






一、AIDC和传统IDC的区别和联系?
从IDC发展历程分析,智算中心[下文简称AIDC]和传统的IDC,超算中心等,并没有特别本质的变化,个人认为只是换了一个叫法或别名。
如果一定要总结区别,要从智算中心新型业务特点出发,比如算力种类,规模,单柜密度,PUE和液冷,网络带宽和种类,存储种类等有新的变化。网上对应AIDC-智算中心的分析很多,从不同的角度,所侧重的技术领域有所差距,打个比方做算力强调算力多样化,做网络的强调IB和ROCE组网,做存储的强调GDS和并行的性能等。
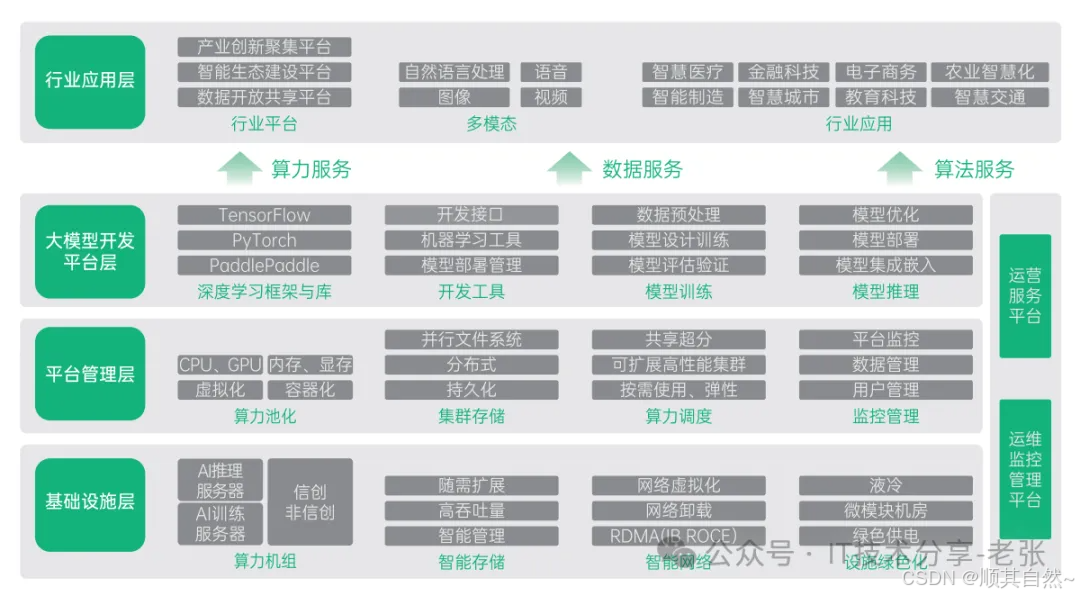
智算中心建设-架构图
二、AIDC的智能算力(从传统CPU算力到AI算力)
1、GPU算力:AIDC建设除了通用的CPU算力外,最重要的是新增了GPU相关的算力比例。各类GPU类加速芯片占主导,比如GPGPU,IPU,DPU,ASIC、FPGA等,NVDIA的产品目前依然是top1,但是国内也形成了群雄割据的场面。
2、业务特点:以“文生文、文生图、文生视频”为代表的AI内容生成产业极大的推动了AIDC的建设和发展。尤其是对GPU加速算力产品的需要,AI大模型训练和推理都需要强大的GPU类算力作为支撑。
3、发展现状:受漂亮国芯片禁令的持续影响,英伟达GPU卡的供货存在很大不确定性,以HW肾疼为代表国产加速卡迎来发展的好机遇,但从芯片算力和和供应的方面还需持续的创新和突破。

三、网络要求无损和高带宽(IB、Roce成为主流)
1、发展变化:AI训练和推理需要大规模的算力支撑,需要超高速,低延时,无阻塞的RAMD网络。从已有产品方案来看,英伟达Mellanox的IB方案天然支持RAMD,在IB领域也是没有对手,从速率的角度400G、200G成为标配,带来的网络建设成本持续攀升。
2、方案规划:除了Mellanox的IB方案。另一个RDMA ROCE的技术也逐渐被头部玩家采纳。因为同样支持Rdma,但是方案成本比ib低很多,产品和方案的选择上更加多元(HW,H3C等做网络的厂商都可以),整体使用性能和IB网络基本一致,实事求是讲延迟方面还有一些距离。
3、网络接口:GPU类Server需要配对应的NIC,PCIe Gen4的server平台支持最高到单口200Gb,最新的server处理器Intel和AMD的四代U,已经 支持PCIe GEN5,单口网卡(PCIex16)可以支持到400Gb/s。
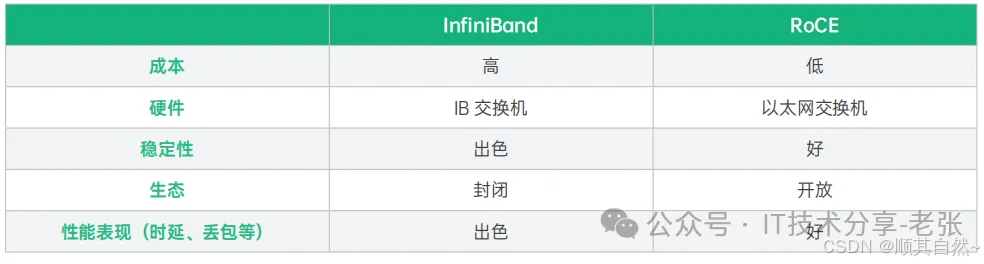
InfniBand 和 RoCE 网络解决方案特点对比表
四、存储的容量和性能要求更高
1、作为数据中心的三大件,算力、存储网络是相互配套的,因此存储系统在AIDC建设中同样有新的要求,新建AIDC不仅关注存储的IO性能和存储容量,还需要重点考虑GDS(GPU和存储系统直接通信技术),它主要做到了GPU直连在存储系统进行读写操作,这样性能可以达到最优,还有就是并行支持,和高性能计算场景形似,人工智能大模型的在训练过程中的数据量和数据流,必须支持并行的操作(并行文件系统)。
2、主流的分布式存储包括GPFS、Lustre等,由于必须支持GDS和并行操作,因此Lustre和GPFS应用较多,另外从性价比和灵活度的角度考虑,Lustre都支持更灵活,适合于大文件的连续读写,GPFS比较成熟,它源于IBM,更适合于海量小文件,。
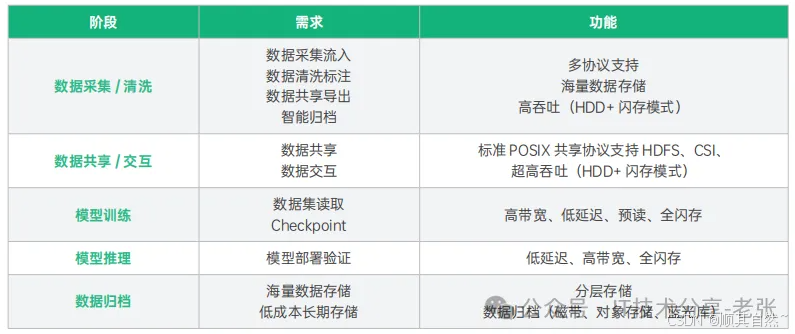
AIGC 数据处理各阶段需求与功能特点
五、AIDC对PUE要求更低(和国家双碳政策吻合)
1、PUE的概念是数据中心的总用电量除以IT设备的总用电量,这个值肯定是大于1的(目前IDC的PUE在1.4到1.8就),随着国家双碳政策推动,不同地区的新建IDC的PUE有新的要求,比如要求在1.2-1.25,这个对于CPU或GPU的单芯片功耗(CPU 400W、GPU 700W)越来越高,传统的风冷散热方案也将遇到瓶颈,液冷成为新宠。
2、液冷的建设有三个典型方案,分为冷板式、喷淋式和浸没式,市场主流的是冷板式方案,从服务器产品的交付到旧产品的升级改造冷板式的方案门槛最低,NVIDIA的最新产品GB200,NVL72也是采用液冷冷板,也推动了液冷市场的火爆。

六、AIDC的“投建运”
1、投:顾名思义,就是AIDC建设的钱谁来投资,有以下几类情形,甲方有钱,可以全资(需求方)、如果甲方钱不够-需要引入资方(金融类机构和公司)共同投资、如果甲方不想出-需要找资方垫资。
2、建:这个部分主要是AIDC的设计和建设,包括方案的规划,设备选型及实施交付等,牵头方可以是甲方、厂商或者大集成商;
3、运:包括两个方面,运维和运营,需要解决AIDC建成以后怎么维护、运营商业模式,实现盈利,除了自用外、还需要考虑算力出租和混合模式(自用为主,富余的算力出租);

智算中心的几个基本阶段
七、AIDC基础设施领域的上-中-下游
1、上游(金字塔塔尖):以GPU加速芯片类公司为主,市场上最活跃,包括NVIDIA、牙膏厂、按摩店和各个国产芯片厂商,同时以液冷等等数据基础设施的公司也是迎来业务增长爆发。
2、中游(整机厂商和资金主要玩家):像Inspur、H3C、超云等厂商,因为算力设备占比高。还包括网络、存储、安全和配套的软件公司,拥有垫资实力的集成公司或者金融类机构公司。
3、下游(使用方和购买方):除了头部的互联网大厂外,各地算力公司如雨后春笋爆发,鱼龙混杂,比如莲花味精大批量采购GPU服务器(专门智算公司),真正的使用者除了AI相关领域公司,也面向传统行业,尤其是对采购NVIDIA有风险的企业或者机构;

八、旧转新智算中心技术会遇到哪些问题?
1、硬件:旧服务器对GPU等AI芯片的扩展能力差,利旧困难,基本用不了,包括网络、存储以及配套的供电、散热都需要重新规划。
2、软件:智算中心往往需要增加AI相关软件和平台以适配新的业务,比如对GPU资源的管理调度,需要适配各类AI框架、架构和算法模型的环境。
3、人员:因为涉及管理和运维AI相关软硬件,智算中心的运维人员专业知识的赋能,面临运维成本的增加(培养和新招)。
九、旧转新智算中心需要考虑涉及哪些投入
改造成本(TC)可以大致分为以下几部分:TC=硬件成本(HC)+软件成本(SC)+运维成本(OC)+能耗成本(EC)+其他成本(MiscC)
十、智算中心未来预测,有哪些风险?
1、对于以租赁为目的智算中心或者自用率占比不高的,回本周期非常关键,往往需要在3-5年,会面临中途断租的风险。
2、Nvlink机器的保修风险,众所周知的原因,随着设备的使用,故障率会逐步提升,正常质保通道不通畅,风险很大。
3、国产AI卡真正的前景不清晰,厂商角度都在大吹特吹,但是市场未充分验证,对原厂的技术调优依赖强,风险不可控。
4、竞争激烈利润低,现在遍地开花,大投入,快建设,强竞争,市场优胜劣汰,不可控AI降温、芯片升级(H800、A800可能不值钱了),1-2年内谁能坚持下来,不好说,洗牌是必然。

















 754
754

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









