







Netty强大的地方,是他能方便的实现自定义协议的网络传输。在上一篇文章中,通过使用Netty封装好的工具类,实现了简单的http服务器。在接下来的文章中,我们看看怎么使用他来搭建自定义协议的服务器。要做到这点,第一步要做的,就是要自定义编码器和解码器,这就是我们这一章主要讲的内容。
什么是Decoder和Encoder
在学习Decoder和Encoder之前,首先要了解他们在具体是个什么东西。在Netty里面,有四个核心概念,这个在第一篇文章提到的,他们的分别是:
-
Channel,一个客户端与服务器通信的通道
-
ChannelHandler,业务逻辑处理器,分为ChannelInboundHandler和ChannelOutboundHandler
- ChannelInboundHandler,输入数据处理器
- ChannelOutboundHandler,输出业务处理器
通常情况下,业务逻辑都是存在于ChannelHandler之中
-
ChannelPipeline,用于存放ChannelHandler的容器
-
ChannelContext,通信管道的上下文
他们之间的交流流程如下图:
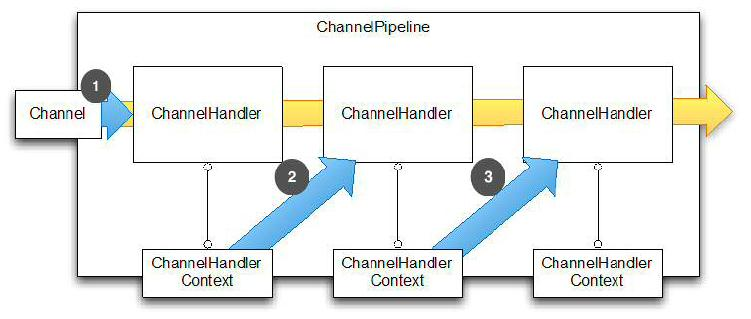
他们的交互流程是:
- 事件传递给 ChannelPipeline 的第一个 ChannelHandler
- ChannelHandler 通过关联的 ChannelHandlerContext 传递事件给 ChannelPipeline 中的 下一个
- ChannelHandler 通过关联的 ChannelHandlerContext 传递事件给 ChannelPipeline 中的 下一个
而我们本文所需要详细讲的Decoder和Encoder,他们分别就是ChannelInboundHandler和ChannelOutboundHandler,分别用于在数据流进来的时候将字节码转换为消息对象和数据流出去的时候将消息对象转换为字节码。
Encoder
Encoder最重要的实现类是MessageToByteEncoder<T>,这个类的作用就是将消息实体T从对象转换成byte,写入到ByteBuf,然后再丢给剩下的ChannelOutboundHandler传给客户端,流程图如下:

encode方法是继承MessageToByteEncoder唯一需要重写的方法,可见其简单程度。也是因为Encoder相比于Decoder更为简单,在这里也不多做赘述,直接上代码:
public class ShortToByteEncoder extends
MessageToByteEncoder<Short> { //1
@Override
public void encode(ChannelHandlerContext ctx, Short msg, ByteBuf out)
throws Exception {
out.writeShort(msg); //2
}
}Decoder
和Encoder一样,decoder就是在服务端收到数据的时候,将字节流转换为实体对象Message。但是和Encoder的处理逻辑不一样,数据传到服务端有可能不是一次请求就能完成的,中间可能需要经过几次数据传输,并且每一次传输传多少数据也是不确定的,所以它有两个重要方法:
第一个方法:decode
第二个方法:decodeLast
decode和decodeLast的不同之处,在于他们的调用时机不同,正如描述所说,decodeLast只有在Channel的生命周期结束之前会调用一次,默认是调用decode方法。
同样是ToInteger的解码器,他的代码如下:
public class ToIntegerDecoder extends ByteToMessageDecoder { //1
@Override
public void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out)
throws Exception {
if (in.readableBytes() >= 4) { //2
out.add(in.readInt()); //3
}
}
} 从这段代码可以看出,因为不知道这次请求发过来多少数据,所以每次都要判断byte长度够不够4,如果你的数据长度更长,且不固定的话,这里的逻辑会变得非常复杂。所以在这里介绍另一个我们常用的解码器 :ReplayingDecoder。
ReplayingDecoder
ReplayingDecoder 是 byte-to-message 解码的一种特殊的抽象基类,读取缓冲区的数据之前需要检查缓冲区是否有足够的字节,使用ReplayingDecoder就无需自己检查;若ByteBuf中有足够的字节,则会正常读取;若没有足够的字节则会停止解码。
RelayingDecoder在使用的时候需要搞清楚的两个方法是checkpoint(S s)和state(),其中checkpoint的参数S,代表的是ReplayingDecoder所处的状态,一般是枚举类型。RelayingDecoder是一个有状态的Handler,状态表示的是它目前读取到了哪一步,checkpoint(S s)是设置当前的状态,state()是获取当前的状态。
在这里我们模拟一个简单的Decoder,假设每个包包含length:int和content:String两个数据,其中length可以为0,代表一个空包,大于0的时候代表content的长度。代码如下:
public class LiveDecoder extends ReplayingDecoder<LiveDecoder.LiveState> { //1
public enum LiveState { //2
LENGTH,
CONTENT
}
private LiveMessage message = new LiveMessage();
public LiveDecoder() {
super(LiveState.LENGTH); // 3
}
@Override
protected void decode(ChannelHandlerContext channelHandlerContext, ByteBuf byteBuf, List<Object> list) throws Exception {
switch (state()) { // 4
case LENGTH:
int length = byteBuf.readInt();
if (length > 0) {
checkpoint(LiveState.CONTENT); // 5
} else {
list.add(message); // 6
}
break;
case CONTENT:
byte[] bytes = new byte[message.getLength()];
byteBuf.readBytes(bytes);
String content = new String(bytes);
message.setContent(content);
list.add(message);
break;
default:
throw new IllegalStateException("invalid state:" + state());
}
}
}- 继承ReplayingDecoder,泛型LiveState,用来表示当前读取的状态
- 描述LiveState,有读取长度和读取内容两个状态
- 初始化的时候设置为读取长度的状态
- 读取的时候通过state()方法来确定当前处于什么状态
- 如果读取出来的长度大于0,则设置为读取内容状态,下一次读取的时候则从这个位置开始
- 读取完成,往结果里面放解析好的数据
以上就是ReplayingDecoder的使用方法,他比ByteToMessageDecoder更加灵活,能够通过巧妙的方式来处理复杂的业务逻辑,但是也是因为这个原因,使得ReplayingDecoder带有一定的局限性:
-
不是所有的标准 ByteBuf 操作都被支持,如果调用一个不支持的操作会抛出 UnreplayableOperationException
-
ReplayingDecoder 略慢于 ByteToMessageDecoder
所以,如果不引入过多的复杂性 使用 ByteToMessageDecoder 。否则,使用ReplayingDecoder。
MessageToMessage
Encoder和Decoder除了能完成Byte和Message的相互转换之外,为了处理复杂的业务逻辑,还能帮助使用者完成Message和Message的相互转换,我们熟悉的Http协议的处理,其中就用到了很多MessageToMessage的派生类。
因为使用方法和以上的Decoder/Encoder类似,在这里就不多做赘述了。
转载:https://www.jianshu.com/p/fd815bd437cd















 1159
1159











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









