






作者Toby,来源公众号:Python风控模型,期刊复现-深度学习与企业债券信用风险
大家好,我是Toby老师,今天看到一篇高分期刊文章,分享给大家。
近年来,债券市场违约事件频发,尤其是部分高评级国企的“暴雷”事件,暴露出传统信用风险模型的局限性。在此背景下,融合深度学习技术构建更智能、更灵活的风险预测模型,成为学术界与业界关注的焦点。姜富伟、柴百霖、林奕皓于2024年在《计量经济学报》上发表的论文《深度学习与企业债券信用风险》,提出了一种基于生成对抗网络(GAN)的深度学习模型——CDL,用于企业债券信用风险的预测。本文将带你快速梳理该研究的核心方法、主要发现与复现价值。
文献解读
- Literature interpretation -

标题title:
深度学习与企业债券信用风险
Deep Learning and Corporate Bond Credit Risk
DOI:
10.12012/CJoE2024-0092
期刊:
计量经济学 China Journal of Econometrics
-
主管/主办单位: 中国科学院数学与系统科学研究院
-
出版周期: 季刊
-
语言: 中文(附有英文的标题、摘要和关键词)
-
创刊时间: 2021年 (一本充满活力的新刊)
-
ISSN: 2096-9765
-
CN: 10-1738/F
作为中国国内唯一的计量经济学专业期刊,它集中发表计量经济理论、方法及应用方面的最前沿研究成果。
-
重点关注包括机器学习、大数据分析、高频数据、因果推断、贝叶斯计量等现代计量经济学发展方向。
已被中国知网(CNKI)、万方数据、维普资讯等国内主要数据库收录。
期刊发表的文章范围覆盖计量经济学的全领域,主要包括:
-
理论计量经济学: 新的估计与检验方法、渐近理论、非参数与半参数方法、时间序列理论等。
-
应用计量经济学: 将计量方法应用于宏观经济、金融、产业、劳动、健康、环境等各经济领域的高质量实证研究。
发布时间:2024年11月
1
研究背景IBackground
自2014年“打破刚兑”以来,中国债券市场信用风险持续释放。据Wind数据,2018–2023年间有超过800只债券违约,年均违约金额超1200亿元。传统模型如Altman Z值、Merton模型等,因变量固定、假设严格,难以适应新形势下的风险识别需求。
与此同时,深度学习技术在图像、自然语言处理等领域大放异彩,也为金融风险预测提供了新思路。
2
研究方法IResearch Methods
作者运用深度学习模型,针对企业信贷数据,来预测他们可能出现的逾期概率。
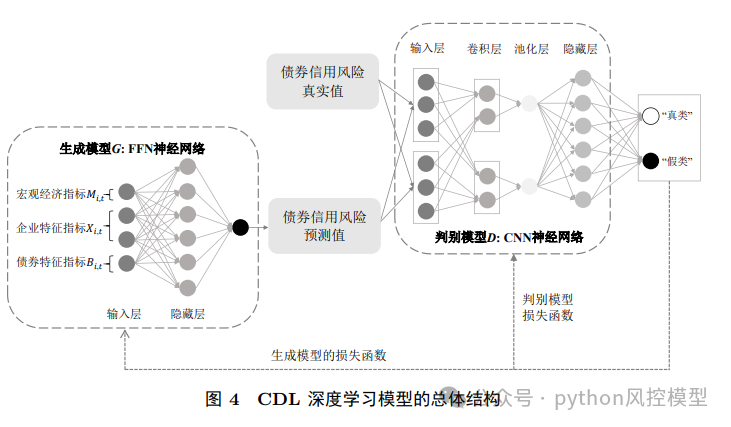
CDL模型借鉴了Goodfellow等人提出的GAN架构,包含两个核心网络:
-
生成模型(G):前馈神经网络,用于生成债券信用利差的预测值;
-
判别模型(D):卷积神经网络,用于判断预测值与真实值的差异。
两者通过对抗式训练不断优化,最终生成更接近真实值的预测结果。
3
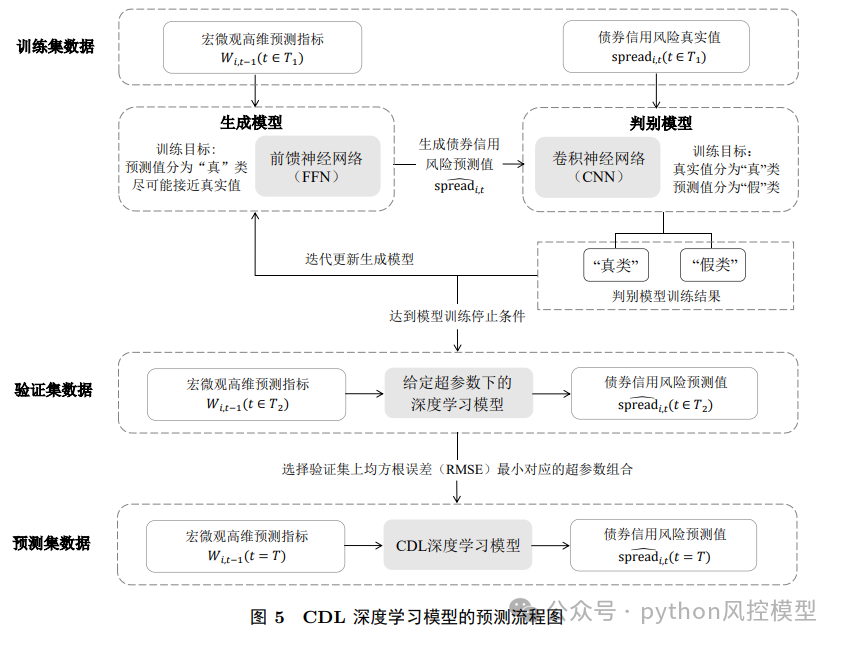
数据来源与处理Data source and process
-
数据期间:2008–2021年
-
样本范围:A股上市公司发行的企业债、公司债、中期票据、短期融资券
-
变量数量:1245个,涵盖宏观经济、企业特征、债券特征三大类
-
被预测变量:债券信用利差,作为信用风险的代理指标
债券信用利差,通常简称为信用利差,是衡量债券信用风险的核心指标。它指的是某一信用债券的到期收益率与无风险利率(通常为国债到期收益率)之间的差额。
这个利差可以被理解为市场投资者因为承担了发债主体可能违约的信用风险,而要求获得的额外补偿或风险溢价。
4
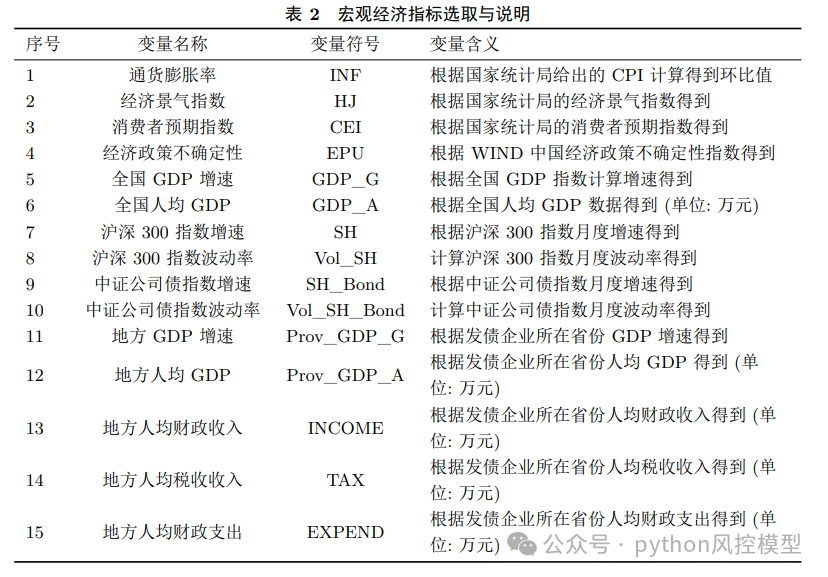
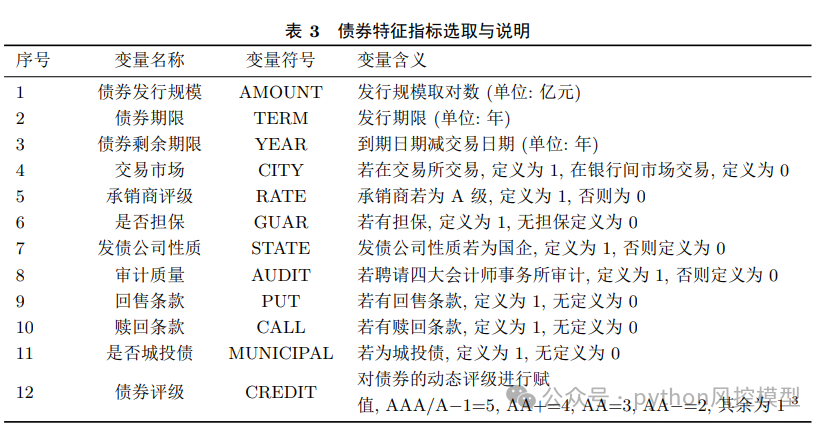
变量表list of variables
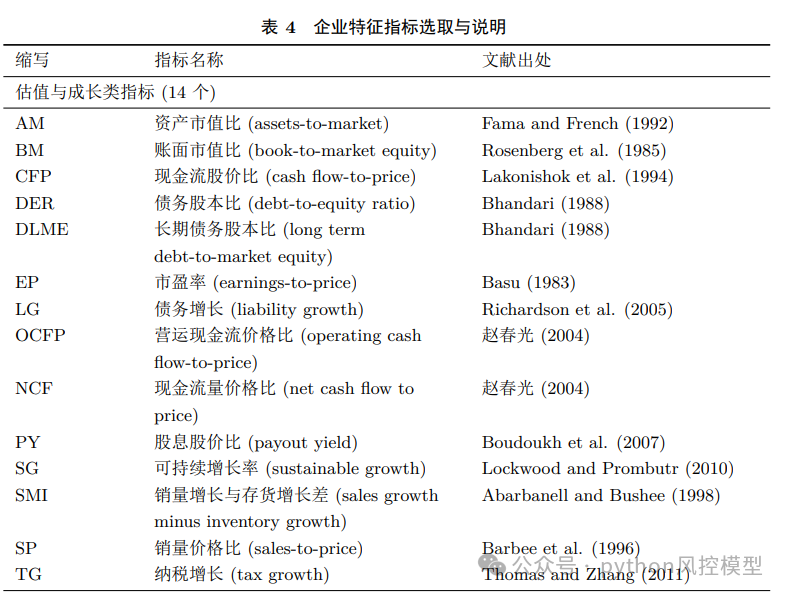
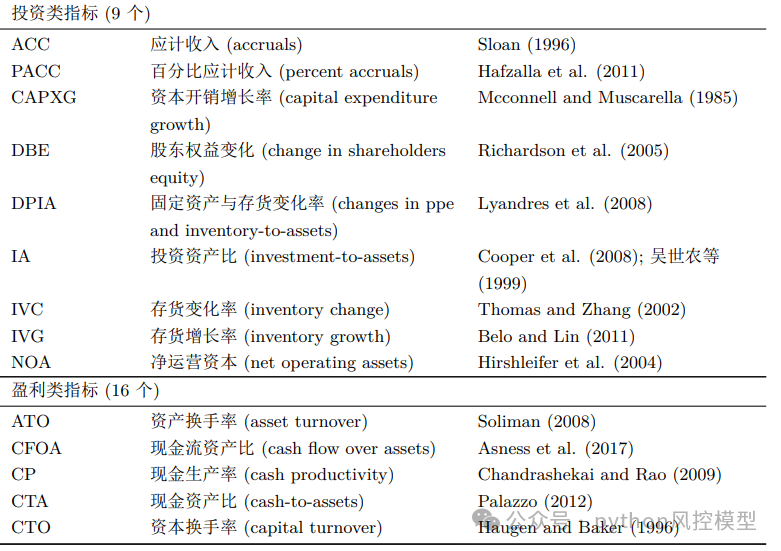
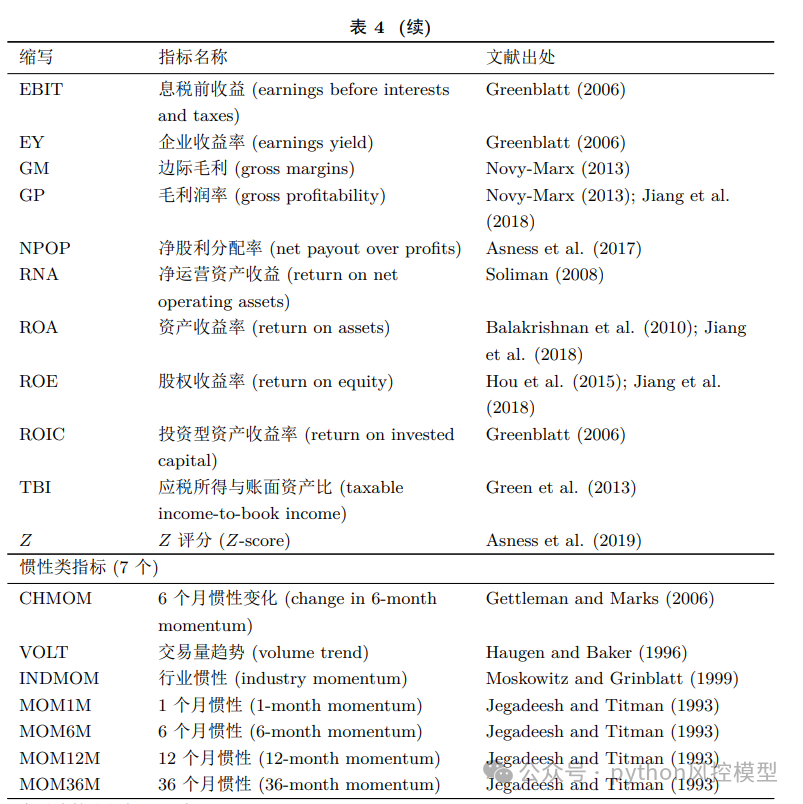
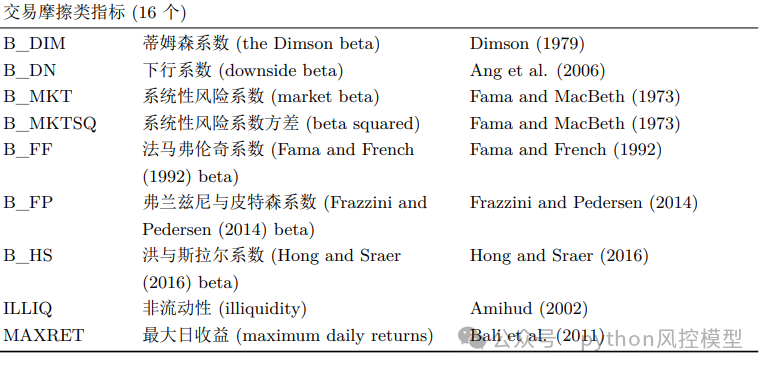
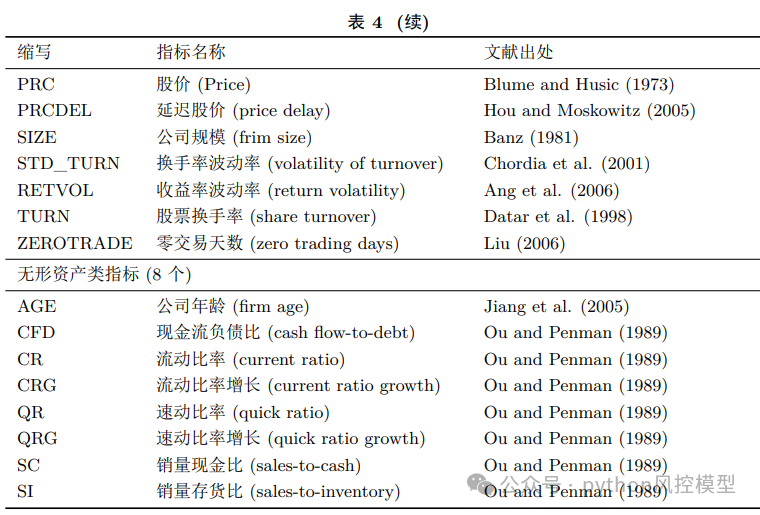
02
研究结果
- Findings: -
01
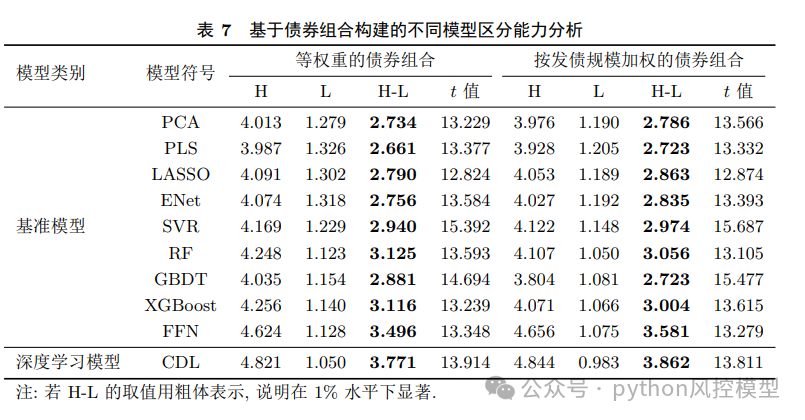
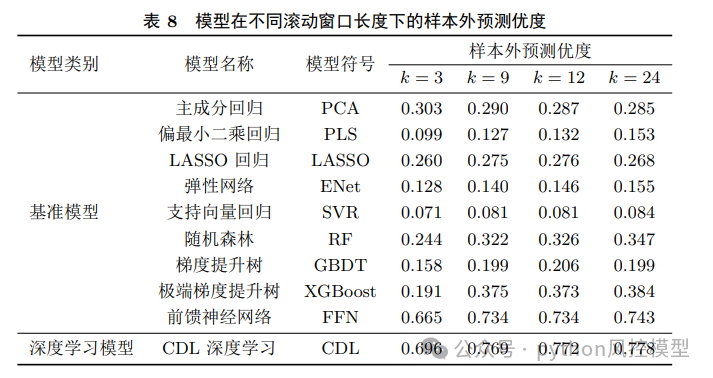
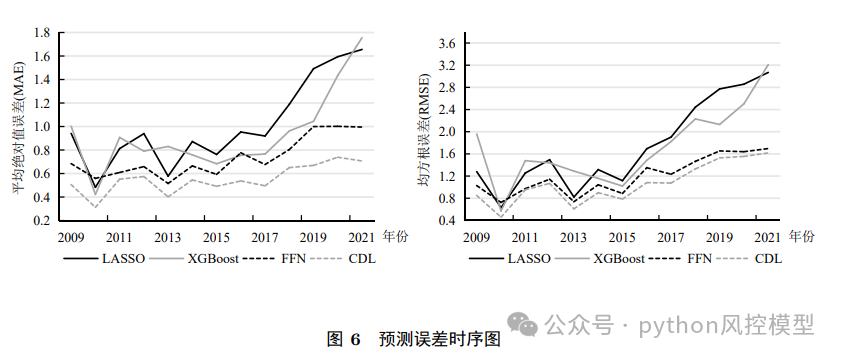
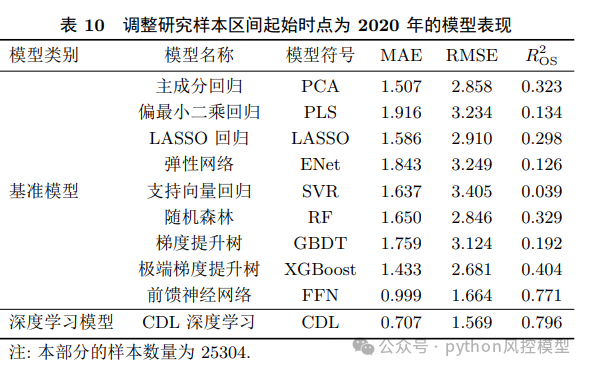
CDL模型预测能力显著优于基准模型
该模型属于回归模型,在MAE、RMSE、样本外预测优度等指标上,CDL模型均优于PCA、LASSO、XGBoost、FFN等9种经典模型。
02
对高风险债券识别能力更强
CDL模型在以下类型债券中表现尤为突出:
-
低评级债券
-
高票面利率债券
-
非国有企业发行债券
说明模型对高风险、非线性关系的捕捉能力更强。
03
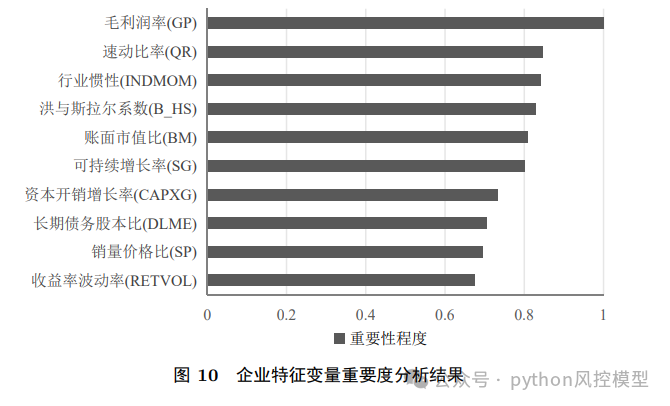
关键变量识别
-
最重要的宏观变量:地方人均财政支出
-
最重要的债券特征:债券评级
-
最重要的企业特征:毛利润率、速动比率、行业惯性等
04
经济机制解读
CDL模型能有效识别出:
-
交易量小的债券
-
融资约束高的企业
-
内部控制质量低的企业
这些特征与高违约风险显著相关。
03
文章点评
- Summary of the Paper-
CDL模型通过融合GAN架构与高维大数据,在企业债券信用风险预测中表现出显著优势,不仅预测精度高,还具备较强的可解释性与经济机制分析能力。
该研究为“人工智能+金融风控” 提供了重要方法论支持,也为后续研究提供了可复现、可拓展的深度学习框架。
重庆未来之智的Toby老师在论文定制有丰富经验,这里提出一些建议。整体来看文章工作量很大,比例涉及1200多个,前期数据筛选和处理花了不少时间。多算法比较用了10个模型,期刊作者非常踏实和勤恳,有较好机器学习建模基础。插图做的不错,整体很好,值得大家学习参考。文章中模型MAE只有0.7,说明模型误差很小。Toby老师建议作者还可以在模型业务可解释性上强化,文章质量会更上一个台阶。
版权声明:文章来自公众号(python风控模型),未经许可,不得抄袭。遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。


















 743
743

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











