







1.问题引入
spark提供的API函数能满足大多数场景的应用,但是有时候也需要根据实际数据,自己开发API,以进一步提高性能,看下面一个小例子
val rdd=sc.parallelize(Array(1,2,3,4,5,6,Double.NaN,7,8,9),2)现在要对其进行统计分析,调用stats函数
rdd.stats
由于原始数据中有一个缺失值Double.NaN,使得统计结果失去意义,很自然的想到用filter过滤掉这个缺失值
import java.lang.Double.isNaN
rdd.filter(!isNaN(_)).stats()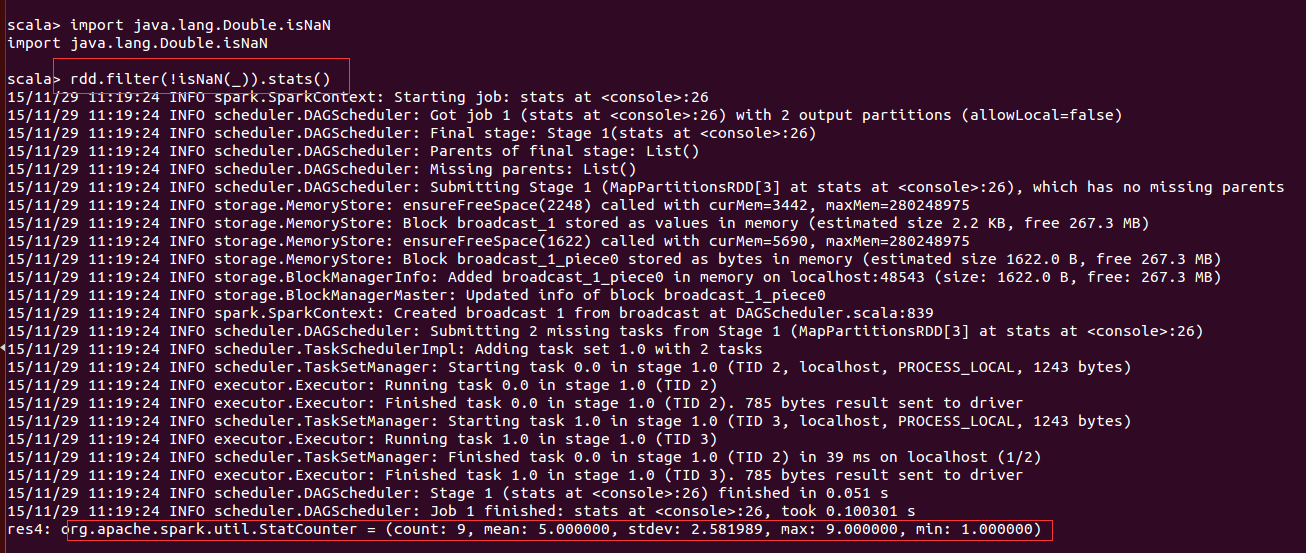
经过过滤后再进行统计分析,得到了合理的结果,但是这个方法是不是最优的呢?
2.改进
在上述过滤掉NaN的过程中,需对整个数组遍历一次,第二步统计分析中又要遍历一次,太浪费时间了,那能不能将两次遍历合并为一次呢,查看stats的源码,发现是可以做到的.
stats的源码在org.apache.spark.util.StatCounter.scala中,部分代码如下
class StatCounter(values: TraversableOnce[Double]) extends Serializable {
private var n: Long = 0 // Running count of our values
private var mu: Double = 0 // Running mean of our values
private var m2: Double = 0 // Running variance numerator (sum of (x - mean)^2)
private var maxValue: Double = Double.NegativeInfinity // Running max of our values
private var minValue: Double = Double.PositiveInfinity // Running min of our values
merge(values)
/** Initialize the StatCounter with no values. */
def this() = this(Nil)
/** Add a value into this StatCounter, updating the internal statistics. */
def merge(value: Double): StatCounter = {
val delta = value - mu
n += 1
mu += delta / n
m2 += delta * (value - mu)
maxValue = math.max(maxValue, value)
minValue = math.min(minValue, value)
this
}
/** Add multiple values into this StatCounter, updating the internal statistics. */
def merge(values: TraversableOnce[Double]): StatCounter = {
values.foreach(v => merge(v))
this
}
/** Merge another StatCounter into this one, adding up the internal statistics. */
def merge(other: StatCounter): StatCounter = {
if (other == this) {
merge(other.copy()) // Avoid overwriting fields in a weird order
} else {
if (n == 0) {
mu = other.mu
m2 = other.m2
n = other.n
maxValue = other.maxValue
minValue = other.minValue
} else if (other.n != 0) {
val delta = other.mu - mu
if (other.n * 10 < n) {
mu = mu + (delta * other.n) / (n + other.n)
} else if (n * 10 < other.n) {
mu = other.mu - (delta * n) / (n + other.n)
} else {
mu = (mu * n + other.mu * other.n) / (n + other.n)
}
m2 += other.m2 + (delta * delta * n * other.n) / (n + other.n)
n += other.n
maxValue = math.max(maxValue, other.maxValue)
minValue = math.min(minValue, other.minValue)
}
this
}
}stats共有元素计数(n)、均值(mu)、方差(mu2)、最大值(maxValue)、最小值(minValue) 五个属性,都是通过merge这个函数实现的
def merge(value: Double): StatCounter = {
val delta = value - mu
n += 1
mu += delta / n
m2 += delta * (value - mu)
maxValue = math.max(maxValue, value)
minValue = math.min(minValue, value)
this
}merge是个增量函数,即它统计数组中的所有元素的时候,并不是按通常的mean=sum(x)/count(x),而是采取的每接收一个元素,就更新一次均值、方差这些属性,这位后续开发提供了方便,如果要剔除NaN,则只需修改merge函数即可
import org.apache.spark.util.StatCounter
class NAStatCounter extends Serializable {
val stats: StatCounter = new StatCounter()
var missing: Long = 0
def add(x: Double): NAStatCounter = {
if (java.lang.Double.isNaN(x)) {
missing += 1
} else{
stats.merge(x)
}
this
}
def merge(other: NAStatCounter): NAStatCounter = {
stats.merge(other.stats)
missing += other.missing
this
}
override def toString = {
"stats: " + stats.toString + " NaN: " + missing
}
}
object NAStatCounter extends Serializable {
def apply(x: Double) = new NAStatCounter().add(x)
}修改的代码中添加了一个missing属性,用来统计缺失值的个数。
3.在spark-shell中引用修改的源码
在shell下新建一个 StatsWithMissing.scala文件,将上述代码添加进去,保存并关闭,然后在spark-shell中用 :load引用

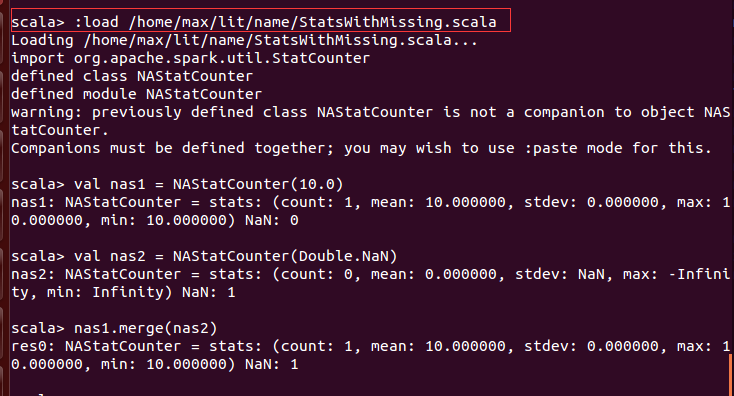
测试结果表明引用成功。
4.提供RDD的接口
将下面的代码添加到StatsWithMissing.scala文件中,使得任意的RDD[Array[Double]] 可以调用该函数进行统计分析
import org.apache.spark.rdd.RDD
def statsWithMissing(rdd: RDD[Array[Double]]): Array[NAStatCounter] = {
val nastats = rdd.mapPartitions((iter: Iterator[Array[Double]]) => {
val nas: Array[NAStatCounter] = iter.next().map(d => NAStatCounter(d))
iter.foreach(arr => {
nas.zip(arr).foreach { case (n, d) => n.add(d) }
})
Iterator(nas)
})
nastats.reduce((n1, n2) => {
n1.zip(n2).map { case (a, b) => a.merge(b) }
})
}注意:
1.上述代码中用到了mapPartitions这个高级API,使代码更加高效
2.在编写 NAStatCounter 类的时候继承了 Serializable 这个接口,使编写的函数可以在sparkAPI内部被调用,否则会出现不可序列化的错误
Reference
《spark高级数据分析》(2.10-2.11小节)















 1132
1132











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









