






环境
Python 3.x
Scikit-learn库
Jupyter Notebook或类似IDE(用于代码编写和结果展示)
数据集
使用Scikit-learn自带的fetch_20 Newsgroups数据集。该数据集包含来自20个不同新闻组的文本数据。每个新闻组都包含多篇新闻文档,总共约有18,000篇文档。涵盖了多个主题,包括科技、政治、体育、娱乐等。每个文档都被分配了一个特定的标签,表示其所属的新闻组类别。fetch_20newsgroups数据集是一个常用的用于文本分类任务和主题建模任务的基准数据集之一。
步骤
1. 导入必要的库
导入Scikit-learn中的用于朴素贝叶斯、特征提取、数据分割等的相关模块。
2. 加载、划分数据集
使用Scikit-Learn的datasets模块加载20 Newsgroups数据集。(数据集较大,加载时间可能比较长,耐心等待)
使用train_test_split函数将数据集划分为训练集和测试集。
3. 数据预处理
将新闻文本数据进行特征工程处理,即将新闻文本进行分词,统计每个词的出现频数,将代表性的词汇与文本分类结果对应。常用于文本分类的特征工程为TF-IDF(Term Frequency-Inverse Document Frequency, 词频-逆文档频率)。它是一种常见的加权统计方法,用于评估每个词汇对每篇文章的重要程度。
4. 使用朴素贝叶斯分类器进行分类
实例化一个朴素贝叶斯分类器,并将我们的训练集特征与训练集特征对应的分类结果导入到模型中,供分类器学习,并预测试集。
流程
多项式朴素贝叶斯:
导入必要的库/模块
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
图片1
加载20类新闻数据集
# 读取训练数据
news = fetch_20newsgroups(subset='all')
图片2
数据集分析:
1、数据集信息
数据集形状 (18846,)
================= ==========
Classes 20
Samples total 18846
Dimensionality 1
Features text
================= ==========
2、数据集标签20类别
newsgroups = fetch_20newsgroups(subset='train', categories=None, shuffle=True, random_state=42)
newsgroups.target_names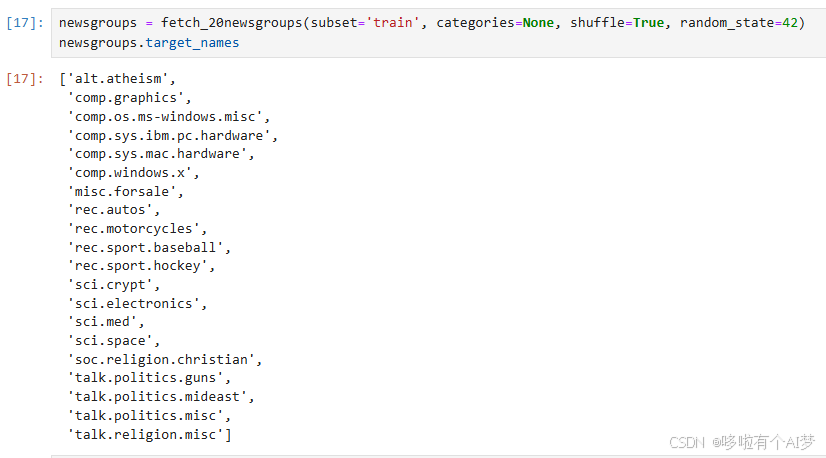
图片3
划分训练集和测试集
# 进行数据的分割训练集合测试集
# X_train是样本训练集,X_test是样本测试集;y_train是样本训练集对应的标签集,y_test是样本测试集对应的标签集
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25)
图片4
使用TF-IDF向量化文本数据
# 使用TF-IDF向量化文本数据
tfidf_vectorizer = TfidfVectorizer(stop_words='english')
X_train_tfidf = tfidf_vectorizer.fit_transform(x_train)
X_test_tfidf = tfidf_vectorizer.transform(x_test)
图片5
初始化多项式朴素贝叶斯模型
# 初始化多项式朴素贝叶斯模型
multinomial_nb = MultinomialNB()
图片6
训练模型
# 训练模型
multinomial_nb.fit(X_train_tfidf, y_train)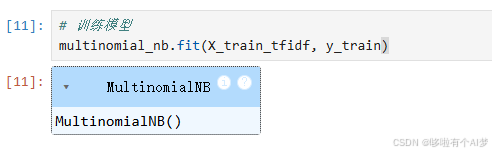
图片7
模型预测
# 模型预测
y_pred = multinomial_nb.predict(X_test_tfidf)
图片8

图片9
计算准确率
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.4f}")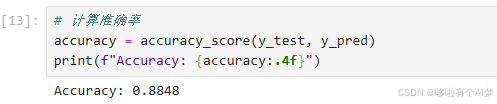
图片10
输出分类报告
# 输出分类报告
print("Classification Report:")
print(classification_report(y_test, y_pred))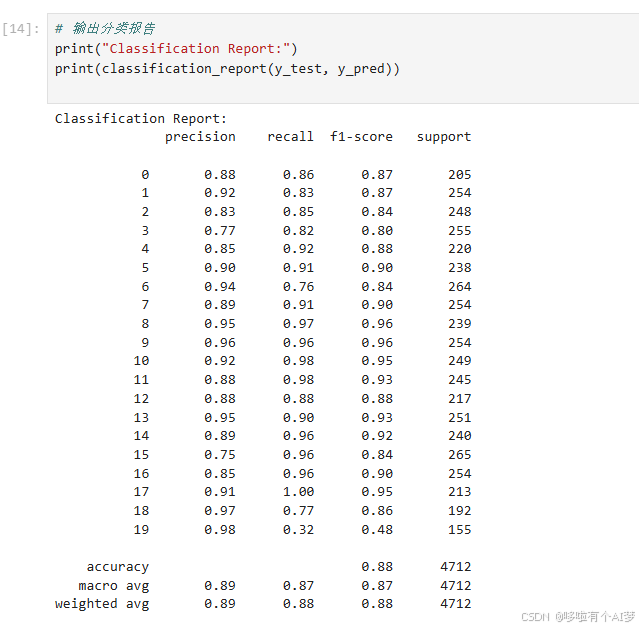
图片11
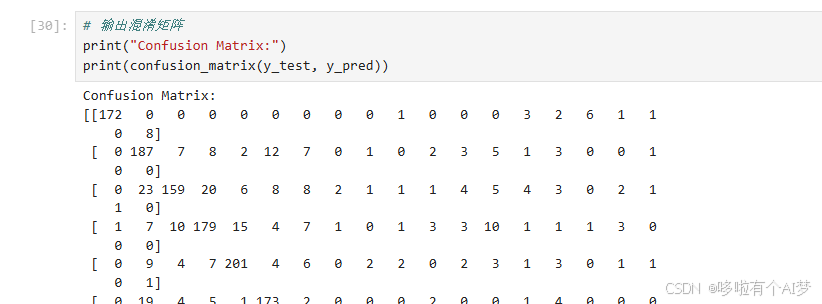
输出混淆矩阵
# 输出混淆矩阵
print("Confusion Matrix:")
print(confusion_matrix(y_test, y_pred))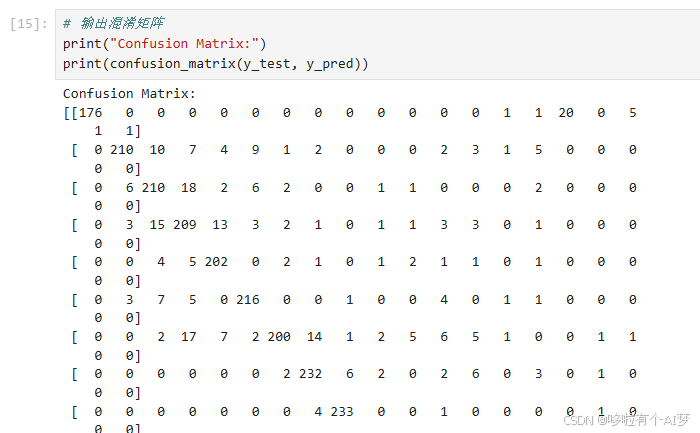
图片12
使用高斯朴素贝叶斯(常用于连续数据)进行分类任务
导入必要的库/模块
比先前朴素贝叶斯增加两个模块

图片13
加载20类新闻数据集和划分训练集和测试集同前面朴素贝叶斯

图片14
因为高斯朴素贝叶斯通常用于连续数据,而不是文本数据。对于文本数据,我们通常需要将其转换为词频或TF-IDF等数值特征。所以使用词频向量化文本数据。

图片15
CountVectorizer和TfidfVectorizer默认输出稀疏矩阵,因为文本数据通常是高维稀疏的。为了解决这个问题,需要将稀疏矩阵转换为密集矩阵。可以通过调用.toarray()方法来实现。

图片16
初始化高斯朴素贝叶斯模型并进行训练,高斯朴素贝叶斯,将稀疏矩阵转换为密集矩阵会显著增加计算量和内存需求,从而增加训练时间,所以训练时间较长
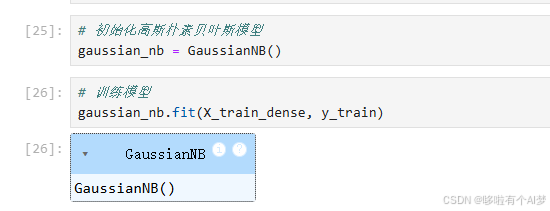
图片17
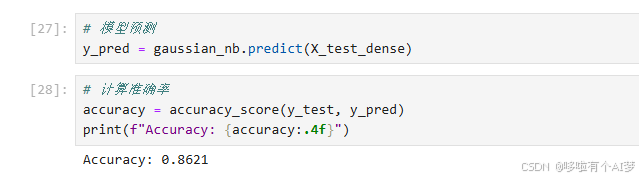
进行模型预测并计算准确率,准确率比多项式朴素贝叶斯高一点。
图片18
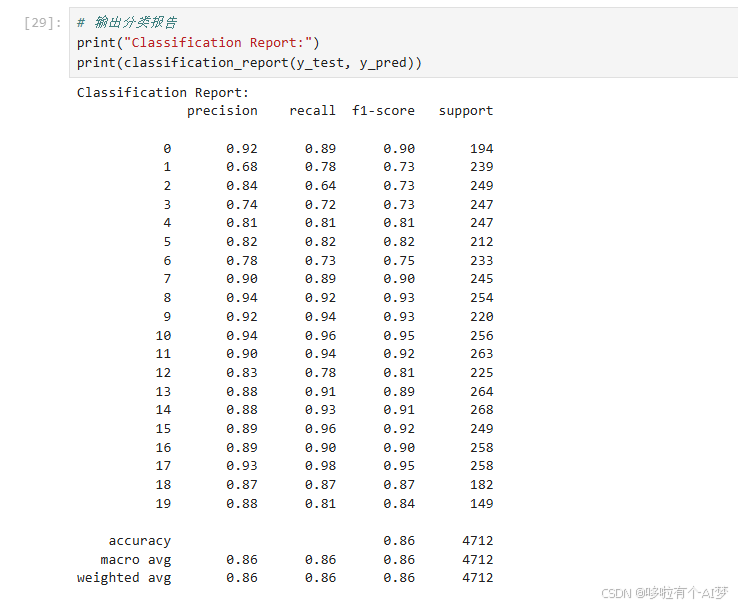
输出分类报告和混淆矩阵
图片19
图片20
高斯朴素贝叶斯完整代码:
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import GaussianNB
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# 读取训练数据
news = fetch_20newsgroups(subset='all')
# 进行数据的分割训练集合测试集
# X_train是样本训练集,X_test是样本测试集;y_train是样本训练集对应的标签集,y_test是样本测试集对应的标签集
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25)
# 使用词频向量化文本数据
count_vectorizer = CountVectorizer(stop_words='english')
X_train_counts = count_vectorizer.fit_transform(x_train)
X_test_counts = count_vectorizer.transform(x_test)
# 将稀疏矩阵转换为密集矩阵
X_train_dense = X_train_counts.toarray()
X_test_dense = X_test_counts.toarray()
# 初始化高斯朴素贝叶斯模型
gaussian_nb = GaussianNB()
# 训练模型
gaussian_nb.fit(X_train_dense, y_train)
# 模型预测
y_pred = gaussian_nb.predict(X_test_dense)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.4f}")
# 输出分类报告
print("Classification Report:")
print(classification_report(y_test, y_pred))
# 输出混淆矩阵
print("Confusion Matrix:")
print(confusion_matrix(y_test, y_pred))伯努利朴素贝叶斯:
增加以下模块:

图片21
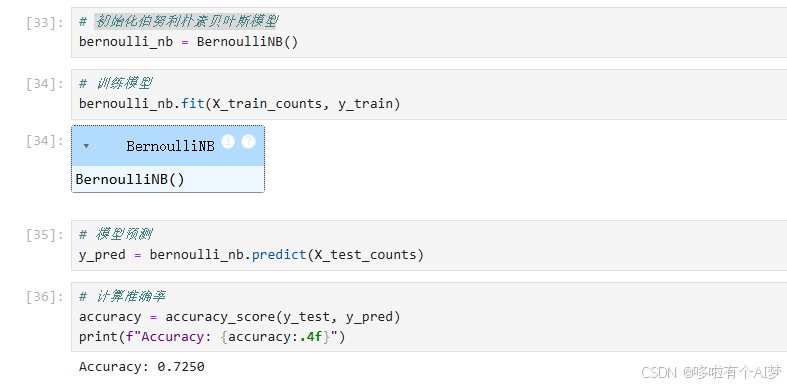
重复上述过程,我们发现,准确率相较于多项式贝叶斯较低。
图片22
伯努利朴素贝叶斯完整代码:
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import BernoulliNB
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# 读取训练数据
news = fetch_20newsgroups(subset='all')
# 进行数据的分割训练集合测试集
# X_train是样本训练集,X_test是样本测试集;y_train是样本训练集对应的标签集,y_test是样本测试集对应的标签集
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25)
# 使用词频向量化文本数据
count_vectorizer = CountVectorizer(stop_words='english')
X_train_counts = count_vectorizer.fit_transform(x_train)
X_test_counts = count_vectorizer.transform(x_test)
# 初始化伯努利朴素贝叶斯模型
bernoulli_nb = BernoulliNB()
# 训练模型
gaussian_nb.fit(X_train_dense, y_train)
# 模型预测
y_pred = bernoulli_nb.predict(X_test_counts)
# 计算准确率
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.4f}")
# 输出分类报告
print("Classification Report:")
print(classification_report(y_test, y_pred))
# 输出混淆矩阵
print("Confusion Matrix:")
print(confusion_matrix(y_test, y_pred))
















 4124
4124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









