



混淆矩阵就是分别统计分类模型归错类,归对类的观测值个数,然后把结果放在一个表里展示出来。这个表就是混淆矩阵。
针对一个二分类问题
真实值是positive,模型认为是positive的数量(True Positive=TP)
真实值是positive,模型认为是negative的数量(False Negative=FN):这就是统计学上的第一类错误(Type I Error)
真实值是negative,模型认为是positive的数量(False Positive=FP):这就是统计学上的第二类错误(Type II Error)
真实值是negative,模型认为是negative的数量(True Negative=TN)
将这四个指标一起呈现在表格中,就能得到如下这样一个矩阵,我们称它为混淆矩阵(Confusion Matrix):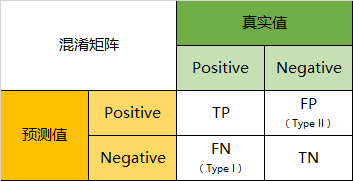
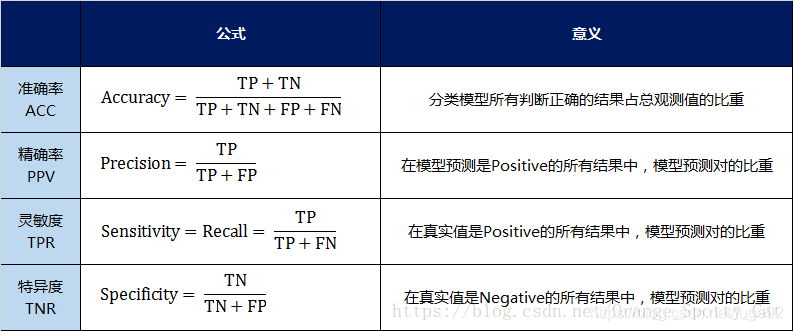
二级指标
- 准确率(Accuracy)—— 针对整个模型
- 精确率(Precision)
- 灵敏度(Sensitivity):就是召回率(Recall)
- 特异度(Specificity)
三级指标
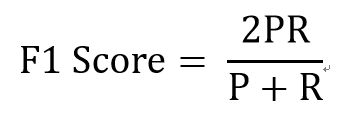
其中,P代表Precision,R代表Recall。
F1-Score指标综合了Precision与Recall的产出的结果。F1-Score的取值范围从0到1的,1代表模型的输出最好,0代表模型的输出结果最差。
auc:一个正例,一个负例,预测为正的概率值比预测为负的概率值还要大的可能性。
所以根据定义:我们最直观的有两种计算
AUC的方法
1:绘制ROC曲线,ROC曲线下面的面积就是AUC的值
2:假设总共有(m+n)个样本,其中正样本m个,负样本n个,总共有m*n个样本对,计数,正样本预测为正样本的概率值大于负样本预测为正样本的概率值记为1,累加计数,然后除以(m*n)就是AUC的值
roc
roc曲线:接收者操作特征(receiveroperating characteristic),roc曲线上每个点反映着对同一信号刺激的感受性。
横轴:负正类率(false postive rate FPR)特异度,划分实例中所有负例占所有负例的比例;(1-Specificity)
纵轴:真正类率(true postive rate TPR)灵敏度,Sensitivity(正类覆盖率)
TPR=TP/(TP+FN)
FPR=FP/(FP+TN)
https://blog.csdn.net/qq_15295565/article/details/88650944
https://blog.csdn.net/Orange_Spotty_Cat/article/details/80520839

















 2309
2309

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









