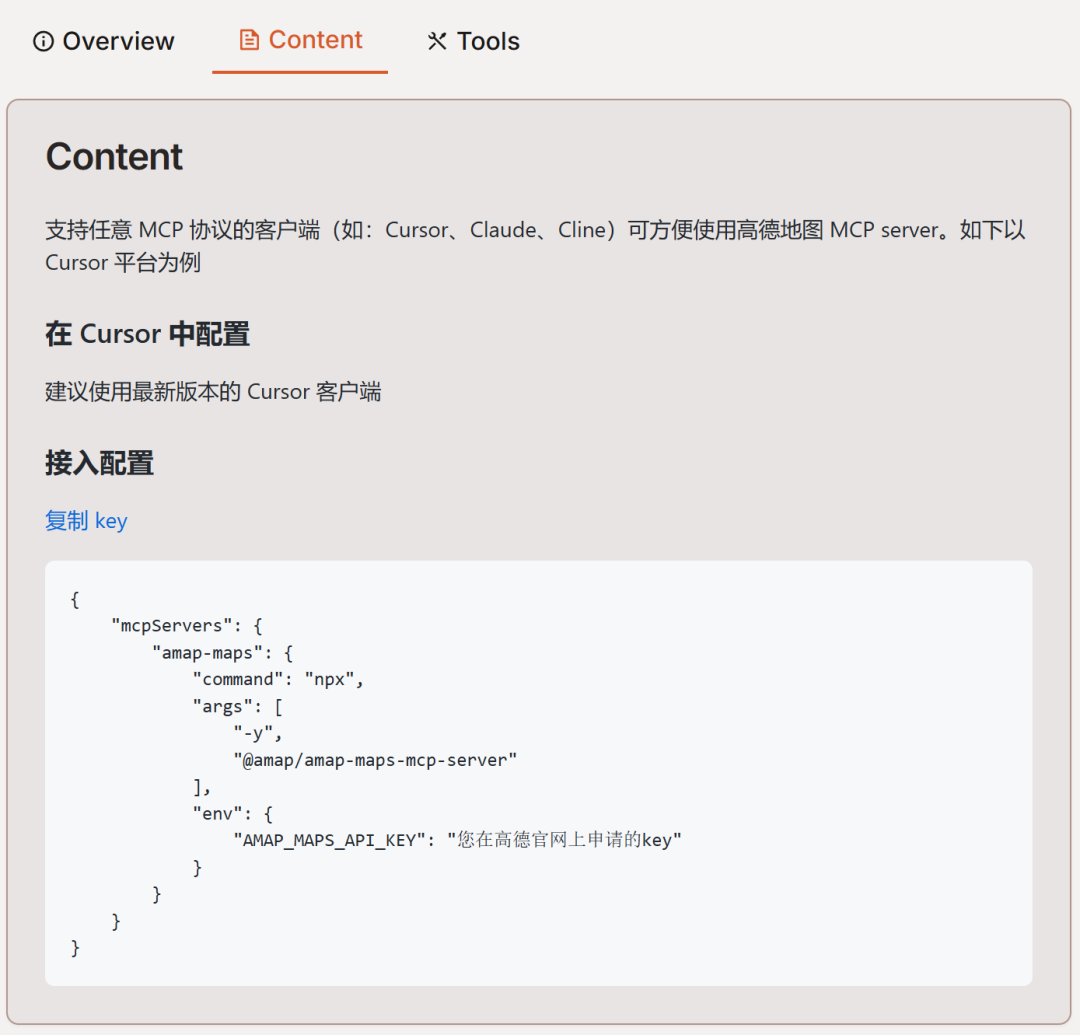
GitHub MCP官方合集:
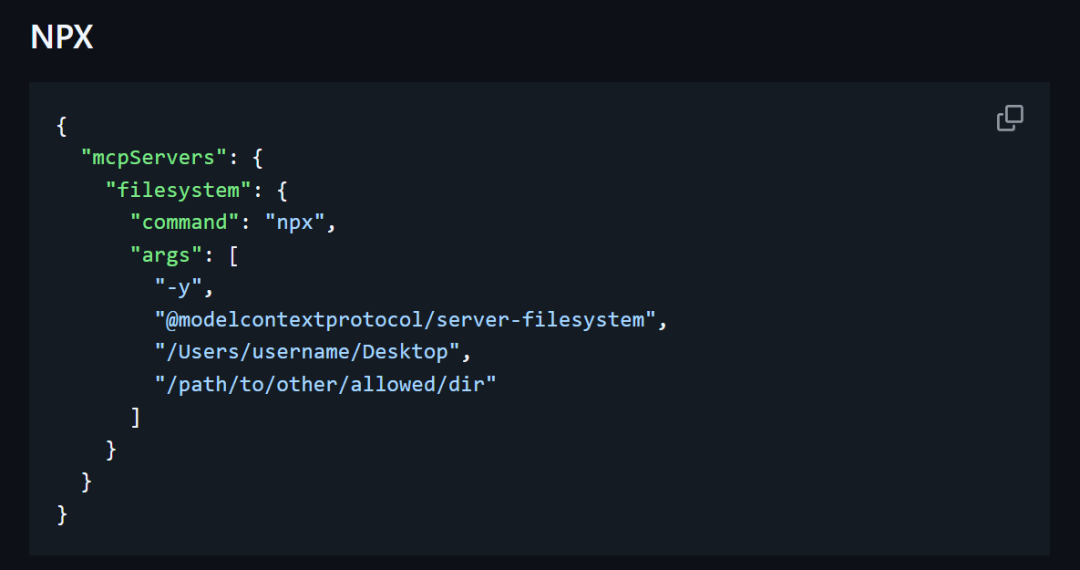
总的来说,这种配置方法是 MCP 协议的标准方式,它通过灵活的配置文件使得服务的启动、管理和扩展变得更加简便和通用。无论是启动本地工具服务,还是部署复杂的分布式系统,MCP 都可以通过这样的 JSON 配置文件来灵活应对各种应用场景。
2.2 MCP工具配置文件命令行等价形式
需要注意的是,在这个 JSON 配置文件中,npx 命令的本质就是 执行一个命令行工具,并且在首次运行时会自动下载和执行所指定的工具或库。如果该工具没有被缓存,npx 会自动从 npm registry 下载并执行它。
具体来说,这个配置文件中的 npx 命令:
{
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"C:\\Users\\username\\Desktop",
"C:\\Users\\username\\Downloads"
]
}-
npx:
-
npx 是 Node.js 自带的工具,目的是用来执行命令行工具或 Node.js 包。如果本地没有安装该工具,npx 会临时下载并执行该工具。
-
-
@modelcontextprotocol/server-filesystem:
-
这是一个 npm 包,当你执行这个命令时,npx 会检查本地是否已经安装了该包。
-
如果本地没有安装该包,npx 会自动从 npm registry 下载这个包并执行。
-
@modelcontextprotocol/server-filesystem 是用来启动一个 MCP 文件系统工具的包,它根据给定的路径来提供文件系统的接口。
-
-
-y:
-
这是 npx 的一个参数,表示自动接受所有的提示(通常是用于跳过安装时的确认提示)。
-
-
路径参数:
-
C:\\Users\\username\\Desktop 和 C:\\Users\\username\\Downloads 是该命令运行时需要的参数,告诉 server-filesystem 工具它应该操作的文件夹路径。
-
因此,实际运行时会执行如下等价命令:
npx -y @modelcontextprotocol/server-filesystem C:\\Users\\username\\Desktop C:\\Users\\username\\Downloads而在首次运行时:
-
npx 会从 npm registry 下载 @modelcontextprotocol/server-filesystem 库。
-
这个包会被下载到一个 临时缓存目录,并执行相关的命令。
-
运行完成后,npx 会自动删除临时下载的文件,但工具的执行过程会继续。
后续运行时的行为:
-
如果你再次运行相同的命令,npx 会首先检查本地是否已缓存该包。
-
如果该工具包已经存在于缓存中,npx 会直接从缓存中提取并执行,而不会再次从网络上下载。
-
只有当工具包不存在或版本发生变化时,npx 才会重新下载并执行。
也就是说,从表面上来看,我们是填写了MCP工具就能使一些客户端自动连接MCP服务器,实际上是首次运行的时候,MCP客户端会先下载这些MCP服务器,然后开启一个子进程运行这个服务器,从而使得客户端随时可以调用其服务。
同时需要注意的是这种配置文件设置方法,肯定也是支持离线脚本运行的,我们也可以直接将写好的脚本上传到服务器中,然后指定本地路径进行运行。
3. MCP服务器类型介绍
根据MCP协议定义,Server可以提供三种类型的标准能力,Resources、Tools、Prompts,每个Server可同时提供者三种类型能力或其中一种。
-
**Resources:**资源,类似于文件数据读取,可以是文件资源或是API响应返回的内容。比如
-
**Tools:**工具,第三方服务、功能函数,通过此可控制LLM可调用哪些函数。
-
**Prompts:**提示词,为用户预先定义好的完成特定任务的模板。
4.MCP开发基础环境搭建
4.1 uv入门介绍
MCP开发要求借助uv进行虚拟环境创建和依赖管理。uv 是一个Python 依赖管理工具,类似于 pip 和 conda,但它更快、更高效,并且可以更好地管理 Python 虚拟环境和依赖项。它的核心目标是替代 pip、venv 和 pip-tools,提供更好的性能和更低的管理开销。
uv 的特点:
-
速度更快:相比 pip,uv 采用 Rust 编写,性能更优。
-
支持 PEP 582:无需 virtualenv,可以直接使用 __pypackages__ 进行管理。
-
兼容 pip:支持 requirements.txt 和 pyproject.toml 依赖管理。
-
替代 venv:提供 uv venv 进行虚拟环境管理,比 venv 更轻量。
-
跨平台:支持 Windows、macOS 和 Linux。
4.2 uv安装流程
方法 1:使用 pip 安装(适用于已安装 pip 的系统)
pip install uv方法 2:使用 curl 直接安装
如果你的系统没有 pip,可以直接运行:
curl -LsSf https://astral.sh/uv/install.sh | sh这会自动下载 uv 并安装到 /usr/local/bin。
4.3 uv的基本用法介绍
安装 uv 后,你可以像 pip 一样使用它,但它的语法更简洁,速度也更快。注意,以下为使用语法示例,不用实际运行。
-
安装 Python 依赖
uv pip install requests与 pip install requests 类似,但更快。
-
创建虚拟环境
uv venv myenv等效于 python -m venv myenv,但更高效。
-
激活虚拟环境
source myenv/bin/activate # Linux/macOS
myenv\Scripts\activate # Windows-
安装 requirements.txt
uv pip install -r requirements.txt-
直接运行 Python 项目
如果项目中包含 pyproject.toml,你可以直接运行:
uv run python script.py这等效于:
pip install -r requirements.txt
python script.py但 uv 速度更快,管理更高效。
接下来我们就按照标准格式尝试先构建一个 MCP 客户端和服务器。
三、按照标准流程搭建MCP客户端与服务器
1.Server搭建流程
这里我们尝试一个入门级的示例,那就是创建一个天气查询的服务器。通过使用OpenWeather API,创建一个能够实时查询天气的服务器(server),并使用stdio方式进行通信。

测试查询效果
curl -s "https://api.openweathermap.org/data/2.5/weather?q=Beijing&appid='YOUR_API_KEY'&units=metric&lang=zh_cn"
测试无误后,接下来即可进入到创建server的环节中。
3. 天气查询服务器Server创建流程
1.1 服务器依赖安装
由于我们需要使用http请求来查询天气,因此需要在当前虚拟环境中添加如下依赖
uv add mcp httpx3.2 服务器代码编写
接下来尝试创建服务器代码,此时MCP基本执行流程如下:
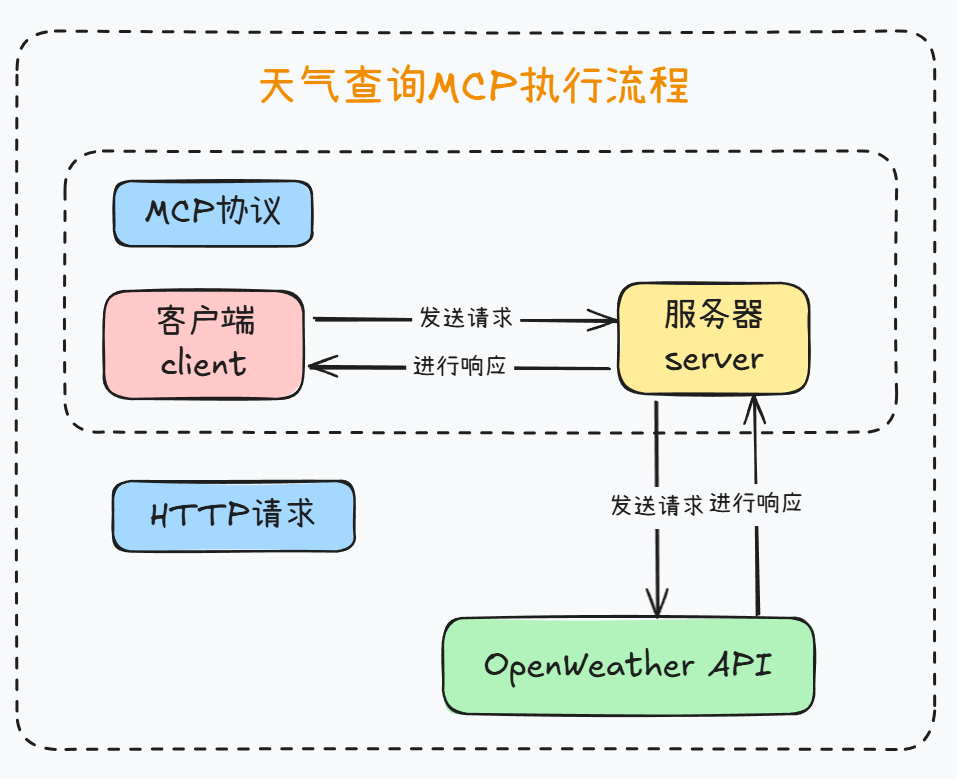
对应server服务器代码如下:
import json
import httpx
from typing import Any
from mcp.server.fastmcp import FastMCP
# 初始化 MCP 服务器
mcp = FastMCP("WeatherServer")
# OpenWeather API 配置
OPENWEATHER_API_BASE = "https://api.openweathermap.org/data/2.5/weather"
API_KEY = "YOUR_API_KEY" # 请替换为你自己的 OpenWeather API Key
USER_AGENT = "weather-app/1.0"
async def fetch_weather(city: str) -> dict[str, Any] | None:
"""
从 OpenWeather API 获取天气信息。
:param city: 城市名称(需使用英文,如 Beijing)
:return: 天气数据字典;若出错返回包含 error 信息的字典
"""
params = {
"q": city,
"appid": API_KEY,
"units": "metric",
"lang": "zh_cn"
}
headers = {"User-Agent": USER_AGENT}
async with httpx.AsyncClient() as client:
try:
response = await client.get(OPENWEATHER_API_BASE, params=params, headers=headers, timeout=30.0)
response.raise_for_status()
return response.json() # 返回字典类型
except httpx.HTTPStatusError as e:
return {"error": f"HTTP 错误: {e.response.status_code}"}
except Exception as e:
return {"error": f"请求失败: {str(e)}"}
def format_weather(data: dict[str, Any] | str) -> str:
"""
将天气数据格式化为易读文本。
:param data: 天气数据(可以是字典或 JSON 字符串)
:return: 格式化后的天气信息字符串
"""
# 如果传入的是字符串,则先转换为字典
if isinstance(data, str):
try:
data = json.loads(data)
except Exception as e:
return f"无法解析天气数据: {e}"
# 如果数据中包含错误信息,直接返回错误提示
if "error" in data:
return f"⚠️ {data['error']}"
# 提取数据时做容错处理
city = data.get("name", "未知")
country = data.get("sys", {}).get("country", "未知")
temp = data.get("main", {}).get("temp", "N/A")
humidity = data.get("main", {}).get("humidity", "N/A")
wind_speed = data.get("wind", {}).get("speed", "N/A")
# weather 可能为空列表,因此用 [0] 前先提供默认字典
weather_list = data.get("weather", [{}])
description = weather_list[0].get("description", "未知")
return (
f"🌍 {city}, {country}\n"
f"🌡 温度: {temp}°C\n"
f"💧 湿度: {humidity}%\n"
f"🌬 风速: {wind_speed} m/s\n"
f"🌤 天气: {description}\n"
)
@mcp.tool()
async def query_weather(city: str) -> str:
"""
输入指定城市的英文名称,返回今日天气查询结果。
:param city: 城市名称(需使用英文)
:return: 格式化后的天气信息
"""
data = await fetch_weather(city)
return format_weather(data)
if __name__ == "__main__":
# 以标准 I/O 方式运行 MCP 服务器
mcp.run(transport='stdio')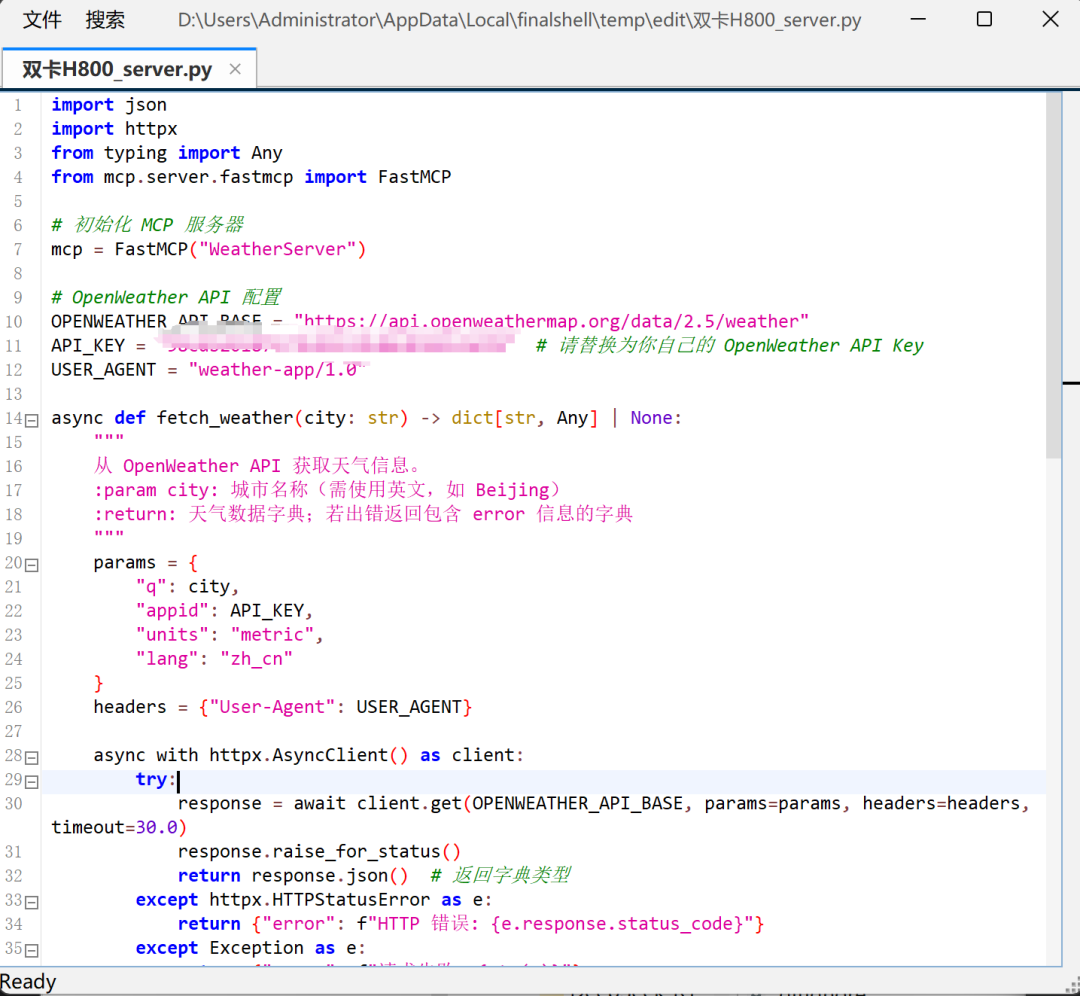
代码解释如下:
Part 1. 异步获取天气数据
-
函数 fetch_weather(city: str)
-
使用 httpx.AsyncClient() 发送异步 GET 请求到 OpenWeather API。
-
如果请求成功,则调用 response.json() 返回一个字典。
-
出现异常时,返回包含错误信息的字典。
-
Part 2. 格式化天气数据
-
函数 format_weather(data: dict | str)
-
首先检查传入的数据是否为字符串,如果是,则使用 json.loads 将其转换为字典。
-
检查数据中是否包含 "error" 字段,如果有,直接返回错误提示。
-
使用 .get() 方法提取 name、sys.country、main.temp、main.humidity、wind.speed 和 weather[0].description 等数据,并为可能缺失的字段提供默认值。
-
将提取的信息拼接成一个格式化字符串,方便阅读。
-
Part 3. MCP 工具 query_weather(city: str)
-
函数 query_weather
-
通过 @mcp.tool() 装饰器注册为 MCP 服务器的工具,使其能够被客户端调用。
-
调用 fetch_weather(city) 获取天气数据,然后用 format_weather(data) 将数据格式化为易读文本,最后返回该字符串。
-
Part 4. 运行服务器
-
if __name__ == "__main__": 块
-
调用 mcp.run(transport='stdio') 启动 MCP 服务器,采用标准 I/O 通信方式,等待客户端调用。
-
此外,上述代码有两个注意事项,
-
query_weather函数的函数说明至关重要,相当于是此后客户端对函数进行识别的基本依据,因此需要谨慎编写;
-
当指定 transport='stdio' 运行 MCP 服务器时,客户端必须在启动时同时启动当前这个脚本,否则无法顺利通信。这是因为 stdio 模式是一种本地进程间通信(IPC,Inter-Process Communication)方式,它需要服务器作为子进程运行,并通过标准输入输出(stdin/stdout)进行数据交换。
因此,当我们编写完服务器后,并不能直接调用这个服务器,而是需要创建一个对应的能够进行stdio的客户端,才能顺利进行通信。
2. client创建流程
接下来继续创建客户端来调用MCP服务器。
2.1 创建 MCP 客户端项目
# 创建项目目录
cd /root/autodl-tmp/MCP
uv init mcp-chatbot
cd mcp-chatbot
2.2 创建MCP客户端虚拟环境
# 创建虚拟环境
uv venv
# 激活虚拟环境
source .venv/bin/activate
这里需要注意的是,相比pip,uv会自动识别当前项目主目录并创建虚拟环境。
然后即可通过add方法在虚拟环境中安装相关的库。
# 安装 MCP SDK
uv add mcp openai python-dotenv httpx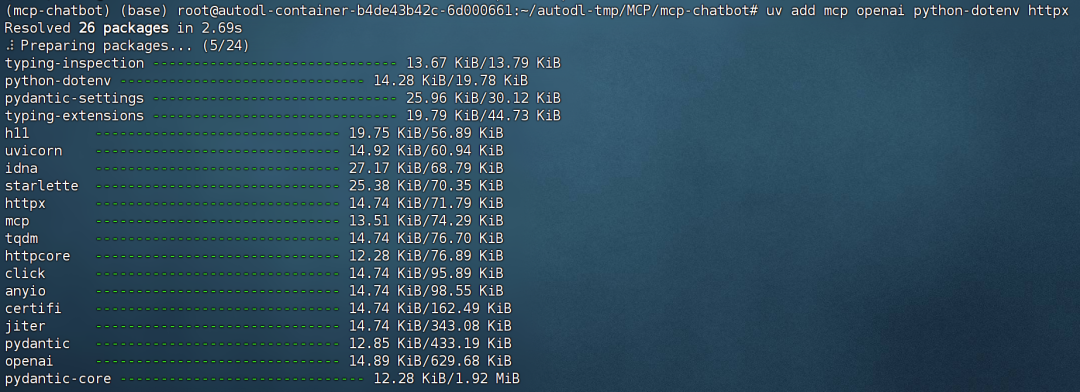
接下来创建.env文件,并写入OpenAI的API-Key,以及反向代理地址。借助反向代理,国内可以无门槛直连OpenAI官方服务器,并调用官方API。
写入如下内容
BASE_URL="反向代理地址"
MODEL=gpt-4o
OPENAI_API_KEY="OpenAI-API-Key"
OpenAI注册指南与国内反向代理领取地址:
而如果是使用DeepSeek模型,则需要在.env中写入如下内容:
BASE_URL=https://api.deepseek.com
MODEL=deepseek-chat
OPENAI_API_KEY="DeepSeek API-Key"创建servers_config.json
创建weather_server.py
并写入如下内容:
import os
import json
import httpx
from typing import Any
from dotenv import load_dotenv
from mcp.server.fastmcp import FastMCP
# 初始化 MCP 服务器
mcp = FastMCP("WeatherServer")
# OpenWeather API 配置
OPENWEATHER_API_BASE = "https://api.openweathermap.org/data/2.5/weather"
API_KEY = "OPENWEATHER_API_KEY"
USER_AGENT = "weather-app/1.0"
async def fetch_weather(city: str) -> dict[str, Any] | None:
"""
从 OpenWeather API 获取天气信息。
:param city: 城市名称(需使用英文,如 Beijing)
:return: 天气数据字典;若出错返回包含 error 信息的字典
"""
params = {
"q": city,
"appid": API_KEY,
"units": "metric",
"lang": "zh_cn"
}
headers = {"User-Agent": USER_AGENT}
async with httpx.AsyncClient() as client:
try:
response = await client.get(OPENWEATHER_API_BASE, params=params, headers=headers, timeout=30.0)
response.raise_for_status()
return response.json() # 返回字典类型
except httpx.HTTPStatusError as e:
return {"error": f"HTTP 错误: {e.response.status_code}"}
except Exception as e:
return {"error": f"请求失败: {str(e)}"}
def format_weather(data: dict[str, Any] | str) -> str:
"""
将天气数据格式化为易读文本。
:param data: 天气数据(可以是字典或 JSON 字符串)
:return: 格式化后的天气信息字符串
"""
# 如果传入的是字符串,则先转换为字典
if isinstance(data, str):
try:
data = json.loads(data)
except Exception as e:
return f"无法解析天气数据: {e}"
# 如果数据中包含错误信息,直接返回错误提示
if "error" in data:
return f"⚠️ {data['error']}"
# 提取数据时做容错处理
city = data.get("name", "未知")
country = data.get("sys", {}).get("country", "未知")
temp = data.get("main", {}).get("temp", "N/A")
humidity = data.get("main", {}).get("humidity", "N/A")
wind_speed = data.get("wind", {}).get("speed", "N/A")
# weather 可能为空列表,因此用 [0] 前先提供默认字典
weather_list = data.get("weather", [{}])
description = weather_list[0].get("description", "未知")
return (
f"🌍 {city}, {country}\n"
f"🌡 温度: {temp}°C\n"
f"💧 湿度: {humidity}%\n"
f"🌬 风速: {wind_speed} m/s\n"
f"🌤 天气: {description}\n"
)
@mcp.tool()
async def query_weather(city: str) -> str:
"""
输入指定城市的英文名称,返回今日天气查询结果。
:param city: 城市名称(需使用英文)
:return: 格式化后的天气信息
"""
data = await fetch_weather(city)
return format_weather(data)
if __name__ == "__main__":
# 以标准 I/O 方式运行 MCP 服务器
mcp.run(transport='stdio')这段 JSON 配置文件描述了一个名为 weather 的 MCP 服务器(mcpServers),该服务器使用 Python 运行一个脚本 weather_server.py。下面是对每个部分的详细解释:
-
mcpServers: 这是一个包含多个 MCP 服务器配置的对象。每个服务器都有一个唯一的名称,例如 weather,用来标识该服务器。
-
weather: 这是 mcpServers 下的一个服务器配置。服务器的名称为 weather,你可以根据这个名称在其他地方引用该服务器。
-
command: 这是启动该服务器所需要执行的命令。在这里,命令是 python,意味着这个服务器将通过 Python 运行。
-
args: 这是一个数组,包含了传递给命令的参数。在这个例子中,传递的参数是 ["weather_server.py"],意味着该服务器将运行 weather_server.py 脚本。
然后在config.json中写入如下内容:
{
"mcpServers": {
"weather": {
"command": "python",
"args": ["weather_server.py"]
}
}
}紧接着创建main.py,并写入如下内容:
import asyncio
import json
import logging
import os
import shutil
from contextlib import AsyncExitStack
from typing import Any, Dict, List, Optional
import httpx
from dotenv import load_dotenv
from openai import OpenAI # OpenAI Python SDK
from mcp import ClientSession, StdioServerParameters
from mcp.client.stdio import stdio_client
# Configure logging
logging.basicConfig(
level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s"
)
# =============================
# 配置加载类(支持环境变量及配置文件)
# =============================
class Configuration:
"""管理 MCP 客户端的环境变量和配置文件"""
def __init__(self) -> None:
load_dotenv()
# 从环境变量中加载 API key, base_url 和 model
self.api_key = os.getenv("LLM_API_KEY")
self.base_url = os.getenv("BASE_URL")
self.model = os.getenv("MODEL")
if not self.api_key:
raise ValueError("❌ 未找到 LLM_API_KEY,请在 .env 文件中配置")
@staticmethod
def load_config(file_path: str) -> Dict[str, Any]:
"""
从 JSON 文件加载服务器配置
Args:
file_path: JSON 配置文件路径
Returns:
包含服务器配置的字典
"""
with open(file_path, "r") as f:
return json.load(f)
# =============================
# MCP 服务器客户端类
# =============================
class Server:
"""管理单个 MCP 服务器连接和工具调用"""
def __init__(self, name: str, config: Dict[str, Any]) -> None:
self.name: str = name
self.config: Dict[str, Any] = config
self.session: Optional[ClientSession] = None
self.exit_stack: AsyncExitStack = AsyncExitStack()
self._cleanup_lock = asyncio.Lock()
async def initialize(self) -> None:
"""初始化与 MCP 服务器的连接"""
# command 字段直接从配置获取
command = self.config["command"]
if command is None:
raise ValueError("command 不能为空")
server_params = StdioServerParameters(
command=command,
args=self.config["args"],
env={**os.environ, **self.config["env"]} if self.config.get("env") else None,
)
try:
stdio_transport = await self.exit_stack.enter_async_context(
stdio_client(server_params)
)
read_stream, write_stream = stdio_transport
session = await self.exit_stack.enter_async_context(
ClientSession(read_stream, write_stream)
)
await session.initialize()
self.session = session
except Exception as e:
logging.error(f"Error initializing server {self.name}: {e}")
await self.cleanup()
raise
async def list_tools(self) -> List[Any]:
"""获取服务器可用的工具列表
Returns:
工具列表
"""
if not self.session:
raise RuntimeError(f"Server {self.name} not initialized")
tools_response = await self.session.list_tools()
tools = []
for item in tools_response:
if isinstance(item, tuple) and item[0] == "tools":
for tool in item[1]:
tools.append(Tool(tool.name, tool.description, tool.inputSchema))
return tools
async def execute_tool(
self, tool_name: str, arguments: Dict[str, Any], retries: int = 2, delay: float = 1.0
) -> Any:
"""执行指定工具,并支持重试机制
Args:
tool_name: 工具名称
arguments: 工具参数
retries: 重试次数
delay: 重试间隔秒数
Returns:
工具调用结果
"""
if not self.session:
raise RuntimeError(f"Server {self.name} not initialized")
attempt = 0
while attempt < retries:
try:
logging.info(f"Executing {tool_name} on server {self.name}...")
result = await self.session.call_tool(tool_name, arguments)
return result
except Exception as e:
attempt += 1
logging.warning(
f"Error executing tool: {e}. Attempt {attempt} of {retries}."
)
if attempt < retries:
logging.info(f"Retrying in {delay} seconds...")
await asyncio.sleep(delay)
else:
logging.error("Max retries reached. Failing.")
raise
async def cleanup(self) -> None:
"""清理服务器资源"""
async with self._cleanup_lock:
try:
await self.exit_stack.aclose()
self.session = None
except Exception as e:
logging.error(f"Error during cleanup of server {self.name}: {e}")
# =============================
# 工具封装类
# =============================
class Tool:
"""封装 MCP 返回的工具信息"""
def __init__(self, name: str, description: str, input_schema: Dict[str, Any]) -> None:
self.name: str = name
self.description: str = description
self.input_schema: Dict[str, Any] = input_schema
def format_for_llm(self) -> str:
"""生成用于 LLM 提示的工具描述"""
args_desc = []
if "properties" in self.input_schema:
for param_name, param_info in self.input_schema["properties"].items():
arg_desc = f"- {param_name}: {param_info.get('description', 'No description')}"
if param_name in self.input_schema.get("required", []):
arg_desc += " (required)"
args_desc.append(arg_desc)
return f"""
Tool: {self.name}
Description: {self.description}
Arguments:
{chr(10).join(args_desc)}
"""
# =============================
# LLM 客户端封装类(使用 OpenAI SDK)
# =============================
class LLMClient:
"""使用 OpenAI SDK 与大模型交互"""
def __init__(self, api_key: str, base_url: Optional[str], model: str) -> None:
self.client = OpenAI(api_key=api_key, base_url=base_url)
self.model = model
def get_response(self, messages: List[Dict[str, Any]], tools: Optional[List[Dict[str, Any]]] = None) -> Any:
"""
发送消息给大模型 API,支持传入工具参数(function calling 格式)
"""
payload = {
"model": self.model,
"messages": messages,
"tools": tools,
}
try:
response = self.client.chat.completions.create(**payload)
return response
except Exception as e:
logging.error(f"Error during LLM call: {e}")
raise
# =============================
# 多服务器 MCP 客户端类(集成配置文件、工具格式转换与 OpenAI SDK 调用)
# =============================
class MultiServerMCPClient:
def __init__(self) -> None:
"""
管理多个 MCP 服务器,并使用 OpenAI Function Calling 风格的接口调用大模型
"""
self.exit_stack = AsyncExitStack()
config = Configuration()
self.openai_api_key = config.api_key
self.base_url = config.base_url
self.model = config.model
self.client = LLMClient(self.openai_api_key, self.base_url, self.model)
# (server_name -> Server 对象)
self.servers: Dict[str, Server] = {}
# 各个 server 的工具列表
self.tools_by_server: Dict[str, List[Any]] = {}
self.all_tools: List[Dict[str, Any]] = []
async def connect_to_servers(self, servers_config: Dict[str, Any]) -> None:
"""
根据配置文件同时启动多个服务器并获取工具
servers_config 的格式为:
{
"mcpServers": {
"sqlite": { "command": "uvx", "args": [ ... ] },
"puppeteer": { "command": "npx", "args": [ ... ] },
...
}
}
"""
mcp_servers = servers_config.get("mcpServers", {})
for server_name, srv_config in mcp_servers.items():
server = Server(server_name, srv_config)
await server.initialize()
self.servers[server_name] = server
tools = await server.list_tools()
self.tools_by_server[server_name] = tools
for tool in tools:
# 统一重命名:serverName_toolName
function_name = f"{server_name}_{tool.name}"
self.all_tools.append({
"type": "function",
"function": {
"name": function_name,
"description": tool.description,
"input_schema": tool.input_schema
}
})
# 转换为 OpenAI Function Calling 所需格式
self.all_tools = await self.transform_json(self.all_tools)
logging.info("\n✅ 已连接到下列服务器:")
for name in self.servers:
srv_cfg = mcp_servers[name]
logging.info(f" - {name}: command={srv_cfg['command']}, args={srv_cfg['args']}")
logging.info("\n汇总的工具:")
for t in self.all_tools:
logging.info(f" - {t['function']['name']}")
async def transform_json(self, json_data: List[Dict[str, Any]]) -> List[Dict[str, Any]]:
"""
将工具的 input_schema 转换为 OpenAI 所需的 parameters 格式,并删除多余字段
"""
result = []
for item in json_data:
if not isinstance(item, dict) or "type" not in item or "function" not in item:
continue
old_func = item["function"]
if not isinstance(old_func, dict) or "name" not in old_func or "description" not in old_func:
continue
new_func = {
"name": old_func["name"],
"description": old_func["description"],
"parameters": {}
}
if "input_schema" in old_func and isinstance(old_func["input_schema"], dict):
old_schema = old_func["input_schema"]
new_func["parameters"]["type"] = old_schema.get("type", "object")
new_func["parameters"]["properties"] = old_schema.get("properties", {})
new_func["parameters"]["required"] = old_schema.get("required", [])
new_item = {
"type": item["type"],
"function": new_func
}
result.append(new_item)
return result
async def chat_base(self, messages: List[Dict[str, Any]]) -> Any:
"""
使用 OpenAI 接口进行对话,并支持多次工具调用(Function Calling)。
如果返回 finish_reason 为 "tool_calls",则进行工具调用后再发起请求。
"""
response = self.client.get_response(messages, tools=self.all_tools)
# 如果模型返回工具调用
if response.choices[0].finish_reason == "tool_calls":
while True:
messages = await self.create_function_response_messages(messages, response)
response = self.client.get_response(messages, tools=self.all_tools)
if response.choices[0].finish_reason != "tool_calls":
break
return response
async def create_function_response_messages(self, messages: List[Dict[str, Any]], response: Any) -> List[Dict[str, Any]]:
"""
将模型返回的工具调用解析执行,并将结果追加到消息队列中
"""
function_call_messages = response.choices[0].message.tool_calls
messages.append(response.choices[0].message.model_dump())
for function_call_message in function_call_messages:
tool_name = function_call_message.function.name
tool_args = json.loads(function_call_message.function.arguments)
# 调用 MCP 工具
function_response = await self._call_mcp_tool(tool_name, tool_args)
messages.append({
"role": "tool",
"content": function_response,
"tool_call_id": function_call_message.id,
})
return messages
async def process_query(self, user_query: str) -> str:
"""
OpenAI Function Calling 流程:
1. 发送用户消息 + 工具信息
2. 若模型返回 finish_reason 为 "tool_calls",则解析并调用 MCP 工具
3. 将工具调用结果返回给模型,获得最终回答
"""
messages = [{"role": "user", "content": user_query}]
response = self.client.get_response(messages, tools=self.all_tools)
content = response.choices[0]
logging.info(content)
if content.finish_reason == "tool_calls":
tool_call = content.message.tool_calls[0]
tool_name = tool_call.function.name
tool_args = json.loads(tool_call.function.arguments)
logging.info(f"\n[ 调用工具: {tool_name}, 参数: {tool_args} ]\n")
result = await self._call_mcp_tool(tool_name, tool_args)
messages.append(content.message.model_dump())
messages.append({
"role": "tool",
"content": result,
"tool_call_id": tool_call.id,
})
response = self.client.get_response(messages, tools=self.all_tools)
return response.choices[0].message.content
return content.message.content
async def _call_mcp_tool(self, tool_full_name: str, tool_args: Dict[str, Any]) -> str:
"""
根据 "serverName_toolName" 格式调用相应 MCP 工具
"""
parts = tool_full_name.split("_", 1)
if len(parts) != 2:
return f"无效的工具名称: {tool_full_name}"
server_name, tool_name = parts
server = self.servers.get(server_name)
if not server:
return f"找不到服务器: {server_name}"
resp = await server.execute_tool(tool_name, tool_args)
return resp.content if resp.content else "工具执行无输出"
async def chat_loop(self) -> None:
"""多服务器 MCP + OpenAI Function Calling 客户端主循环"""
logging.info("\n🤖 多服务器 MCP + Function Calling 客户端已启动!输入 'quit' 退出。")
messages: List[Dict[str, Any]] = []
while True:
query = input("\n你: ").strip()
if query.lower() == "quit":
break
try:
messages.append({"role": "user", "content": query})
messages = messages[-20:] # 保持最新 20 条上下文
response = await self.chat_base(messages)
messages.append(response.choices[0].message.model_dump())
result = response.choices[0].message.content
# logging.info(f"\nAI: {result}")
print(f"\nAI: {result}")
except Exception as e:
print(f"\n⚠️ 调用过程出错: {e}")
async def cleanup(self) -> None:
"""关闭所有资源"""
await self.exit_stack.aclose()
# =============================
# 主函数
# =============================
async def main() -> None:
# 从配置文件加载服务器配置
config = Configuration()
servers_config = config.load_config("servers_config.json")
client = MultiServerMCPClient()
try:
await client.connect_to_servers(servers_config)
await client.chat_loop()
finally:
try:
await asyncio.sleep(0.1)
await client.cleanup()
except RuntimeError as e:
# 如果是因为退出 cancel scope 导致的异常,可以选择忽略
if "Attempted to exit cancel scope" in str(e):
logging.info("退出时检测到 cancel scope 异常,已忽略。")
else:
raise
if __name__ == "__main__":
asyncio.run(main())这是一个基于 MCP(Model Context Protocol) 协议和 OpenAI Function Calling 机制的多服务器客户端实现。它集成了多个服务器,并支持通过 OpenAI 模型与这些服务器进行交互,执行工具和函数调用。下面是对代码各部分的详细解释:
1. 导入的库
-
asyncio: Python 中的异步编程库,用于处理异步任务。
-
json: 处理 JSON 格式数据。
-
logging: 配置日志输出。
-
os: 与操作系统交互,读取环境变量等。
-
shutil: 提供文件操作的高层接口(未使用在代码中)。
-
contextlib: 提供异步上下文管理功能。
-
httpx: 用于 HTTP 请求的异步客户端库(未直接使用,但可能用于未来扩展)。
-
dotenv: 从 .env 文件加载环境变量。
-
openai: OpenAI Python SDK,用于与 OpenAI API 进行交互。
-
mcp: MCP 协议的客户端库,用于与 MCP 服务器交互。
2. 配置加载类 (Configuration)
-
功能: 管理 MCP 客户端的环境变量和配置文件。
-
方法:
-
__init__: 从 .env 文件加载环境变量,获取 API 密钥 (LLM_API_KEY)、基本 URL (BASE_URL) 和模型名称 (MODEL)。
-
load_config: 从给定路径加载 JSON 配置文件,返回包含配置的字典。
-
3. MCP 服务器客户端类 (Server)
-
功能: 管理与 MCP 服务器的连接及与工具的交互。
-
方法:
-
initialize: 初始化与 MCP 服务器的连接,使用 stdio_client 与服务器建立连接。
-
list_tools: 获取服务器可用的工具列表。
-
execute_tool: 执行指定的工具,支持重试机制。
-
cleanup: 清理资源,关闭与 MCP 服务器的连接。
-
4. 工具封装类 (Tool)
-
功能: 封装从 MCP 服务器获取的工具信息。
-
方法:
-
format_for_llm: 将工具信息转换为适合 OpenAI LLM(大语言模型)提示的格式,包含工具的名称、描述和输入参数。
-
5. LLM 客户端类 (LLMClient)
-
功能: 使用 OpenAI SDK 与大模型进行交互。
-
方法:
-
get_response: 向 OpenAI 模型发送消息,支持传入工具参数(即 Function Calling 格式)。
-
6. 多服务器 MCP 客户端类 (MultiServerMCPClient)
-
功能: 管理多个 MCP 服务器,并使用 OpenAI Function Calling 机制与大模型进行交互。
-
方法:
-
connect_to_servers: 根据配置文件启动多个服务器,获取并列出每个服务器的工具。
-
transform_json: 将 MCP 工具的输入 schema 转换为 OpenAI Function Calling 所需的格式。
-
chat_base: 发送用户消息给 OpenAI 模型,支持多个工具调用。
-
create_function_response_messages: 解析模型返回的工具调用并执行。
-
process_query: 处理用户查询,支持模型调用多个工具并返回结果。
-
chat_loop: 客户端主循环,处理与用户的交互,支持多次工具调用。
-
cleanup: 关闭所有资源。
-
7. 主函数 (main)
-
功能: 主程序入口,加载服务器配置并启动客户端。
-
方法:
-
从配置文件加载服务器配置。
-
使用 MultiServerMCPClient 启动服务器并开始与用户的聊天交互。
-
在程序结束时进行清理操作。
-
8. 程序流
-
配置加载:程序首先加载 .env 文件中的配置和 JSON 配置文件中的服务器配置。
-
连接服务器:通过 MultiServerMCPClient 初始化多个 MCP 服务器并获取每个服务器的可用工具。
-
与模型交互:通过 OpenAI SDK 与模型交互,支持模型调用工具和执行功能。
-
功能调用:当模型返回要求调用工具时,程序会执行对应的 MCP 服务器工具并返回结果,直到最终得到模型的回答。
-
聊天循环:用户通过控制台输入查询,程序调用 OpenAI 模型并执行必要的工具调用,直到返回最终结果。
9. 异常处理
-
代码中有多处使用 try-except 来捕获和处理异常,确保在服务器连接或工具调用过程中发生错误时可以优雅地处理,并输出错误信息。
4.运行测试
最后即可在当前项目的主目录下输入uv run进行运行:
uv run main.py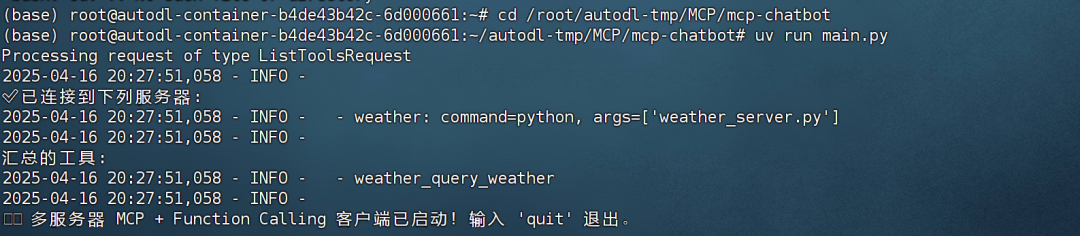
可以进行多轮对话并进行天气查询:

并支持多工具并行调用:
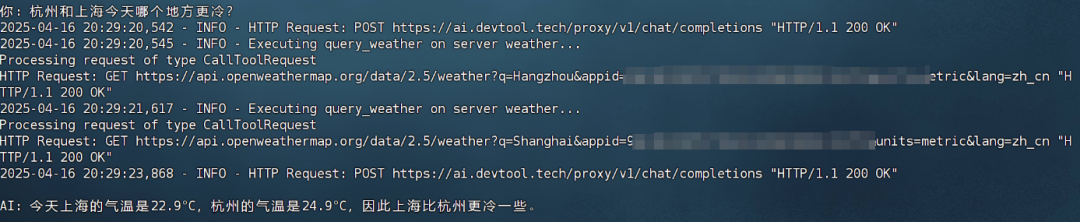
5.接入更多工具
接下来在当前主目录下创建write_server.py服务器:
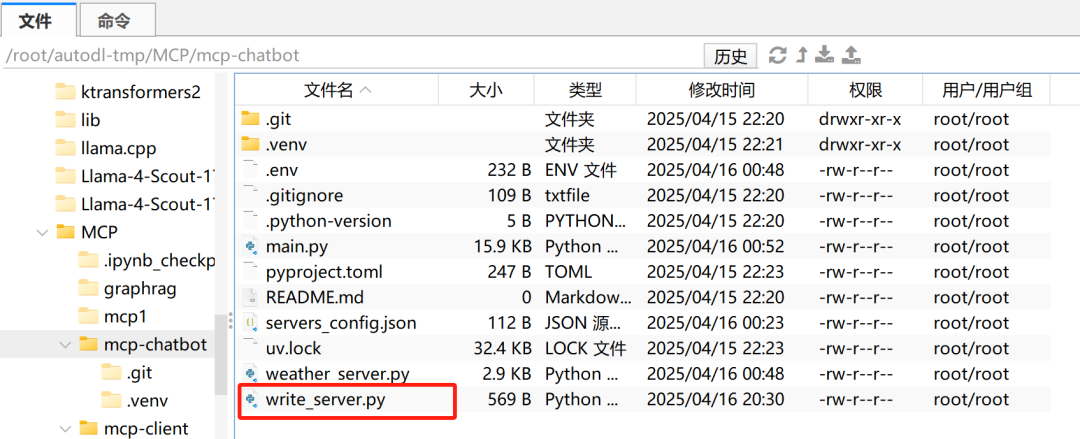
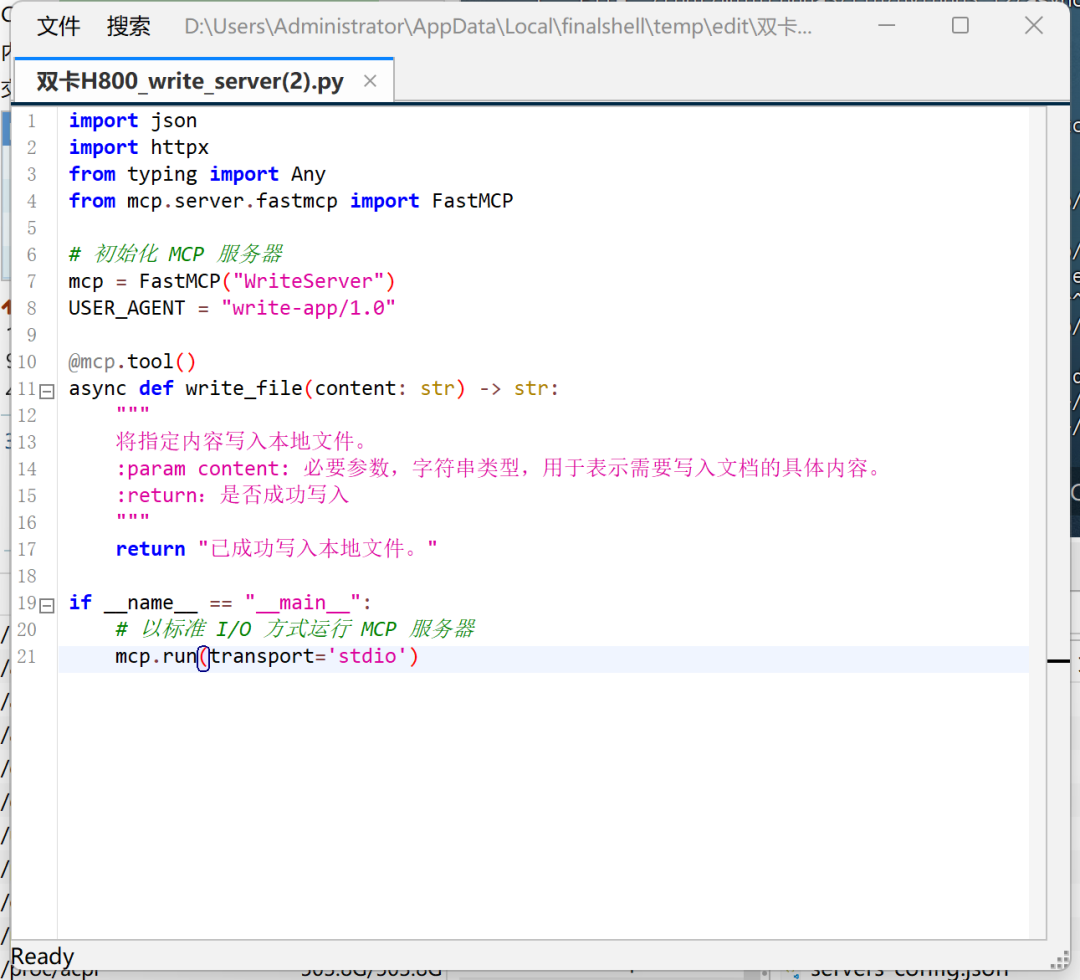
同时写入配置文件:
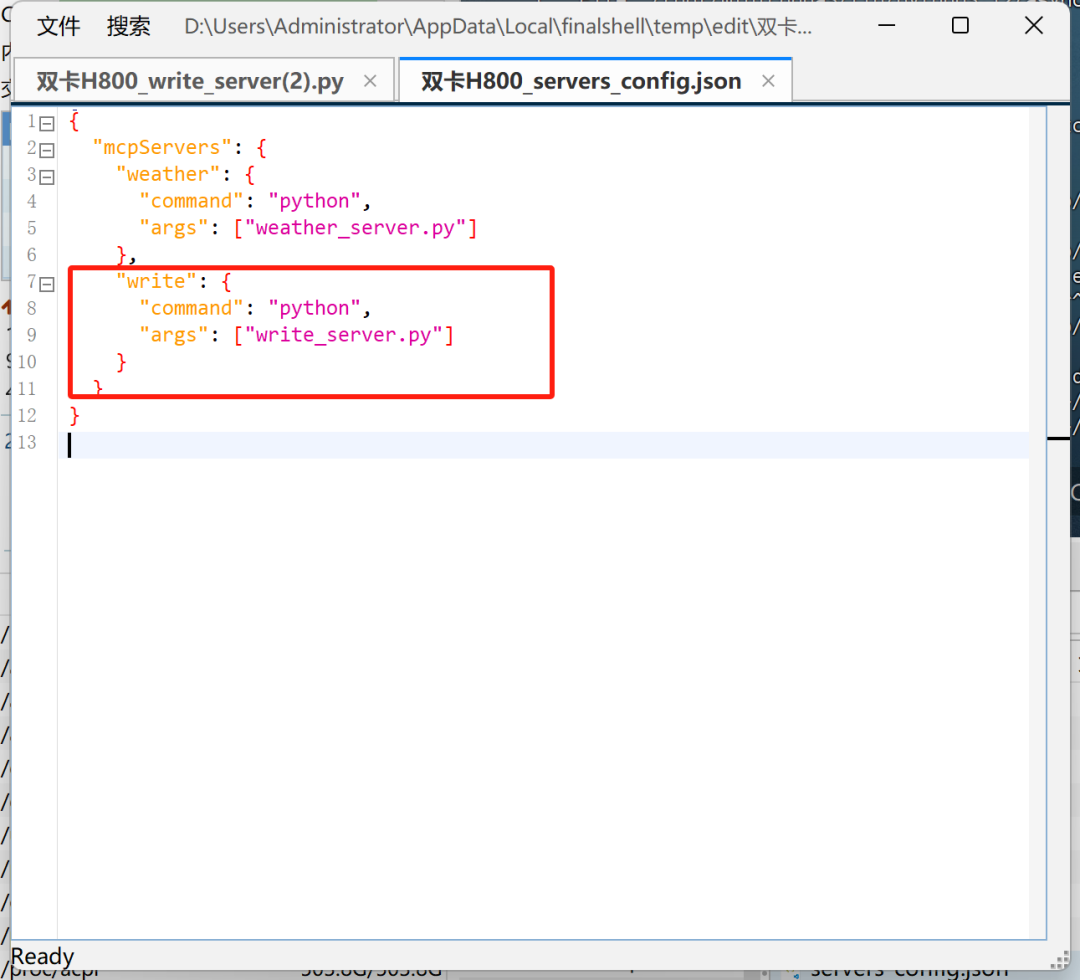
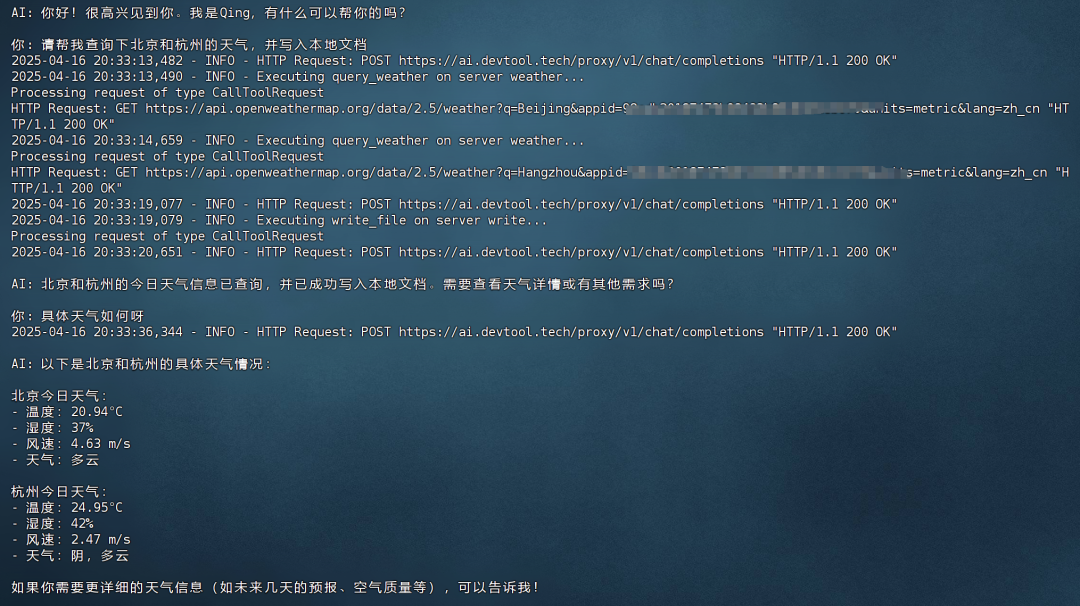
即可在对话中调用新的MCP工具了(需重启对话):
MCP服务器上线流程参考
1 MPC服务器在线管理与实时下载
1.1 npm registry 简介介绍
npm registry(Node Package Manager Registry)是一个 开源的 JavaScript 包管理平台,它存储着成千上万的 JavaScript 和 Node.js 库、工具和框架。开发者可以将自己的代码库作为包发布到 npm registry,供其他开发者使用。它是 npm (Node Package Manager)工具的核心组件,npm 是当前最流行的 JavaScript 包管理工具,广泛应用于前端和后端开发中。
npm registry 的作用是为 JavaScript/Node.js 开发者 提供一个集中的资源库,用户可以通过 npm 或 npx 等工具来安装、更新和使用这些包。除此之外,npm registry 还支持其他语言的工具和脚本,比如通过 uvx,Python 工具也能方便地通过 npm registry 进行下载和管理。
使用 npm registry 带来了许多便捷性,尤其是在 实时下载和管理库 方面,它改变了开发者与依赖管理的互动方式。以下是它带来的几个主要优点:
-
无需手动下载和安装依赖:
-
通过 npm 或 npx,开发者可以轻松地 实时下载并运行 所需的包,无需手动下载、解压和安装依赖项。npx 甚至支持临时下载并执行工具,而不必安装到本地环境中,减少了不必要的手动操作。
-
-
最新版本的实时访问:
-
使用 npm registry 时,您始终能够访问到 最新版本 的工具和库。当发布新版本时,用户通过 npx 或 npm install 安装的包会自动下载最新的版本,避免了使用过时版本的风险。
-
-
集中管理和共享:
-
npm registry 提供了一个集中管理和分发代码的场所,开发者可以方便地发布自己的工具、库,并与全球其他开发者共享。这促进了 开源生态系统 的发展,并且让其他开发者能够轻松使用这些工具。
-
-
跨语言支持(通过 uvx):
-
尽管 npm registry 是以 JavaScript/Node.js 为主,但通过 uvx 等工具,它也可以方便地管理 Python 包 和其他语言的工具,这使得 跨语言开发 更加简洁和高效。
-
-
简化依赖管理和版本控制:
-
在开发过程中,npm registry 不仅能帮助开发者快速获取第三方库,还能自动处理依赖版本的管理。通过 npm 配置文件(如 package.json),开发者可以清晰地查看和管理项目所依赖的所有库,并且可以随时更新、安装或回滚特定版本。
-
-
跨平台支持:
-
npm registry 支持的工具和包广泛适用于不同操作系统(如 Windows、macOS、Linux 等)。无论在哪个平台上,开发者都可以使用相同的命令来获取并运行所需的工具,无需担心操作系统的差异。
-
npm registry 提供了一个集中、开放、实时更新的生态系统,极大地简化了开发者在项目中使用外部工具和库的过程。开发者只需要通过简单的命令(如 npm install 或 npx),就能实时下载最新版本的库、工具和框架,而无需处理繁琐的版本管理和依赖配置。实时下载和运行工具包的便捷性,使得开发工作更加高效,能够快速迭代和创新,同时促进了开源社区的蓬勃发展。
通过 npm registry 和 npx 等工具,开发者可以轻松使用最新的工具包,同时避免了手动管理和安装包的麻烦。这使得跨语言和跨平台的开发变得更加简便,增强了开发效率。
1.2 将开发好的库上传至npm registry
接下来我们尝试将一个 Python 编写的 MCP 服务器 发布为一个 npm 包,并能够通过 npx 或 uvx 快速运行该服务器。这种方法使得您可以跨平台发布和使用 Python 脚本,而不需要其他开发者手动安装和配置 Python 环境。
步骤 1: 准备 Python 代码
首先需要编写一个Python脚本,也就是一个MCP服务器。以查询天气为例,具体代码我们稍后会进行解释,这里我们可以先在课件网盘中下载一个自定义的天气查询MCP服务器Python脚本:
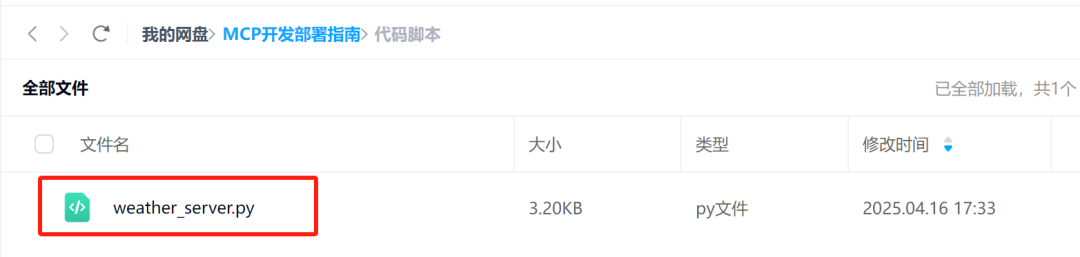

然后即可继续进行发布操作。
步骤 2: 创建一个 Node.js 项目
-
初始化 Node.js 项目:首先,我们需要一个 package.json 文件,这是 npm 包的核心配置文件。我们可以通过 npm init 命令来初始化一个新的 Node.js 项目。打开终端,进入到项目文件夹,然后运行以下命令:
npm init-
这将引导您我们创建一个新的 package.json 文件。在提问时,我们可以按默认值按下 Enter,或者输入我们自定义内容。
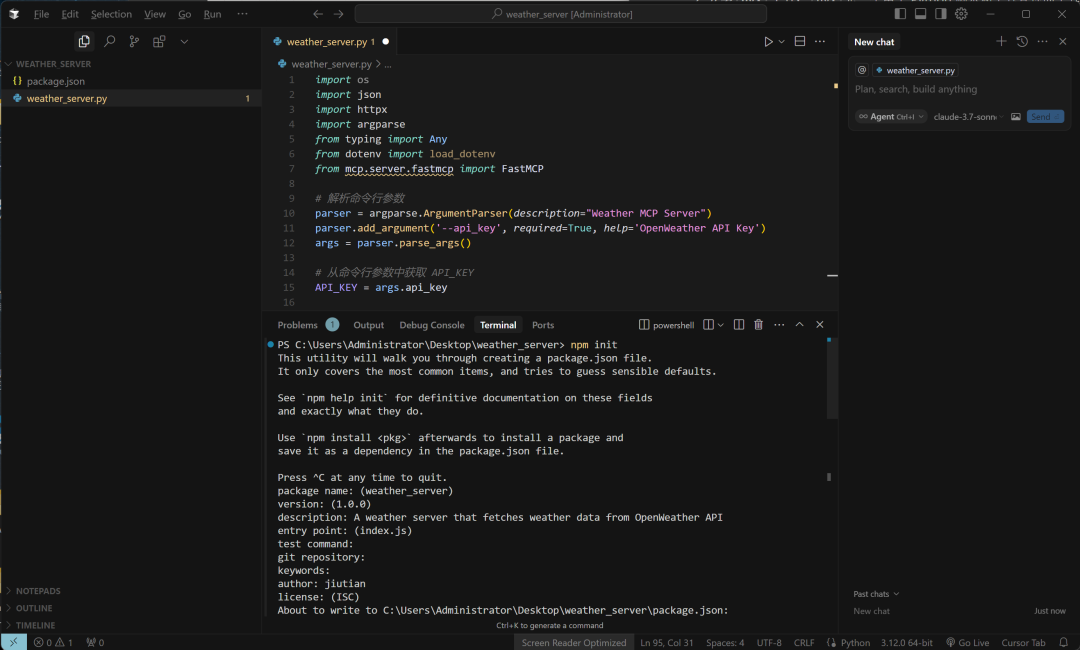
-
安装 uvx 工具: uvx 是一个用于 Python 脚本和工具管理的工具,可以让我们通过 npm 来管理和运行 Python 工具包。
-
运行以下命令来安装 uvx:
npm install uvx --save步骤 3: 配置 package.json 来运行 Python 脚本
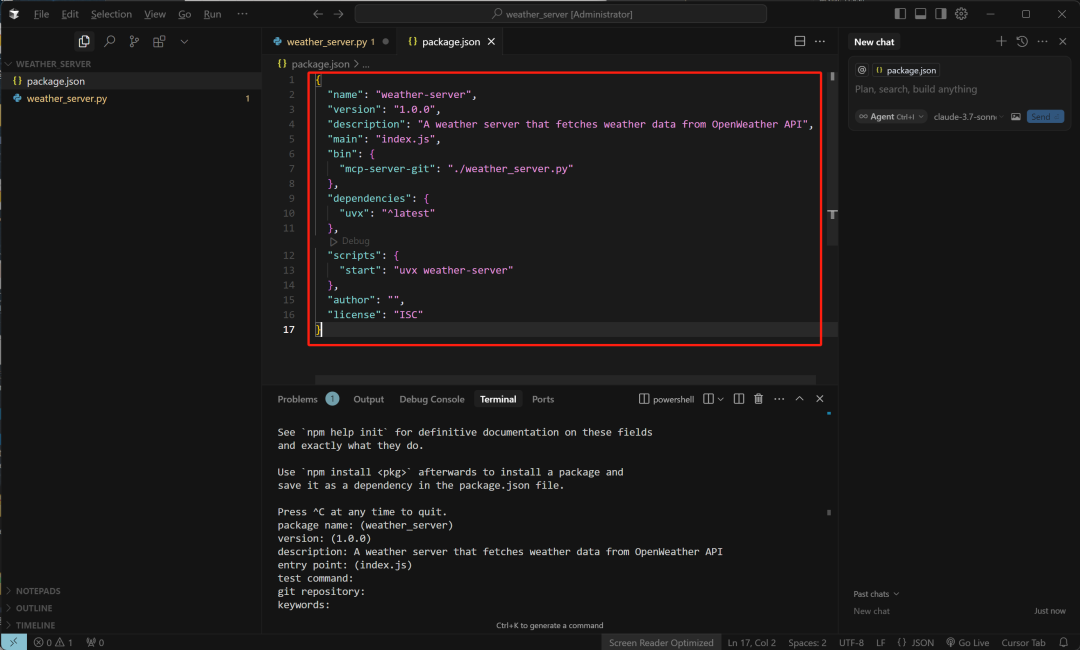
-
在 package.json 文件中,添加一个 bin 字段,告诉 npm 包如何启动我们的 Python 脚本。
-
打开 package.json 文件,并将其修改为类似下面的样子:
{
"name": "weather-server",
"version": "1.0.0",
"description": "A weather server that fetches weather data from OpenWeather API",
"main": "index.js",
"bin": {
"mcp-server-git": "./weather_server.py"
},
"dependencies": {
"uvx": "^latest"
},
"scripts": {
"start": "uvx weather-server"
},
"author": "",
"license": "ISC"
}-
bin 字段:将我们的 Python 脚本路径指定为命令。这里,"mcp-server-git" 将成为用户运行命令时执行的脚本名称,"./weather_server.py" 指定 Python 脚本路径。
-
scripts 字段:指定使用 uvx 启动 Python 脚本。
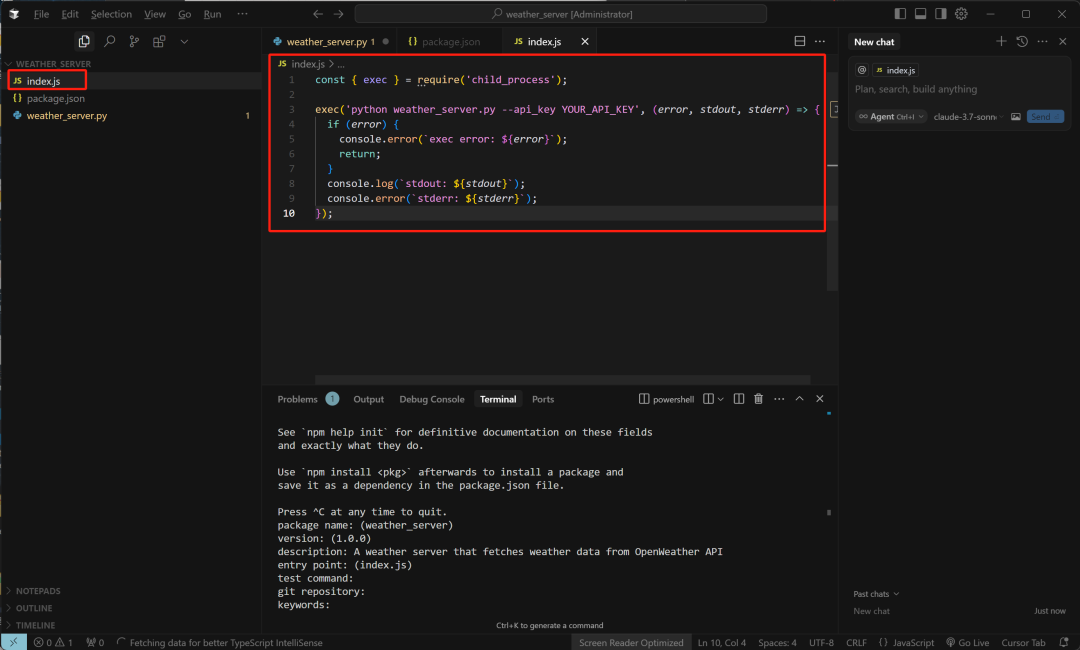
-
创建一个简单的启动脚本:在项目根目录下创建一个简单的 index.js 文件来调用 Python 脚本。
-
index.js 文件:
const { exec } = require('child_process');
exec('python weather_server.py --api_key YOUR_API_KEY', (error, stdout, stderr) => {
if (error) {
console.error(`exec error: ${error}`);
return;
}
console.log(`stdout: ${stdout}`);
console.error(`stderr: ${stderr}`);
});-
这个脚本将运行我们的 Python 脚本并传递 API Key。
步骤 4: 创建一个 .npmignore 文件
如果我们的项目包含不需要发布到 npm 的文件(如 Python 环境相关的文件、缓存文件等),可以在项目根目录创建一个 .npmignore 文件,并列出这些文件。例如:
*.pyc
__pycache__
*.env步骤 5: 发布包到 npm
-
登录 npm:如果您还没有 npm 账户,首先需要在 npm 官网 注册一个账户。
-
登录您的 npm 账户:
npm login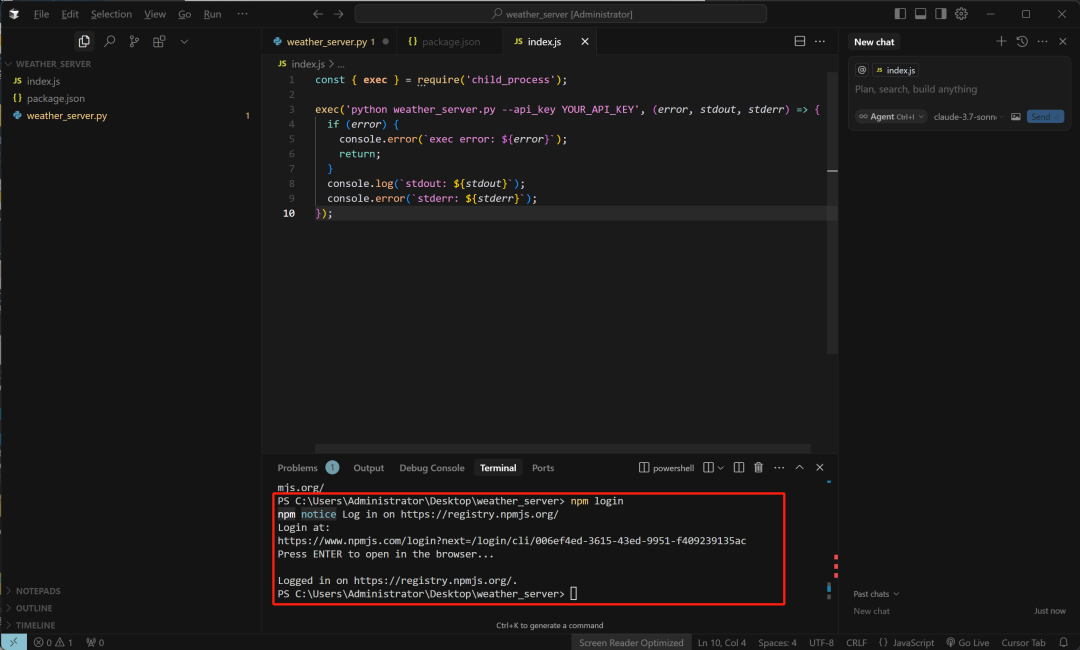
-
注意这里需要访问 npm 官方网站:https://www.npmjs.com/signup进行注册,并且设置npm为官方镜像源:
npm config set registry https://registry.npmjs.org/-
然后才能顺利的登录和发布。
-
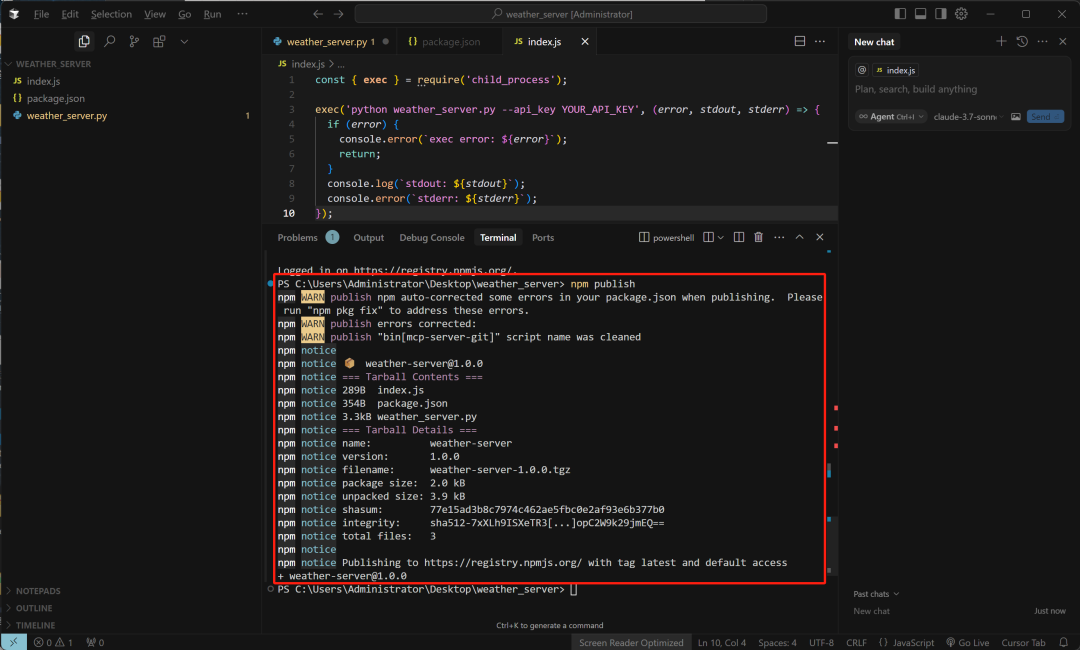
发布到 npm:使用以下命令将您的包发布到 npm registry:
npm publish-
这将把我们的包上传到 npm registry,其他用户就可以通过 npx 或 uvx 下载并运行您的 Python 服务器了。
步骤 6: 使用 npx 或 uvx 来运行 MCP 服务器
发布成功后,我们尝试在Cherry Studio中运行这个天气查询服务器。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









