







 本文介绍了如何使用Python爬取豆瓣TOP250电影的数据,包括电影名称、导演、演员和类型,然后利用这些数据构建知识图谱,并使用neo4j进行存储。详细讲述了数据爬取的步骤和正则表达式的使用,以及如何将数据导入到neo4j的知识图谱中。
本文介绍了如何使用Python爬取豆瓣TOP250电影的数据,包括电影名称、导演、演员和类型,然后利用这些数据构建知识图谱,并使用neo4j进行存储。详细讲述了数据爬取的步骤和正则表达式的使用,以及如何将数据导入到neo4j的知识图谱中。
数据爬取网站: https://movie.douban .com/top250?start=0.
代码下载地址:https://download.csdn.net/download/fufu_good/12117620.
1. 首先对网页数据进行分析,进而确定节点和关系

我们直接分析电影点进去的详细页面,页面如下:(由于豆瓣在没有登录的情况下频繁对网站进行请求会被认为恶意攻击,导致自己的ip无法访问该网站,所以最好先下载下来)
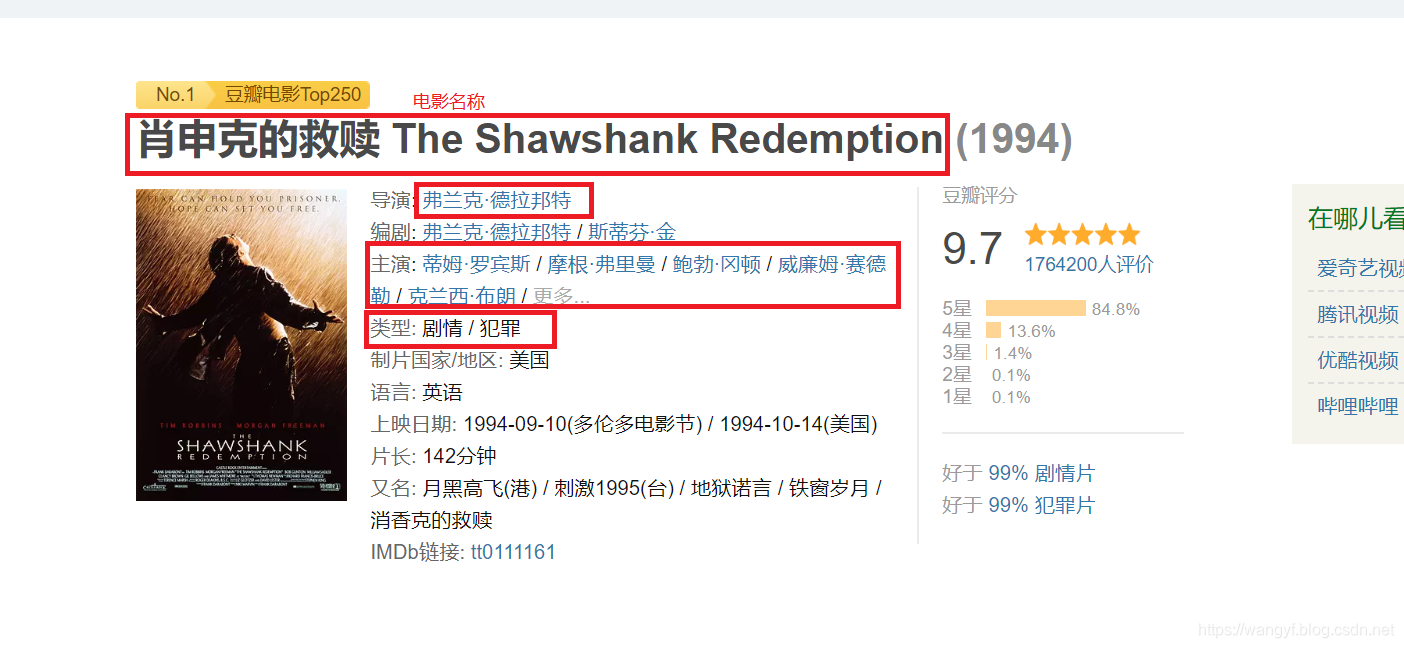
通过上图,我们选择4个结点和4种关系
4个结点分别为:
- 电影名称(film_name)
- 导演(director)
- 演员(actor)
- 类型(type)
4种关系分别为:
- acted_in(电影——>演员)
- directed(电影——>导演)
- belong_to(电影——>类型)
- cooperation(导演——>演员)
2. 下载分析页面
点击鼠标右键查看源代码,知道链接的模式之后我们可以采用正则表达式进行匹配,然后获取链接对应页面,最终将获取的页面保存在文件中,为我们后面分析提供数据。

分析后,我们采用后面那包含class属性的链接(其实和上面一种一样,只是为了防止多次访问同样页面),最终我们采用如下正则表达式:
<a href="https://movie.douban.com/subject/\d*?/" class="">
最终形成的获取分析页面代码如下(最终我存放在代码目录下的contents目录下)(1_getPage.py):
import requests
import re
import time
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
x = range(0, 250, 25)
for i in x:
# 请求排行榜页面
html = requests.get("https://movie.douban.com/top250?start=" + str(i), headers=headers)
# 防止请求过于频繁
time.sleep(0.01)
# 将获取的内容采用utf8解码
cont = html.content.decode('utf8')
# 使用正则表达式获取电影的详细页面链接
urlList = re.findall('<a href="https://movie.douban.com/subject/\d*?/" class="">', cont)
# 排行榜每一页都有25个电影,于是匹配到了25个链接,逐个对访问进行请求
for j in range(len(urlList)):
# 获取啊、标签中的url
url = urlList[j].replace('<a href="', "").replace('" class="">', "")
# 将获取的内容采用utf8解码
content = requests.get(url, headers=headers).content.decode('utf8')
# 采用数字作为文件名
film_name = i + j
# 写入文件
with open('contents/' + str(film_name) + '.txt', mode='w', encoding='utf8') as f:
f.write(content)
3. 数据爬取
3.1 结点数据爬取
3.1.1 电影名称结点获取

首先分析页面数据,发现电影名称使用title标签框住,于是可以采用如下正则表达式对电影名称(film_name)进行提取:
<title>.*?/title>
3.1.2 导演结点获取
接着分析导演(director)结点数据的提取: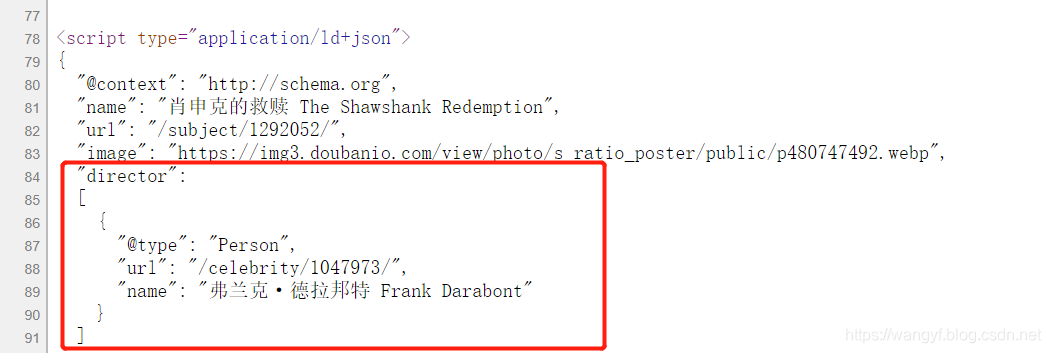
通过分析源代码中的脚本,我们可以使用如下正则表达式对数据进行提取:
"director":.*?]
"name": ".*?"
3.1.3 演员结点获取
同理分析下面数据,提取演员(actor)结点数据:

我们可以使用如下正则表达式进行actor的提取:
"actor":.*?]
"name": ".*?"
3.1.4 类型结点获取
最后分析电影类别(type):

于是我们可以使用如下正则表达式进行数据提取:
<span property="v:genre">.*?</span>
3.1.5 综上,现在列出获取所有结点数据并且保存在csv中的代码(2_getNode.py):
import re
import pandas
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.132 Safari/537.36'
}
def node_save(attrCont, tag, attr, label):
ID = []
for i in range(len(attrCont)):
ID.append(tag * 10000 + i)
data = {
'ID': ID, attr: attrCont, 'LABEL': label}
dataframe = pandas.DataFrame(data)
dataframe.to_csv('details/' + attr + '.csv', index=False, sep=',', encoding="utf_8_sig")
def save(contents):
# save movie nodes
film_name = re.findall('<title>.*?/title>', contents)[0]
film_name = film_name.lstrip("<title>").rstrip("(豆瓣)</title>").replace(" ", "" 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1348
1348

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









