







参考:https://blog.csdn.net/u013517182/article/details/93043942
https://blog.csdn.net/a314688122a/article/details/81505082
1 Xshell通道设置
文件-新建-连接-SSH-隧道,端口都设成6006

2 进入环境安装tensorboradX
pip install tensorboardX

3 修改训练代码
需要添加的代码:
1.头部
from tensorboardX import SummaryWriter
writer = SummaryWriter('./log')
后面路径是日志存的路径
2.找到定义的train函数
niter = epoch * len(train_loader) + i
writer.add_scalars('Train_loss', {'train_loss': loss.data.item()}, niter)
字典中得key是曲线的名称,后面的value是对应得append的值,再后面得niter是x坐标,对于图名称为’Train_loss’的图,对曲线名称为’train_loss’添加新的点,这个点为(niter, loss.data.item())
保存并运行这个训练文件
4 打开终端,输入
tensorboard --logdir ./log --port 6006
5 浏览器端输入127.0.0.1:6006
就可以看到了loss曲线

6 实例-以训练places365数据集为例
数据集是从原数据集中每个类中随机选10张出来的缩小版本,原来的训练要很久很久5555
# this code is modified from the pytorch example code: https://github.com/pytorch/examples/blob/master/imagenet/main.py
# after the model is trained, you might use convert_model.py to remove the data parallel module to make the model as standalone weight.
#
# Bolei Zhou
import argparse
import os
import shutil
import time
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.backends.cudnn as cudnn
import torch.optim
import torch.utils.data
import torchvision.transforms as transforms
import torchvision.datasets as datasets
import torchvision.models as models
from tensorboardX import SummaryWriter
import wideresnet
import pdb
writer = SummaryWriter('./log')
model_names = sorted(name for name in models.__dict__
if name.islower() and not name.startswith("__")
and callable(models.__dict__[name]))
parser = argparse.ArgumentParser(description='PyTorch Places365 Training')
parser.add_argument('data', metavar='DIR',
help='path to dataset')
parser.add_argument('--arch', '-a', metavar='ARCH', default='resnet18',
help='model architecture: ' +
' | '.join(model_names) +
' (default: resnet18)')
parser.add_argument('-j', '--workers', default=6, type=int, metavar='N',
help='number of data loading workers (default: 4)')
parser.add_argument('--epochs', default=90, type=int, metavar='N',
help='number of total epochs to run')
parser.add_argument('--start-epoch', default=0, type=int, metavar='N',
help='manual epoch number (useful on restarts)')
parser.add_argument('-b', '--batch-size', default=256, type=int,
metavar='N', help='mini-batch size (default: 256)')
parser.add_argument('--lr', '--learning-rate', default=0.1, type=float,
metavar='LR', help='initial learning rate')
parser.add_argument('--momentum', default=0.9, type=float, metavar='M',
help='momentum')
parser.add_argument('--weight-decay', '--wd', default=1e-4, type=float,
metavar='W', help='weight decay (default: 1e-4)')
parser.add_argument('--print-freq', '-p', default=10, type=int,
metavar='N', help='print frequency (default: 10)')
parser.add_argument('--resume', default='', type=str, metavar='PATH',
help='path to latest checkpoint (default: none)')
parser.add_argument('-e', '--evaluate', dest='evaluate', action='store_true',
help='evaluate model on validation set')
parser.add_argument('--pretrained', dest='pretrained', action='store_false',
help='use pre-trained model')
parser.add_argument('--num_classes',default=365, type=int, help='num of class in the model')
parser.add_argument('--dataset',default='places365',help='which dataset to train')
best_prec1 = 0
def main():
global args, best_prec1
args = parser.parse_args()
print args
# create model
print("=> creating model '{}'".format(args.arch))
if args.arch.lower().startswith('wideresnet'):
# a customized resnet model with last feature map size as 14x14 for better class activation mapping
model = wideresnet.resnet50(num_classes=args.num_classes)
else:
model = models.__dict__[args.arch](num_classes=args.num_classes)
if args.arch.lower().startswith('alexnet') or args.arch.lower().startswith('vgg'):
model.features = torch.nn.DataParallel(model.features)
model.cuda()
else:
model = torch.nn.DataParallel(model).cuda()
print model
# optionally resume from a checkpoint
if args.resume:
if os.path.isfile(args.resume):
print("=> loading checkpoint '{}'".format(args.resume))
checkpoint = torch.load(args.resume)
args.start_epoch = checkpoint['epoch']
best_prec1 = checkpoint['best_prec1']
model.load_state_dict(checkpoint['state_dict'])
print("=> loaded checkpoint '{}' (epoch {})"
.format(args.resume, checkpoint['epoch']))
else:
print("=> no checkpoint found at '{}'".format(args.resume))
print("=> no checkpoint found at '{}'".format(args.resume))
cudnn.benchmark = True
# Data loading code
traindir = os.path.join(args.data, 'train')
valdir = os.path.join(args.data, 'val')
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
train_loader = torch.utils.data.DataLoader(
datasets.ImageFolder(traindir, transforms.Compose([
transforms.RandomSizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
normalize,
])),
batch_size=args.batch_size, shuffle=True,
num_workers=args.workers, pin_memory=True)
val_loader = torch.utils.data.DataLoader(
datasets.ImageFolder(valdir, transforms.Compose([
transforms.Scale(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
normalize,
])),
batch_size=args.batch_size, shuffle=False,
num_workers=args.workers, pin_memory=True)
# define loss function (criterion) and pptimizer
criterion = nn.CrossEntropyLoss().cuda()
optimizer = torch.optim.SGD(model.parameters(), args.lr,
momentum=args.momentum,
weight_decay=args.weight_decay)
if args.evaluate:
validate(val_loader, model, criterion)
return
for epoch in range(args.start_epoch, args.epochs):
adjust_learning_rate(optimizer, epoch)
# train for one epoch
train(train_loader, model, criterion, optimizer, epoch)
# evaluate on validation set
prec1 = validate(val_loader, model, criterion)
# remember best prec@1 and save checkpoint
is_best = prec1 > best_prec1
best_prec1 = max(prec1, best_prec1)
save_checkpoint({
'epoch': epoch + 1,
'arch': args.arch,
'state_dict': model.state_dict(),
'best_prec1': best_prec1,
}, is_best, args.arch.lower())
def train(train_loader, model, criterion, optimizer, epoch):
batch_time = AverageMeter()
data_time = AverageMeter()
losses = AverageMeter()
top1 = AverageMeter()
top5 = AverageMeter()
# switch to train mode
model.train()
end = time.time()
for i, (input, target) in enumerate(train_loader):
# measure data loading time
data_time.update(time.time() - end)
target = target.cuda(async=True)
input_var = torch.autograd.Variable(input)
target_var = torch.autograd.Variable(target)
# compute output
output = model(input_var)
loss = criterion(output, target_var)
# measure accuracy and record loss
prec1, prec5 = accuracy(output.data, target, topk=(1, 5))
losses.update(loss.item(), input.size(0))
top1.update(prec1.item(), input.size(0))
top5.update(prec5.item(), input.size(0))
# compute gradient and do SGD step
optimizer.zero_grad()
loss.backward()
optimizer.step()
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % args.print_freq == 0:
print('Epoch: [{0}][{1}/{2}]\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Data {data_time.val:.3f} ({data_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Prec@1 {top1.val:.3f} ({top1.avg:.3f})\t'
'Prec@5 {top5.val:.3f} ({top5.avg:.3f})'.format(
epoch, i, len(train_loader), batch_time=batch_time,
data_time=data_time, loss=losses, top1=top1, top5=top5))
niter = epoch * len(train_loader) + i
writer.add_scalars('Train_loss', {'train_loss': loss.data.item()}, niter)
writer.close()
print('Finished Training')
def validate(val_loader, model, criterion):
batch_time = AverageMeter()
losses = AverageMeter()
top1 = AverageMeter()
top5 = AverageMeter()
# switch to evaluate mode
model.eval()
end = time.time()
for i, (input, target) in enumerate(val_loader):
target = target.cuda(async=True)
with torch.no_grad():
input_var = torch.autograd.Variable(input)
with torch.no_grad():
target_var = torch.autograd.Variable(target)
# compute output
output = model(input_var)
loss = criterion(output, target_var)
# measure accuracy and record loss
prec1, prec5 = accuracy(output.data, target, topk=(1, 5))
losses.update(loss.data.item(), input.size(0))
top1.update(prec1.item(), input.size(0))
top5.update(prec5.item(), input.size(0))
# measure elapsed time
batch_time.update(time.time() - end)
end = time.time()
if i % args.print_freq == 0:
print('Test: [{0}/{1}]\t'
'Time {batch_time.val:.3f} ({batch_time.avg:.3f})\t'
'Loss {loss.val:.4f} ({loss.avg:.4f})\t'
'Prec@1 {top1.val:.3f} ({top1.avg:.3f})\t'
'Prec@5 {top5.val:.3f} ({top5.avg:.3f})'.format(
i, len(val_loader), batch_time=batch_time, loss=losses,
top1=top1, top5=top5))
niter = epoch * len(train_loader) + i
writer.add_scalars('Val_loss', {'val_loss': mean_loss}, niter)
write.close()
print(' * Prec@1 {top1.avg:.3f} Prec@5 {top5.avg:.3f}'
.format(top1=top1, top5=top5))
return top1.avg
def save_checkpoint(state, is_best, filename='checkpoint.pth.tar'):
torch.save(state, filename + '_latest.pth.tar')
if is_best:
shutil.copyfile(filename + '_latest.pth.tar', filename + '_best.pth.tar')
class AverageMeter(object):
"""Computes and stores the average and current value"""
def __init__(self):
self.reset()
def reset(self):
self.val = 0
self.avg = 0
self.sum = 0
self.count = 0
def update(self, val, n=1):
self.val = val
self.sum += val * n
self.count += n
self.avg = self.sum / self.count
def adjust_learning_rate(optimizer, epoch):
"""Sets the learning rate to the initial LR decayed by 10 every 30 epochs"""
lr = args.lr * (0.1 ** (epoch // 30))
for param_group in optimizer.param_groups:
param_group['lr'] = lr
def accuracy(output, target, topk=(1,)):
"""Computes the precision@k for the specified values of k"""
maxk = max(topk)
batch_size = target.size(0)
_, pred = output.topk(maxk, 1, True, True)
pred = pred.t()
correct = pred.eq(target.view(1, -1).expand_as(pred))
res = []
for k in topk:
correct_k = correct[:k].view(-1).float().sum(0)
res.append(correct_k.mul_(100.0 / batch_size))
return res
if __name__ == '__main__':
main()
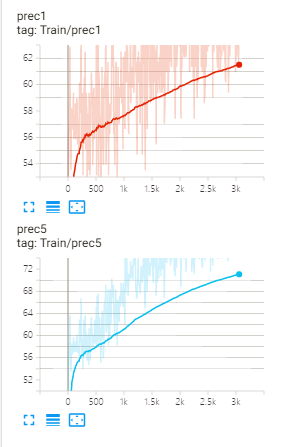
7 acc曲线

最后效果:

top1和top5:















 151
151











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









