









 本文详细介绍了ARM平台上的NEON技术,这是一种针对大规模并行运算的128位SIMD扩展,能显著提升消费性多媒体应用的性能。文章讲解了NEON的数据类型、指令分类,并通过实例展示了如何使用NEON内置函数加速数组元素求和,以及NEON在3x3最大池化运算中的应用。此外,还提供了NEON指令速查和相关学习资源。
本文详细介绍了ARM平台上的NEON技术,这是一种针对大规模并行运算的128位SIMD扩展,能显著提升消费性多媒体应用的性能。文章讲解了NEON的数据类型、指令分类,并通过实例展示了如何使用NEON内置函数加速数组元素求和,以及NEON在3x3最大池化运算中的应用。此外,还提供了NEON指令速查和相关学习资源。
NEON
NEON优化
NEON介绍
在移动平台上进行一些复杂算法的开发,一般需要用到指令集来进行加速。NEON 技术是 ARM Cortex™-A 系列处理器的 128 位 SIMD(单指令,多数据)架构扩展,专门针对大规模并行运算设计的,旨在为消费性多媒体应用程序提供灵活、强大的加速功能,从而显著改善用户体验。
其本质上使用的是128位NEON SIMD寄存器,这意味着如果操作32位浮点数,可同时操作4个(变量可定义:float32x4_t);如果操作 16 位整数(short),可同时操作 8 个(变量可定义:int16x8_t);而如果操作 8 位整数,则可同时操作 16 个(变量可定义:int8x16_t)。
ARMv7 NEON 指令集架构具有 16 个 128 位的向量寄存器,命名为 q0~q15。这 16 个寄存器又可以拆分成 32 个 64 位寄存器,命名为 d0~d31。其中qn和d2n,d2n+1是一样的,故使用汇编编写代码时要注意避免产生寄存器覆盖。如下图所示:
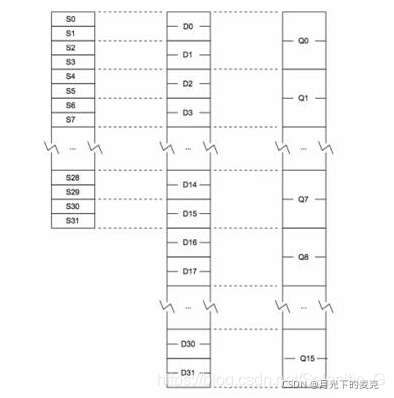
————————————————
原文链接:https://blog.csdn.net/Selenitic_G/article/details/106565566
NEON数据类型
NEON的数据类型如下图:
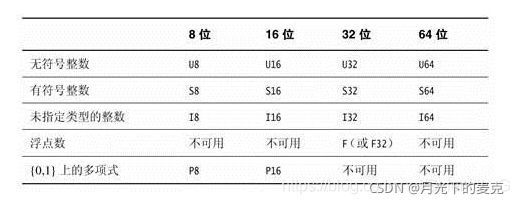
neon的数据类型float32x4_t 可以理解为vector< float32 > (4),同理typexN_t即为vector< type>(N)。在NEON编程中,对单个数据的操作可以扩展为对寄存器,也即同一类型元素矢量的操作,因此大大减少了操作次数。
NEON中指令分为正常指令、宽指令、窄指令、饱和指令、长指令这几类:
正常指令:数据宽度不变
//操作数为int16x4_t,结果数为int16x4_t
int16x4_t vadd_s16 (int16x4_t __a, int16x4_t __b);
长指令:源操作数宽度相同 结果宽度扩展 L标记
//操作数为int16x4_t,结果数为int32x4_t,vaddl_s16中l标志指令为长指令
int32x4_t vaddl_s16 (int16x4_t __a, int16x4_t __b);
宽指令:源操作数宽度不同 结果宽度对齐 W标记
//操作数一个为uint32x4_t,一个为uint16x4_t,结果对齐uint32x4_t,w标志指令为宽指令
uint32x4_t vaddw_u16 (uint32x4_t __a, uint16x4_t __b);
窄指令:源操作数宽度相同 结果宽度变窄 N标记
//操作数为uint32x4_t,结果数为uint16x4_t,n标志指令为窄指令
uint16x4_t vaddhn_u32 (uint32x4_t __a, uint32x4_t __b);
饱和指令:结果溢出就是饱和指令 Q标记
NEON官方示例及详解
通过一个示例来解释如何利用NEON内置函数来加速实现统计一个数组内的元素之和。
#include <iostream>
using namespace std;
float sum_array(float *arr, int len)
{
if(NULL == arr || len < 1)
{
cout<<"input error\n";
return 0;
}
float sum(0.0);
for(int i=0; i<len; ++i)
{
sum += *arr++;
}
return sum;
}
对于长度为N的数组,上述算法的时间复杂度为O(N)。
采用NEON函数进行加速:
#include <iostream>
#include <arm_neon.h> //需包含的头文件
using namespace std;
float sum_array(float *arr, int len)
{
if(NULL == arr || len < 1)
{
cout<<"input error\n";
return 0;
}
int dim4 = len >> 2; // 数组长度除4整数
int left4 = len & 3; // 数组长度除4余数
float32x4_t sum_vec = vdupq_n_f32(0.0);//定义用于暂存累加结果的寄存器且初始化为0
for (; dim4>0; dim4--, arr+=4) //每次同时访问4个数组元素
{
float32x4_t data_vec = vld1q_f32(arr); //依次取4个元素存入寄存器vec
sum_vec = vaddq_f32(sum_vec, data_vec);//ri = ai + bi 计算两组寄存器对应元素之和并存放到相应结果
}
//将累加结果寄存器中的所有元素相加得到最终累加值
float sum = vgetq_lane_f32(sum_vec, 0)+vgetq_lane_f32(sum_vec, 1)+vgetq_lane_f32(sum_vec, 2)+vgetq_lane_f32(sum_vec, 3);
for (; left4>0; left4--, arr++)
sum += (*arr) ; //对于剩下的少于4的数字,依次计算累加即可
return sum;
}
上述算法的时间复杂度为O(N/4),原因在于我们每次往寄存器加载4个float值,然后同时相加。相当于原来需要N次加法操作而现在只需要N/4即可。如果使用更多的寄存器,则可以完成更高倍数的加速。
上述用到的几个NEON指令解释为:
float32x4_t vdupq_n_f32(float32_t val):将val复制四份放入返回的寄存器中。
float32x4_t vld1q_f32(float32_t const * ptr):从地址ptr依次向后加载四个元素放入返回的寄存器中。
float32x4_t vaddq_f32(float32x4_t a, float32x4_t b):返回a+b的值,向量运算,四个值同时相加。
float32_t vgetq_lane_f32(float32x4_t v, const int lane):返回v中某一个lane的值
除以上的操作外,NEON还支持很多的操作,如矢量相减、矢量相乘、矢量乘加、矢量类型转换等等。
上面用到的函数有:
float32x4_t vdupq_n_f32 (float32_t value)
将value复制4分存到返回的寄存器中
float32x4_t vld1q_f32 (float32_t const * ptr)
从数组中依次Load4个元素存到寄存器中
相应的 有void vst1q_f32 (float32_t * ptr, float32x4_t val)
将寄存器中的值写入数组中
float32x4_t vaddq_f32 (float32x4_t a, float32x4_t b)
返回两个寄存器对应元素之和 r = a+b
相应的 有float32x4_t vsubq_f32 (float32x4_t a, float32x4_t b)
返回两个寄存器对应元素之差 r = a-b
float32_t vgetq_lane_f32 (float32x4_t v, const int lane)
返回寄存器某一lane的值
其他常用的函数还有:
float32x4_t vmulq_f32 (float32x4_t a, float32x4_t b)
返回两个寄存器对应元素之积 r = a*b
float32x4_t vmlaq_f32 (float32x4_t a, float32x4_t b, float32x4_t c)
r = a +b*c
float32x4_t vextq_f32 (float32x4_t a, float32x4_t b, const int n)
拼接两个寄存器并返回从第n位开始的大小为4的寄存器 0<=n<=3
例如
a: 1 2 3 4
b: 5 6 7 8
vextq_f32(a,b,1) -> r: 2 3 4 5
vextq_f32(a,b,2) -> r: 3 4 5 6
vextq_f32(a,b,3) -> r: 4 5 6 7
float32x4_t sum = vdupq_n_f32(0);
float _a[] = {1,2,3,4}, _b[] = {5,6,7,8} ;
float32x4_t a = vld1q_f32(_a), b = vld1q_f32(_b) ;
float32x4_t sum1 = vfmaq_laneq_f32(sum, a, b, 0);
float32x4_t sum2 = vfmaq_laneq_f32(sum1, a, b, 1);
float32x4_t sum3 = vfmaq_laneq_f32(sum2, a, b, 2);参考代码注释:
float32x4_t _r00 = vld1q_f32(r0);//将r0开头的4个连续地址存放的数据load到neon寄存器
float32x4_t _r10 = vld1q_f32(r1);
float32x4_t _r20 = vld1q_f32(r2);
float32x4_t _r30 = vld1q_f32(r3);
float32x4_t _sum = vmulq_f32(_r00, _k0123);//两个参数的点乘
_sum = vmlaq_f32(_sum, _r10, _k3456);//_sum + _r10 .* _k3456, 点对点操作
_sum = vmlaq_f32(_sum, _r20, _k6789);
float32x4_t _sum2 = vmulq_f32(_r10, _k0123);
_sum2 = vmlaq_f32(_sum2, _r20, _k3456);
_sum2 = vmlaq_f32(_sum2, _r30, _k6789);
_sum = vsetq_lane_f32(*outptr, _sum, 3);//*outptr赋值给将_sum中index为3的元素(即最后一个),为累加做准备
_sum2 = vsetq_lane_f32(*outptr2, _sum2, 3);
float32x2_t _ss = vadd_f32(vget_low_f32(_sum), vget_high_f32(_sum));//将128位寄存器中高64的两个参数与低68位的两个参数对应相加
float32x2_t _ss2 = vadd_f32(vget_low_f32(_sum2), vget_high_f32(_sum2));
float32x2_t _sss2 = vpadd_f32(_ss, _ss2);//adds adjacent pairs of elements of two vectors
*outptr = vget_lane_f32(_sss2, 0);//get 0th parameter in vector
*outptr2 = vget_lane_f32(_sss2, 1);
NEON 3x3 max pool示例代码
constexpr const int pool_size = 3;
const float32x4_t top_data = vld1q_f32(reinterpret_cast<const float *>(input_top_ptr + input.offset()));
const float32x4_t middle_data = vld1q_f32(reinterpret_cast<const float *>(input_middle_ptr + input.offset()));
const float32x4_t bottom_data = vld1q_f32(reinterpret_cast<const float *>(input_bottom_ptr + input.offset()));
float32x2_t res = {};
if(pooling_type == PoolingType::AVG)
{
// Calculate scale
float scale = calculate_avg_scale(id, pool_size, upper_bound_w, upper_bound_h, pool_pad_x, pool_pad_y, pool_stride_x, pool_stride_y);
const float32x2_t scale_v = vdup_n_f32(scale);
// Perform pooling
const float32x4_t sum_data = vaddq_f32(vaddq_f32(top_data, bottom_data), middle_data);
res = vpadd_f32(vget_high_f32(vsetq_lane_f32(0.f, sum_data, 3)), vget_low_f32(sum_data));
res = vmul_f32(vpadd_f32(res, res), scale_v);//得到4个最大的float
}
else
{
const float32x4_t max_data = vmaxq_f32(vmaxq_f32(top_data, bottom_data), middle_data);
res = vpmax_f32(vget_high_f32(vsetq_lane_f32(-std::numeric_limits<float>::max(), max_data, 3)), vget_low_f32(max_data));
res = vpmax_f32(res, res);
}
*(reinterpret_cast<float *>(output.ptr())) = vget_lane_f32(res, 0);NEON手册
以下链接为NEON内置函数的手册,当需要用到某些NEON操作时,可以通过手册查看使用方法。
优秀博文学习
重点学习:CPU 优化技术-NEON 指令介绍


















 1122
1122

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











