







逻辑回归模型
这一章主要讲解机器学习中非常经典的逻辑回归模型,包括逻辑回归的算法原理,编程实现等。同时将介绍一个逻辑回归的经典案例:股票客户流失预警模型来巩固所学知识点,最后我们将讲解机器学习中对于分类模型常见的模型评估方法。
4.1 逻辑回归模型算法原理
在上一章我们学习了线性回归模型,线性回归模型是一个回归模型,回归模型是用来进行对连续变量进行预测,如预测收入范围、客户价值等。而逻辑回归模型虽然名字中有回归两字,其本质却是分类模型。分类模型与回归模型的区别在于其预测的变量不是连续的,而是离散的一些类别,以最常见的二分类模型为例,分类模型可以预测一个人是否会违约、客户是否会流失、肿瘤是属于良性肿瘤还是恶性肿瘤等。逻辑回归模型就是一个非常常用的分类模型。
4.1.1 逻辑回归模型的数学原理(了解)
那么既然逻辑回归模型是分类模型,为什么其名字里还含有回归两字呢?这是因为其算法原理中同样涉及了之前线性回归模型中学习到的线性回归方程:
y = k0 + k1*x1 + k2*x2 + k3*x3……
上面这个方程是预测连续变量的,其取值范围属为负无穷到正无穷,而逻辑回归模型是用来预测类别的,比如它预测某物品是属于A类还是B类,它本质预测的是属于A类或者B类的概率,而概率的取值范围是0-1,因此我们不能直接用线性回归方程来预测概率,那么如何把一个取值范围是(-∞, +∞)的回归方程变为取值范围是(0,1)的内容呢?
这就需要到用到下图所示的Sigmoid函数,该函数可以将取值为(-∞, +∞)的数转换到(0,1)之间,例如倘若y=3,那个通过Sigmoid函数转换后,f(y)就变成了1/(1+e^-3)=0.95了,这就可以作为一个概率值使用了。
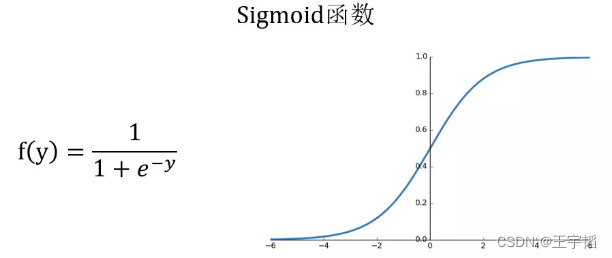
感兴趣的读者可以通过如下代码绘制Sigmoid函数:
import matplotlib.pyplot as plt
import numpy as np
x = np.linspace(-6, 6) # 通过linspace()函数生成-6到6的等差数列,默认50个数
y = 1.0 / (1.0 + np.exp(-x)) # Sigmoid函数计算公式,exp()函数表示指数函数
plt.plot(x,y)
plt.show()
如果对Sigmoid函数还是感到有点困惑,则可以参考下图的一个推导过程,其中y就是之前提到的线性回归方程,其范围是(-∞, +∞),那么指数函数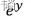 的范围便是(0, +∞),再做一次变换,
的范围便是(0, +∞),再做一次变换,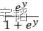 的范围就变成(0, 1)了,然后分子分母同除以
的范围就变成(0, 1)了,然后分子分母同除以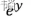 就获得了我们上面提到的Sigmoid函数了。
就获得了我们上面提到的Sigmoid函数了。
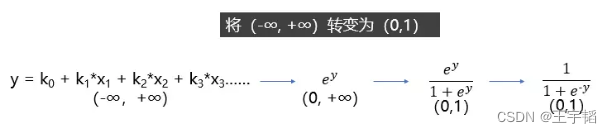
总结来说,逻辑回归模型本质就是将线性回归模型通过Sigmoid()函数进行了一个非线性转换得到一个介于0到1之间的概率值,对于二分类问题(分类0和1)而言,其预测分类为1(或者说二分类中数值较大的分类)的概率如下图所示:
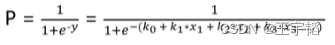
因为概率和为1,则分类为0(或说二分类中数值较小的那个分类)的概率为1-P。
**逻辑回归模型的本质就是预测属于各个分类的概率,有了概率之后,就可以进行分类了。**对于二分类问题来说,比如在预测客户是否会违约的违约预测模型中,如果预测违约的概率P为70%,不违约的概率为30%,违约概率大于不违约概率,那么就可以认为该客户会违约。对于多分类问题来说,逻辑回归模型会预测属于各个分类的概率(各个概率之和为1),然后根据哪个概率最大,判定属于哪个分类。
了解了逻辑回归模型的基本原理后,在实际模型搭建中,就是要找到合适的系数ki和截距项k0使得预测的概率较为准确,在数学中是使用极大似然估计法来确定合适的系数ki和截距项k0,从而得到相应的概率,在Python中则有相应的库将数学方法已经整合好了,我们通过调用相应的模块就能建立逻辑回归模型,从而预测概率进而进行分类,下面我们通过一个简单的案例来通过Python快速搭建逻辑回归模型加深大家对逻辑回归模型的理解。
4.1.2 逻辑回归模型的代码实现(重要)
这里通过一个简单的Python案例来说明逻辑回归中算法原理,数据如下,其中特征变量X中有两个特征变量X1和X2,Y是目标变量,Y的取值为0或1,代表两个不同的分类。以客户违约预测模型为例,大家可以把特征变量X1当作收入,X2当作历史违约次数,目标变量Y当作是否违约,其中0表示不违约,1表示违约。
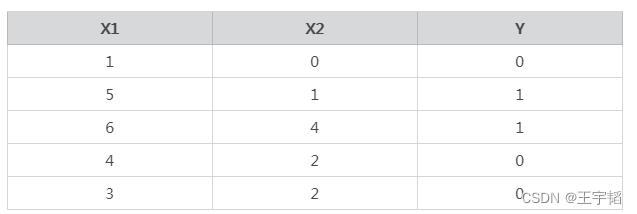
构造数据代码如下:
X = [[1, 0], [5, 1], [6, 4], [4, 2], [3, 2]]
y = [0, 1, 1, 0, 0]
将已有的数据使用逻辑回归模型进行拟合:
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
model.fit(X, y)
第一行代码从Scikit-Learn库中引入逻辑回归模型:LogisticRegression。
第二行代码将逻辑回归模型赋值给model变量,这里没有设置参数,也即使用默认参数。
第三行代码则是通过fit()函数来进行模型的训练。
训练完模型之后,我们就可以用模型的predict()函数来进行预测分类了,代码如下:
model.predict([[2, 2]]) # 通过predict()函数进行预测
预测结果如下:
[0]
有的读者可能会奇怪为什么上面predict()函数中要写两组中括号,为什么不可以直接写成model.predict([2, 2])呢?这是因为predict()函数默认接受一个多维数据,这个概念在同时预测多个数据时候大家就能更加明白了,同时预测多个数据的代码如下:
model.predict([[1, 0], [5, 1], [6, 4], [4, 2], [3, 2]])
因为这里演示的多个数据和X是一样的,所以也可以直接写成model.predict(X),通过print()函数将其打印输出,结果如下:
[0 1 1 0 0]
可以看到其预测准确度为100%。
这里多提一句,有时使用默认参数运行时,程序运行后会出现下图所示的FutureWarning警告,这个不用在意,它只是在告诉你以后模型的官方默认参数会有所调整而已,并不是报错。

通常我们会忽视这个警告信息,如果不想看到这个警告信息,可以在代码的最上面加上如下代码忽略警告信息:
import warnings
warnings.filterwarnings('ignore')
4.1.3 逻辑回归模型的深入理解
逻辑回归模型的本质其实是预测概率,而不是直接预测是属于0或1具体的类别,那么通过如下代码就可以获取概率值:
y_pred_proba = model.predict_proba(X)
可以直接将y_pred_proba打印出来,它是一个numpy格式的二维数组,也可以根据2.2.1节数组构造DataFrame的知识点,通过引入pandas库将其通过DataFrame的形式打印出来:
import pandas as pd
a = pd.DataFrame(y_pred_proba, columns=['分类为0的概率', '分类为1的概率'])
将其打印,结果如下,左列是分类为0的概率,右列是分类为1的概率(这里为了数据美观仅保留2位小数)。可以看到其中1、4、5行预测分类为0的概率大于预测为分类1的概率,因此它们被预测为0;第2和3行预测分类为1的概率大于分类为0的概率,所以它们将被预测为分类1,这个也的确和实际相符。
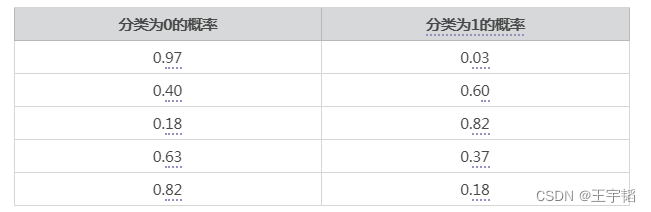
在本案例中,因为每个数据是有两个特征变量,所以逻辑回归计算概率原理的本质就是下图所示的计算公式,注意在二分类模型(0和1两个分类)中,下面这个概率P值默认预测分类为1的概率。
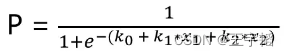
机器学习模型所需要确定就是其中的截距项k0和系数k1和k2,使得预测的概率尽可能准确,通过如下代码便可以获取机器计算出来的截距项k0和系数k1和k2,其中model为之前训练的模型名称,通过coef_属性可以获得特征变量前的系数ki,intercept_属性可以获得截距项k0。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 303
303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









