






环境
Python编程语言
Scikit-learn库
Matplotlib或seaborn(用于数据可视化)
NumPy和Pandas库(用于数据处理)
Jupyter Notebook或类似IDE(用于代码编写和结果展示)
数据集
使用 California Housing 数据集:此数据集包含加利福尼亚州的房屋数据,包括多个特征(如房间数量、人口、平均收入等)以及目标变量 MedHouseVal(房价中位数,单位为千美元)。
步骤
1. 数据加载与初步探索
使用 fetch_california_housing 函数加载 California Housing 数据集。
将数据加载为 Pandas DataFrame,并对数据的基本统计信息、分布情况等进行探索性分析。
使用 Pandas、Matplotlib 等工具对数据进行初步探索。
2. 数据集划分
使用 train_test_split 方法将数据集分为训练集和测试集(80% 用于训练,20% 用于测试)。
3. 模型训练与预测
使用 LinearRegression 创建线性回归模型,并使用训练集对模型进行训练。
利用训练好的模型对测试集进行预测,并生成预测的房价数据。
4. 模型性能评估
使用 mean_squared_error 计算均方误差(MSE),评估预测值与实际值的差异。
使用 r2_score 计算 R² 分数,评估模型的拟合优度。
5. 结果可视化
绘制测试集实际房价与预测房价的对比图,直观展示模型的预测效果。
添加参考线帮助理解模型的预测偏差。
结果展示
均方误差(MSE):展示测试集上的均方误差,以量化模型的平均预测误差。
R² 分数:展示模型的 R² 分数,表示模型解释目标变量方差的比例。
实际房价与预测房价对比图:图表展示了测试集上实际房价与预测房价的关系,以便直观理解模型的表现。
代码参考
以下是一个通过线性回归模型来预测加利福尼亚州各区域房价的代码实例:
导入必要的库
import numpy as np # 用于科学计算的库,提供数组支持
import pandas as pd # 用于数据处理的库
import matplotlib.pyplot as plt # 用于绘图
import seaborn as sns # 提供更美观的绘图样式
from sklearn.datasets import fetch_california_housing # 加载California房价数据集
from sklearn.model_selection import train_test_split # 数据集划分函数
from sklearn.linear_model import LinearRegression # 线性回归模型
from sklearn.metrics import mean_squared_error, r2_score # 评价指标:均方误差和R²分数加载加利福尼亚房价数据集
california_housing = fetch_california_housing()数据集介绍:
加利福尼亚房价数据集是由美国人口普查局(U.S. Census Bureau)提供的数据,它包含了1990年时加利福尼亚州的10个区域(即块)数据。这些区域的特征反映了该地区的地理和人口统计信息,如房屋的规模、收入水平等。
数据集的结构:
数据集包含了 20,640 个样本(即区域的数量),每个样本具有 8 个特征,以及 1 个目标变量(即房价中位数)。
m,n=california_housing.data.shape
print(california_housing.keys())
print(california_housing.feature_names)
print(california_housing.target)
print(california_housing.DESCR)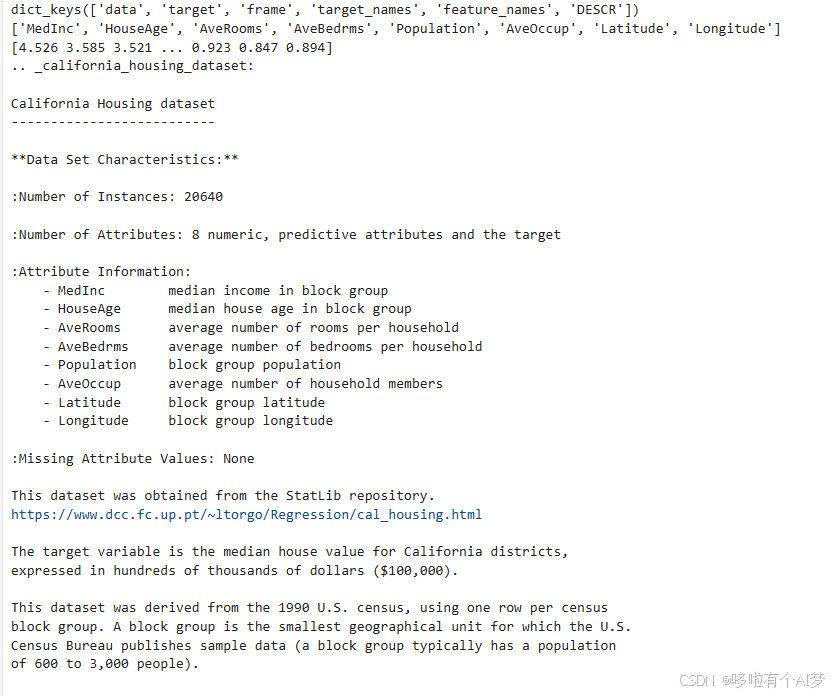 图片1
图片1
我们从图中可以看出该数据的列名为['MedInc', 'HouseAge', 'AveRooms', 'AveBedrms', 'Population', 'AveOccup', 'Latitude', 'Longitude']
数据特征具体含义;
MedInc:区域内家庭收入的中位数(单位:10,000美元)。
HouseAge:房屋的中位数年龄(单位:年)。
AveRooms:每个住宅单元的平均房间数。
AveBedrms:每个住宅单元的平均卧室数。
Population:区域内的总人口数量。
AveOccup:每个住宅单元的平均住户人数。
Latitude:区域的纬度(地理坐标)。
Longitude:区域的经度(地理坐标)。
MedHouseVal:目标变量,区域内房价的中位数(单位:10,000美元),这是我们想要预测的目标。
将数据集转换为DataFrame并添加列名
df = pd.DataFrame(california_housing.data, columns=california_housing.feature_names)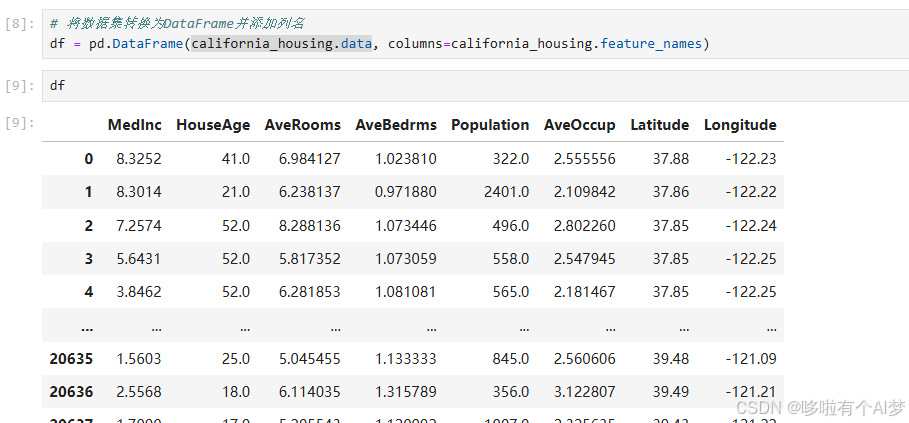
图片2
将目标值转为Series对象
target = pd.Series(california_housing.target, name='MedHouseVal')
df['MedHouseVal'] = target# 合并特征和目标变量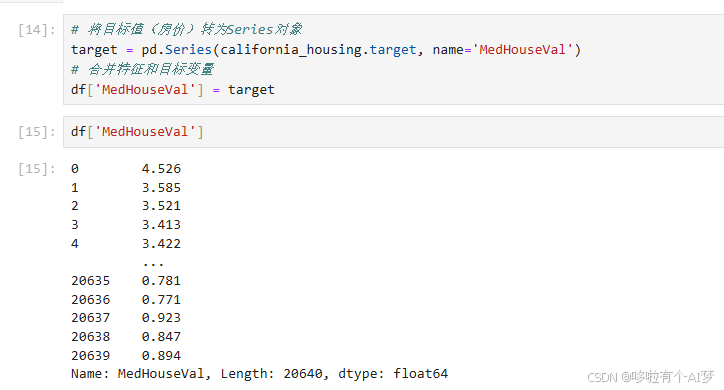
图片3
拆分数据集
80%用于训练,20%用于测试
X = df.drop(columns='MedHouseVal') # 特征
y = df['MedHouseVal'] # 目标值
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
图片4
创建线性回归模型
model = LinearRegression()
图片5
在训练集上训练模型
model.fit(X_train, y_train)
图片6
在测试集上进行预测
y_pred = model.predict(X_test)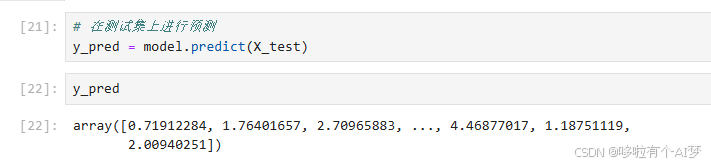
图片7
评估模型性能
mse = mean_squared_error(y_test, y_pred) # 计算均方误差
r2 = r2_score(y_test, y_pred) # 计算R²分数
print(f"均方误差 (MSE): {mse}")
print(f"R²分数: {r2}")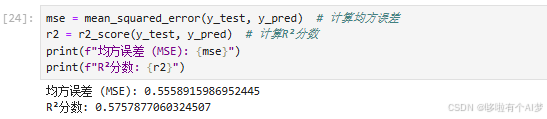
图片8
可视化实际房价与预测房价的对比
# 设置Seaborn的主题
sns.set(style="whitegrid") # 使用干净的网格背景
# 设置Matplotlib字体,解决中文显示问题(使用支持中文的字体)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 使用黑体字体(需要确保该字体在系统中可用)
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 可视化实际房价与预测房价的对比
plt.figure(figsize=(10, 6))
# 创建一个渐变色的散点图,使用`c`参数根据预测值设定颜色
scatter = plt.scatter(y_test, y_pred, c=y_pred, cmap='viridis', alpha=0.7, edgecolors='w', s=50, label='预测房价')
# 设置x轴标签
plt.xlabel('实际房价(中位数)')
# 设置y轴标签
plt.ylabel('预测房价(中位数)')
# 设置图表标题
plt.title('实际房价 vs 预测房价')
# 添加参考线,用于显示理想预测效果的对比
plt.plot([min(y_test), max(y_test)], [min(y_test), max(y_test)], color='red', lw=2, label='理想预测线')
# 显示图例
plt.legend()
# 显示网格
plt.grid(True)
# 添加颜色条以显示颜色映射
plt.colorbar(scatter, label='预测房价(颜色渐变)')
# 显示图表
plt.show()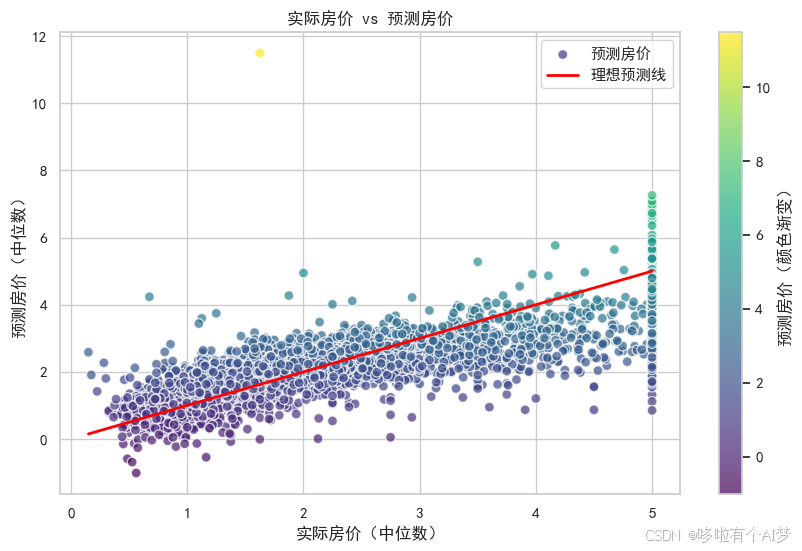
图片9

















 7万+
7万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









