






作者Toby,来源公众号:Python风控模型,基于机器学习的多头借贷预测模型
引言
在中国的金融行业中,多头借贷是一个备受关注的话题。多头借贷是指一个借款人同时从多个金融机构借款,这种行为可能会增加借款人的还款压力,也会增加金融机构的风险。因此,对多头借贷的风险进行有效的监控和分析对于金融机构和监管部门来说至关重要。本文将对中国金融风控多头借贷数据进行分析,探讨多头借贷的特点、影响因素以及风险控制策略。
定义
多头借贷(Multiplatform Loan/multiple borrowing/multiple loaning),是指借款人在两家或两家以上申请借款的行为。通常,多头借贷客户大多是因为出现资金困难,失去还款能力,被迫只能依赖于“以贷养贷”维持,即多头负债。诈骗黑中介也有多头借贷情况,向多家平台骗取贷款。
特点
多头借贷的特点:多头借贷在中国金融市场中具有一定的普遍性。借款人可能因为资金需求较大或者信用状况不佳而选择从多个金融机构借款。多头借贷的特点包括借款人信用风险叠加、还款压力增大、信息不对称等。此外,多头借贷也给金融机构带来了风险,可能导致资金散失、不良资产增加等问题。
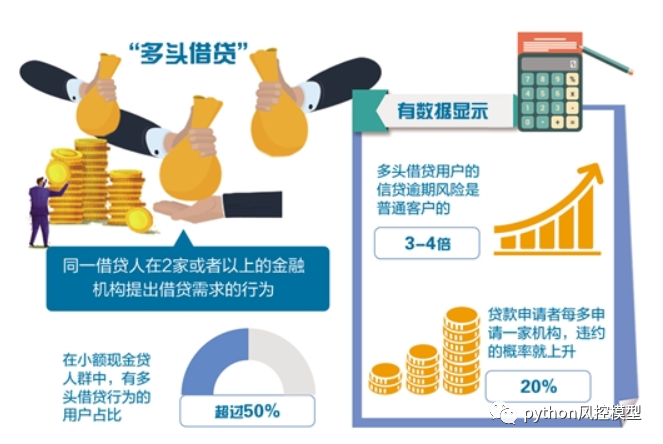
作为风控部高管,特别是CRO要特别关注多头借贷指标,如下图显示多头借贷用户信贷逾期风险是普通用户的3-4倍。
风险
多头借贷盛行下,根据中国国家统计局的数据,中国居民负债率在过去十年中呈现出增长的趋势。以下是中国近十年的居民负债率数据(单位:%):
2011年:33.3%
2012年:35.7%
2013年:38.7%
2014年:41.8%
2015年:45.7%
2016年:49.7%
2017年:53.2%
2018年:56.2%
2019年:59.8%
2020年:63.4%
2021年:62.2%
2022年:61.9%
2025(第一季度):61.1%
(央行统计数据会更高,统计接口有差异,上述数据与真实数据可能存在偏差,仅供参考)
这些数据表明,中国居民负债率在过去十年中持续上升,这可能反映了居民借贷行为的增加,以及金融市场的发展和消费升级的趋势。这也意味着需要更加关注居民的债务风险和金融风险管理。
风险控制策略和多头借贷模型
基于多头借贷数据分析的结果,金融机构可以制定有效的风险控制策略和多头借贷预测模型。一方面,可以加强对借款人的信用审查和评估,建立完善的风险管理体系。另一方面,可以通过数据分析和监控,及时发现多头借贷行为,并采取相应的风险防范措施,如限制借款额度、提高借款利率等。此外,监管部门也可以依托多头借贷数据分析,加强对金融机构的监管和风险防范。
我方重庆未来之智有限公司有银行个人信贷近1一个月,4个月,半年,一年多头借贷数据集,包括几十个用户变量,覆盖用户各种贷款的维度,可用于政府调研,企业建模,论文期刊科研实证分析。
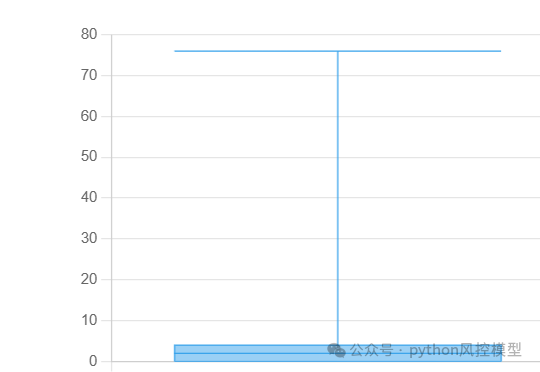
基于数万真实银行样本数据分析,用户一年内贷款审批查询次数平均数为3,中位数为2。查询次数为2的占比为12%左右,查询次数为3的占比为8%左右,查询次数为 4 的占比为 6%左右,查询次数为 7-20 的占比为 15%左右,查询次数为 21 - 80 的占比为 1%左右。如果设定一年内多于7次为多头,那么多头借贷占比为16%左右。
下图为一年内贷款审批查询次数的箱型图。图中可见整体数据的平均数和中位数较低,但异常值较高。
多头借贷模型预测模型是一个复杂的任务,它涉及到对借贷者财务状况、基本信息,还款行为等多方面因素的综合分析。机器学习预测模型可以通过分析历史数据来识别
金融个人信贷多头的潜在风险。以下是构建机器学习多头预测模型的一般步骤:
-
数据收集:收集个人借贷者的基本信息、信用分、行业信息等。
-
特征选择:从收集的数据中选择与个人借贷者相关的特征。
-
数据预处理:对数据进行清洗,处理缺失值和异常值,进行归一化或标准化。
-
数据标注:确定目标变量,即企业是否逾期。通常,这需要根据一定的时间窗口来判断企业是否在观察期内逾期。
-
数据分割:将数据集分割为训练集和测试集,用于模型训练和评估。
-
模型选择:选择合适的机器学习算法。
-
模型训练:使用训练集数据训练选定的机器学习模型。
-
模型评估:使用测试集数据评估和验证模型的性能。
-
模型优化:根据评估结果调整模型参数,进行特征工程,或者尝试不同的算法来优化模型性能。
-
模型部署:将训练好的模型部署到生产环境中,用于实时或定期预测能企业逾期风险。
-
监控与维护:持续监控模型的表现,定期更新模型以适应市场变化。
在构建能企业逾期预测模型时,还需要注意以下几点:
-
数据质量:确保数据的准确性和完整性,因为低质量的数据会导致模型预测不准确。
-
特征工程:深入理解业务,选择和构建对预测
企业逾期有重要影响的特征。 -
模型解释性:在金融领域,模型的解释性很重要,需要能够解释模型的预测结果。
-
合规性:确保模型的构建和应用符合相关法律法规和行业标准。
模型性能
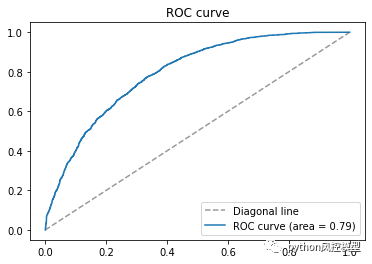
多头借贷模型AUC高于0.8,这只是初步实验结果,通过多算法比较,调参,变量筛选,模型性能还有提升空间。
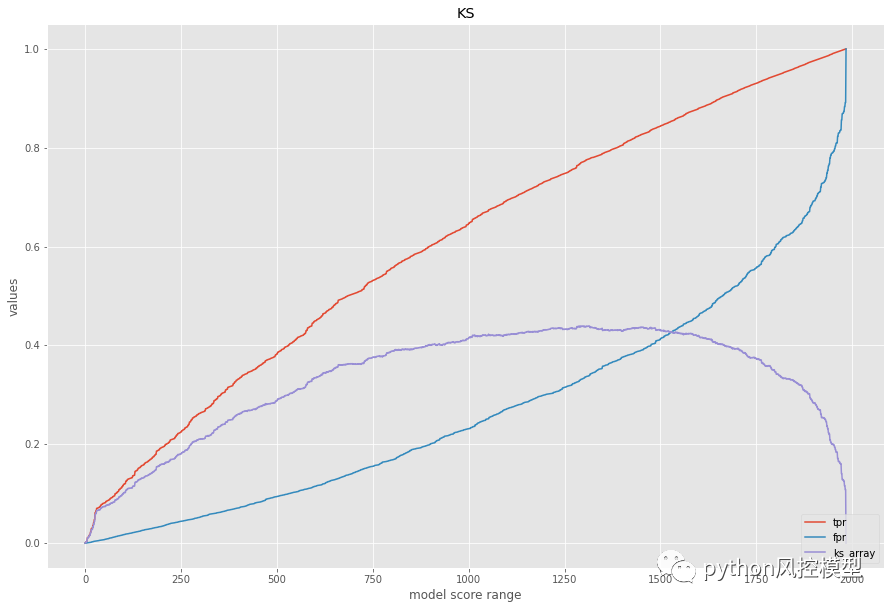
ks大于0.4,模型区分好坏客户能力良好。
数据案例可用于建立华丽模型,发布论文专利,政府企业科研立项
数据案例可用于建立华丽模型,发布论文专利。
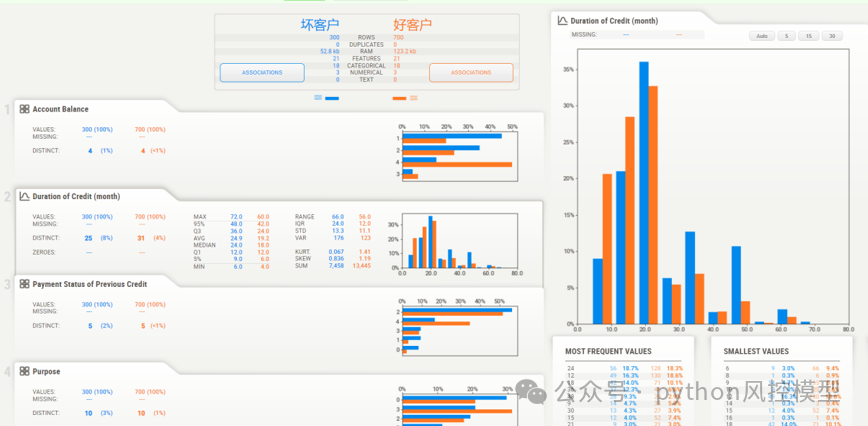
(模型自动化EDA统计图)
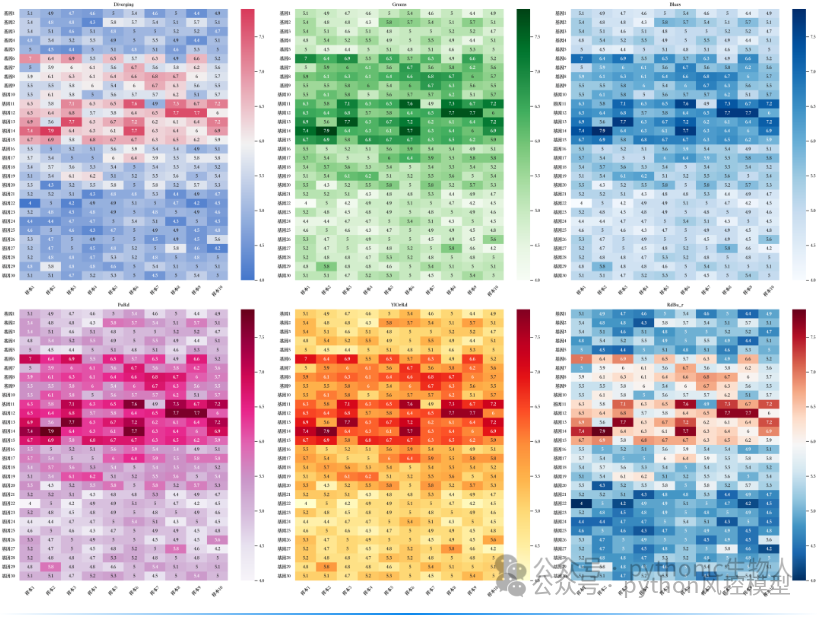
(热力图可视化)
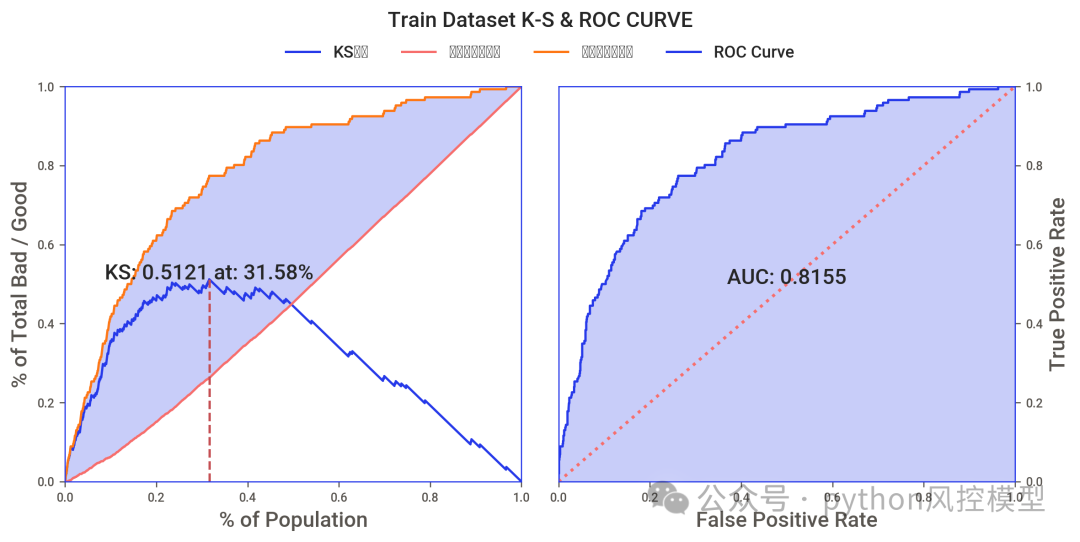
(KS和AUC,模型区分能力指标)
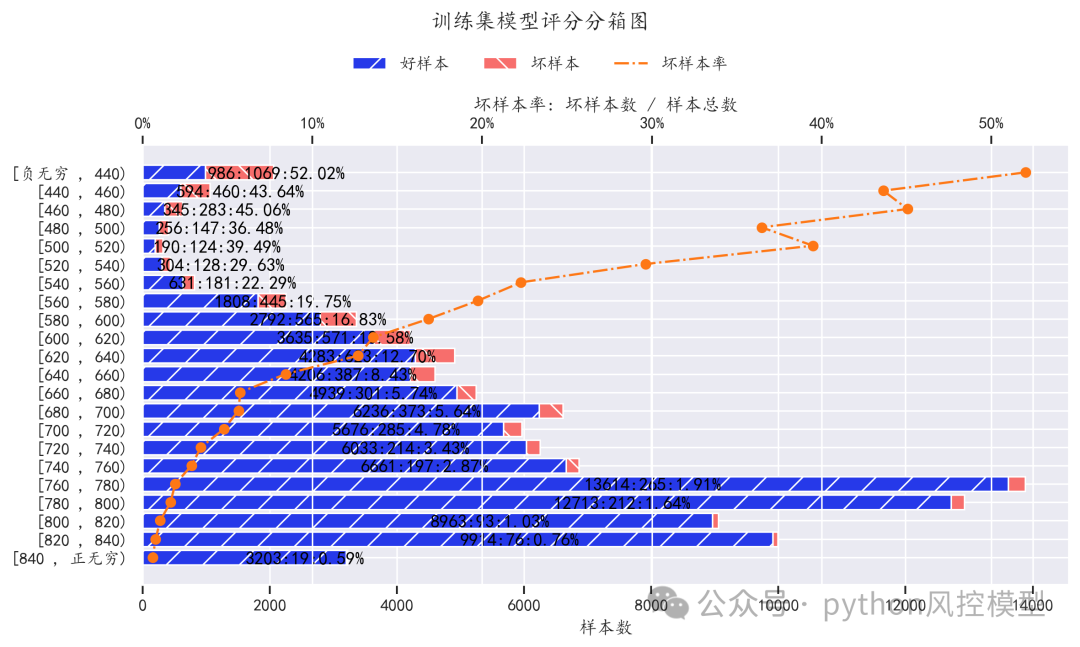
(评分分箱图)
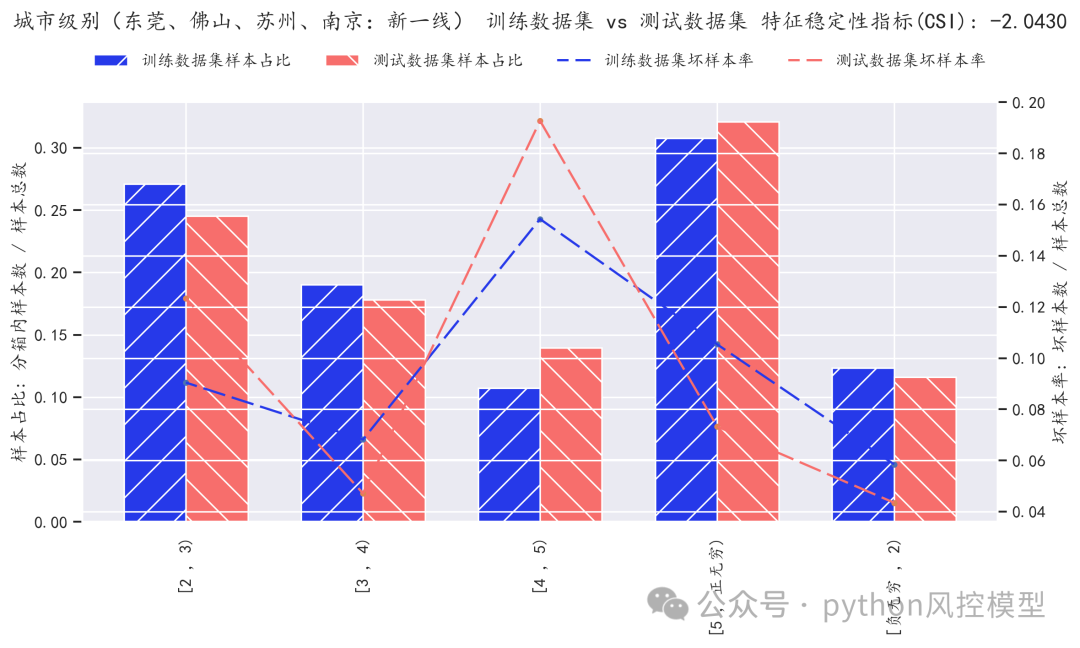
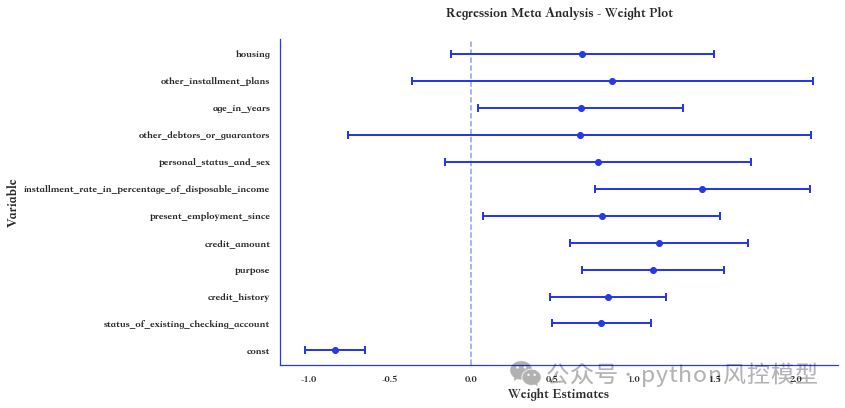
(变量系数稳定性)
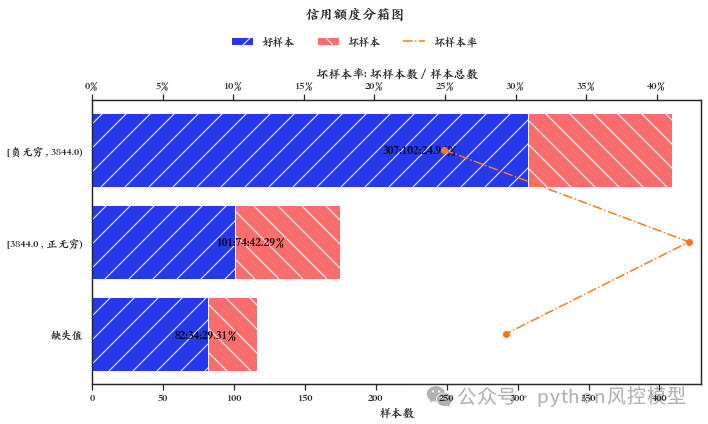
(信用额度分箱)
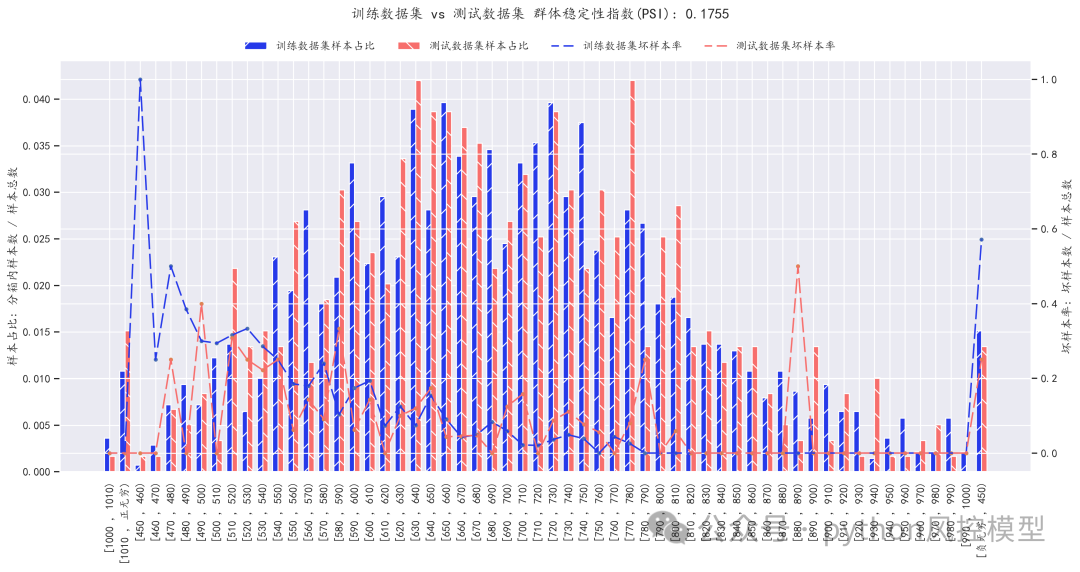
(PSI模型稳定性测评)
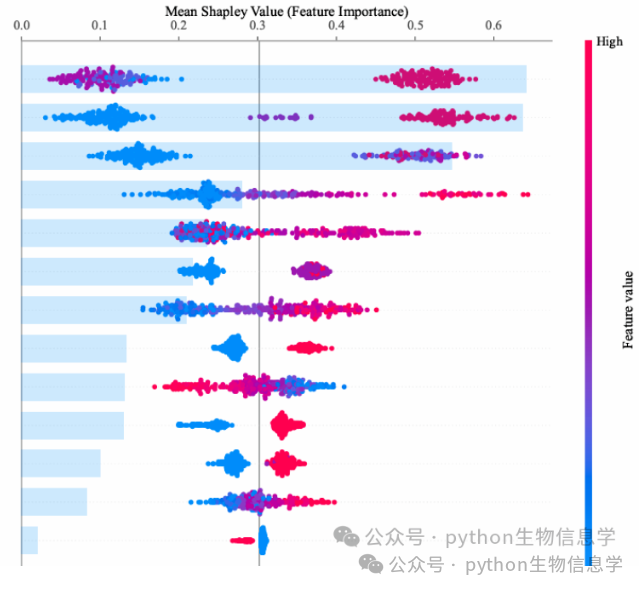
(变量重要性可视化)
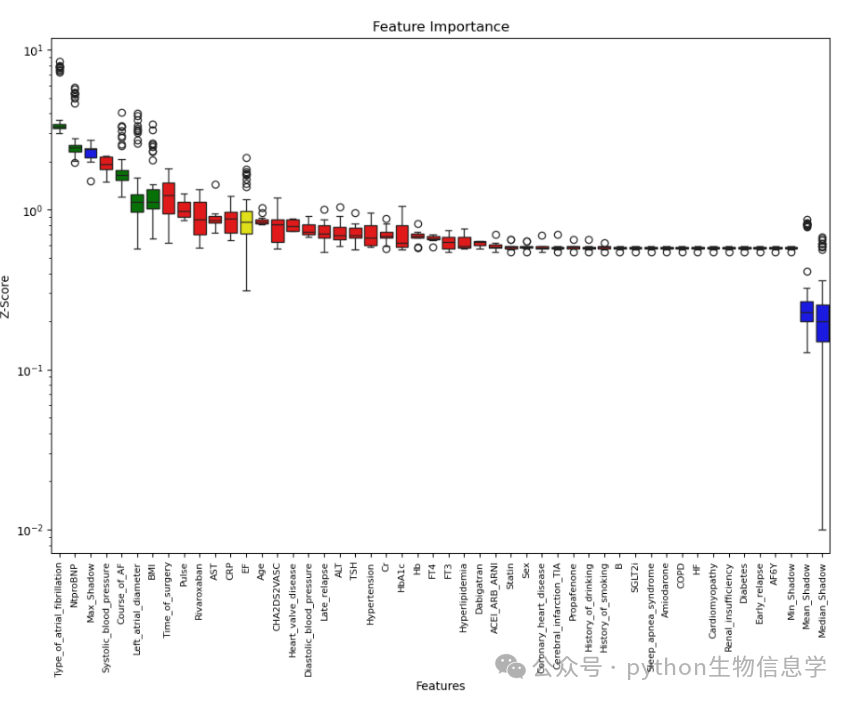
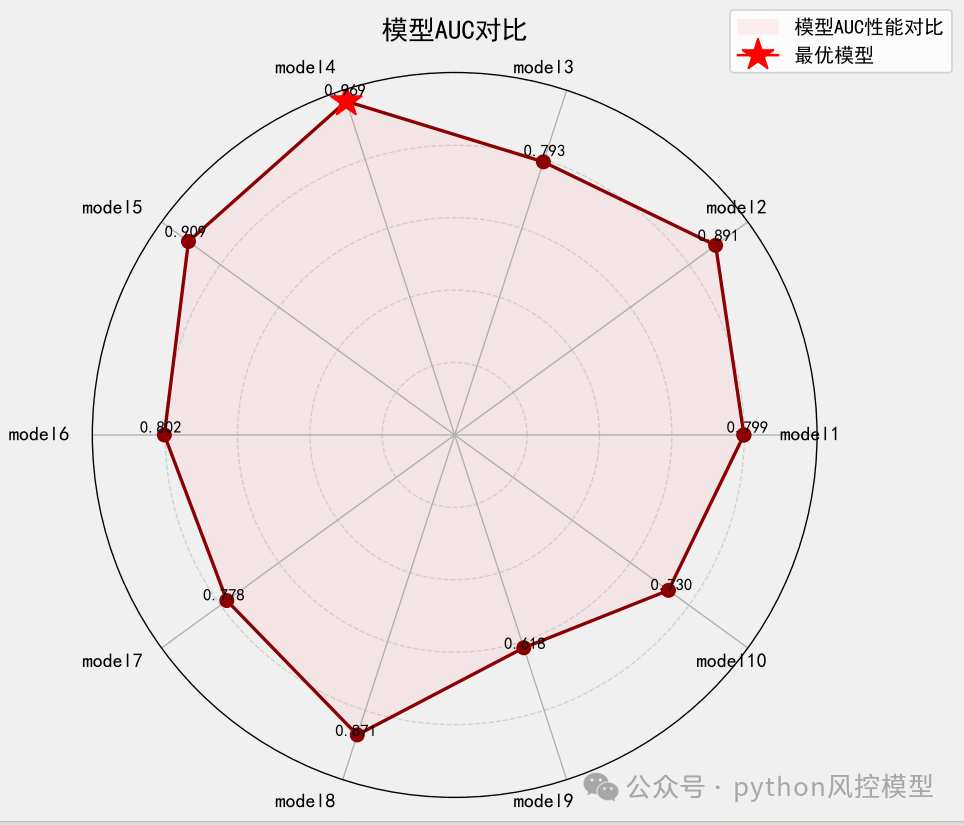
对各省多头借贷数量可视化统计

版权声明:文章来自公众号(python风控模型),未经许可,不得抄袭。遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。


















 707
707

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











