







因为数据量的限制以及训练参数的增多,几乎所有大型卷积神经网络都面临着过拟合的问题,目前常用的防止过拟合的方法有下面几种:
1. data augmentation: 这点不需要解释太多,所有的过拟合无非就是训练样本的缺乏和训练参数的增加。一般要想获得更好的模型,需要大量的训练参数,这也是为什么CNN网络越来越深的原因之一,而如果训练样本缺乏多样性,那再多的训练参数也毫无意义,因为这造成了过拟合,训练的模型泛化能力相应也会很差。大量数据带来的特征多样性有助于充分利用所有的训练参数。data augmentation的手段一般有: 1)收集更多数据 2)对已有数据进行crop,flip,加光照等操作 3)利用生成模型(比如GAN)生成一些数据。
2. weight decay: 常用的weight decay有L1和L2正则化,L1较L2能够获得更稀疏的参数,但L1零点不可导。在损失函数中,weight decay是放在正则项(regularization)前面的一个系数,正则项一般指示模型的复杂度,所以weight decay的作用是调节模型复杂度对损失函数的影响,若weight decay很大,则复杂的模型损失函数的值也就大。
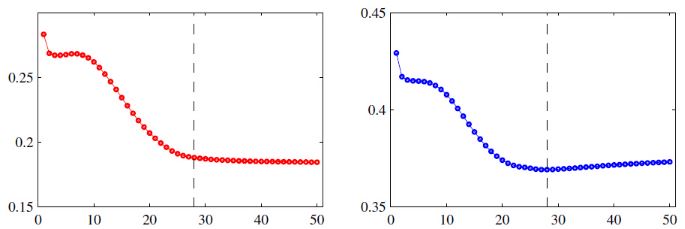
3. 提前终止: 提前停止其实是另一种正则化方法,就是在训练集和验证集上,一次迭代之后计算各自的错误率,当在验证集上的错误率最小,在没开始增大之前停止训练,因为如果接着训练,训练集上的错误率一般是会继续减小的,但验证集上的错误率会上升,这就说明模型的泛化能力开始变差了,出现过拟合问题,及时停止能获得泛化更好的模型。如下图(左边是训练集错误率,右图是验证集错误率,在虚线处提前结束训练):
4. dropout : CNN训练过程中使用dropout是在每次训练过程中随机将部分神经元的权重置为0,即让一些神经元失效,这样可以缩减参数量,避免过拟合,关于dropout为什么有效,有两种观点:1)每次迭代随机使部分神经元失效使得模型的多样性增强,获得了类似多个模型ensemble的效果,避免过拟合 2)dropout其实也是一个data augmentation的过程,它导致了稀疏性,使得局部数据簇差异性更加明显,这也是其能够防止过拟合的原因。关于dropout的解释可参考这篇博客。
......















 9592
9592

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









