








1. 引言
前面文章的测试案例都用到了集搜客Gooseeker提供的规则提取器,在网页抓取工作中,调试正则表达式或者XPath都是特别繁琐的,耗时耗力,工作枯燥,如果有一个工具可以快速生成规则,而且可以可视化的即时验证,就能把程序员解放出来,投入到创造性工作中。
之前文章所用的例子中的规则都是固定的,如何自定义规则再结合提取器提取我们想要的网页内容呢?对于程序员来说,理想的目标是掌握一个通用的爬虫框架,每增加一个新目标网站就要跟着改代码,这显然不是好工作模式。这就是本篇文章的主要内容了,本文使用一个案例说明怎样将新定义的采集规则融入到爬虫框架中。也就是用可视化的集搜客GooSeeker爬虫软件针对亚马逊图书商品页做一个采集规则,并结合规则提取器抓取网页内容。
2. 安装集搜客GooSeeker爬虫软件
2.1. 前期准备
进入集搜客官网产品页面,下载对应版本。我的电脑上已经安装了Firefox 38,所以这里只需下载爬虫。
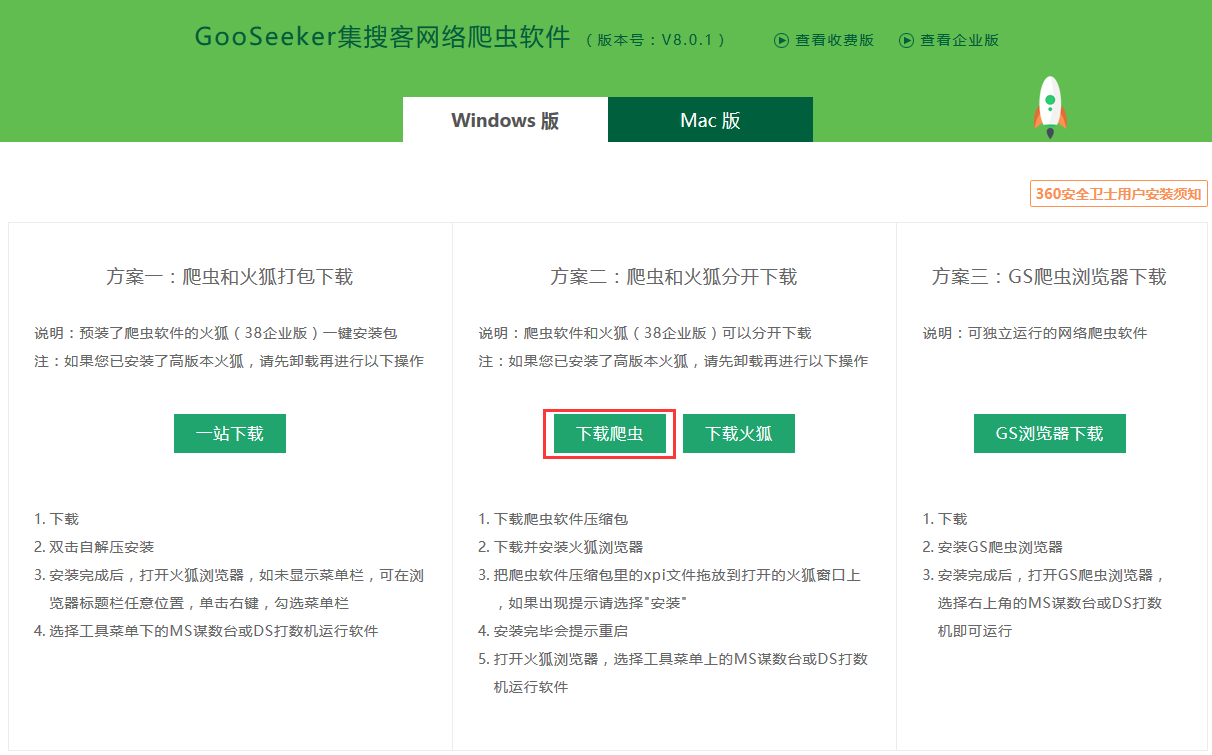
2.2 安装爬虫
打开Firefox –> 点击菜单工具 –> 附加组件 –> 点击右上角附加组件的工具 –> 选择从文件安装附加组件 -> 选中下载好的爬虫xpi文件 –> 立即安装
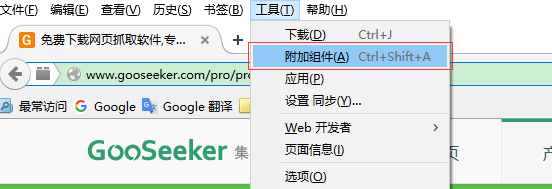
下一步
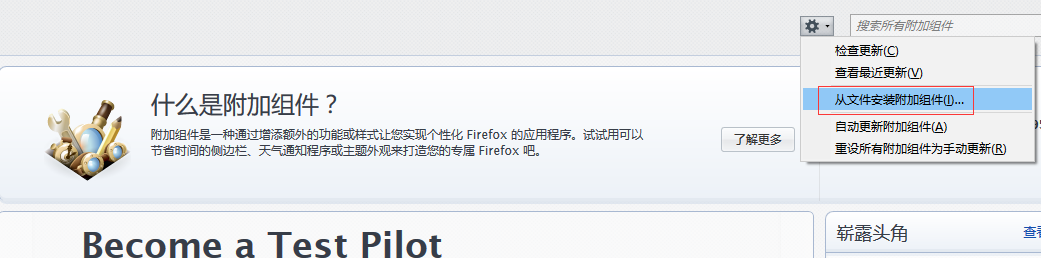
下一步
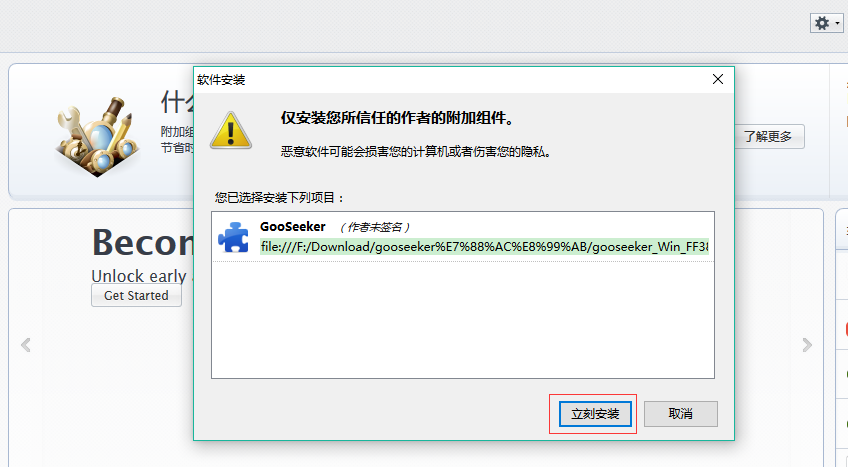
3. 开始制作抓取规则
3.1 运行规则定义软件
点击浏览器菜单:工具-> MS谋数台 弹出MS谋数台窗口。
3.2 做规则
在网址栏输入我们要采集的网站链接,然后回车。当页面加载完成后,在工作台页面依次操作:命名主题名 -> 创建规则 ->
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









