







 本文介绍了如何使用Scrapy和PhantomJS来采集天猫商品内容。通过自定义DOWNLOADER_MIDDLEWARES,解决了动态网页采集问题。文章详细阐述了环境配置、代码编写和爬虫启动过程,最后提及了可能的优化方案,如scrapyjs和splash。
本文介绍了如何使用Scrapy和PhantomJS来采集天猫商品内容。通过自定义DOWNLOADER_MIDDLEWARES,解决了动态网页采集问题。文章详细阐述了环境配置、代码编写和爬虫启动过程,最后提及了可能的优化方案,如scrapyjs和splash。

1,引言
最近一直在看Scrapy 爬虫框架,并尝试使用Scrapy框架写一个可以实现网页信息采集的简单的小程序。尝试过程中遇到了很多小问题,希望大家多多指教。
本文主要介绍如何使用Scrapy结合PhantomJS采集天猫商品内容,文中自定义了一个DOWNLOADER_MIDDLEWARES,用来采集需要加载js的动态网页内容。看了很多介绍DOWNLOADER_MIDDLEWARES资料,总结来说就是使用简单,但会阻塞框架,所以性能方面不佳。一些资料中提到了自定义DOWNLOADER_HANDLER或使用scrapyjs可以解决阻塞框架的问题,有兴趣的小伙伴可以去研究一下,这里就不多说了。
2,具体实现
2.1,环境需求
需要执行以下步骤,准备Python开发和运行环境:
- Python–官网下载安装并部署好环境变量 (本文使用Python版本为3.5.1)
- lxml– 官网库下载对应版本的.whl文件,然后命令行界面执行 “pip install .whl文件路径”
- Scrapy–命令行界面执行 “pip install Scrapy”,详细请参考《Scrapy的第一次运行测试》
- selenium–命令行界面执行 “pip install selenium”
- PhantomJS – 官网下载
上述步骤展示了两种安装:1,安装下载到本地的wheel包;2,用Python安装管理器执行远程下载和安装。注:包的版本需要和python版本配套
2.2,开发和测试过程
首先找到需要采集的网页,这里简单找了一个天猫商品,网址https://world.tmall.com/item/526449276263.htm, 页面如下:
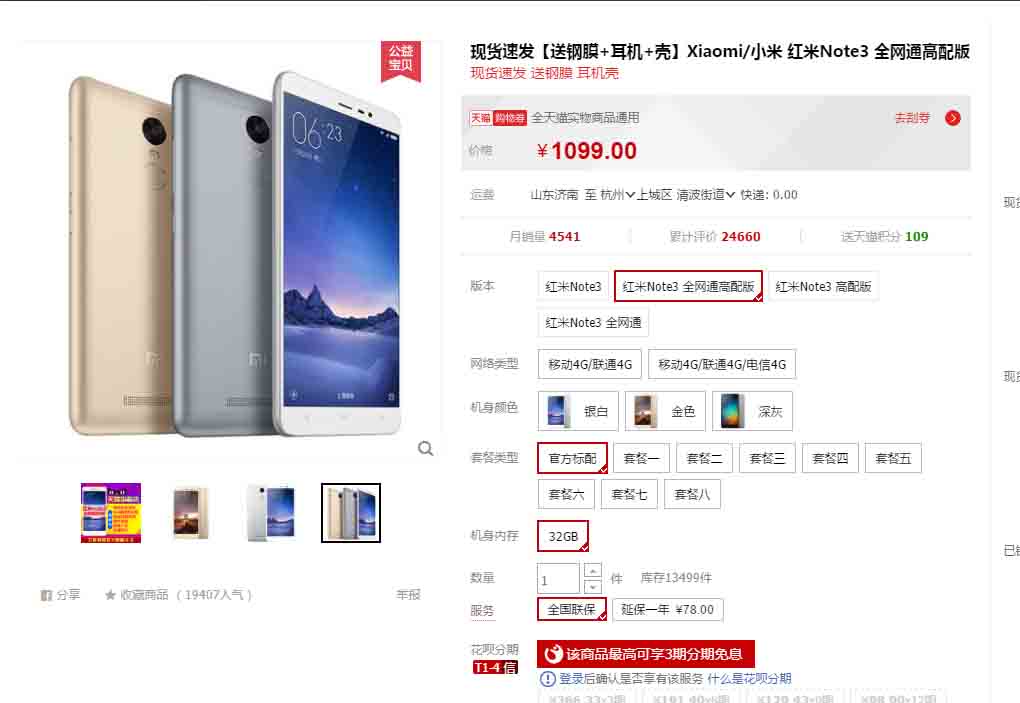
然后开始编写代码,以下代码默认都是在命令行界面执行
1),创建scrapy爬虫项目tmSpider
E:\python-3.5.1>scrapy startproject tmSpider2),修改settings.py配置
- 更改ROBOTSTXT_OBEY的值为False;
- 关闭scrapy默认的下载器中间件;
- 加入自定义DOWNLOADER_MIDDLEWARES。
配置如下:
DOWNLOADER_MIDDLEWARES = {
'tmSpider.middlewares.middleware.CustomMiddlewares': 543,
'scrapy.contrib.downloadermiddleware.useragent.UserAgentMiddleware':  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6046
6046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









