







1、为什么当桶中键值对数量大于8才转换成红黑树,数量小于6才转换成链表?
HashMap在JDK1.8及以后的版本中引入了红黑树结构,若桶中链表元素个数大于等于8时,链表转换成树结构;若桶中链表元素个数小于等于6时,树结构还原成链表。因为红黑树的平均查找长度是log(n),长度为8的时候,平均查找长度为3,如果继续使用链表,平均查找长度为8/2=4,这才有转换为树的必要。链表长度如果是小于等于6,6/2=3,虽然速度也很快的,但是转化为树结构和生成树的时间并不会太短。
还有选择6和8,中间有个差值7可以有效防止链表和树频繁转换。假设一下,如果设计成链表个数超过8则链表转换成树结构,链表个数小于8则树结构转换成链表,如果一个HashMap不停的插入、删除元素,链表个数在8左右徘徊,就会频繁的发生树转链表、链表转树,效率会很低。
参考:https://blog.csdn.net/xingfei_work/article/details/79637878
2、为什么hashmap的初始化容量大小要是2的n次幂
2.1、看看这个博主这么解释的
首先我们要了解一下hashcode是怎么比较的
我们知道,n代表的是table的长度length,之前一再强调,表table的长度需要取2的整数次幂,就是为了这里等价这里进行取模运算时的方便——取模运算转化成位运算公式:a%(2^n) 等价于 a&(2^n-1),而&操作比%操作具有更高的效率。
当length=2n时,(length - 1)正好相当于一个"低位掩码","与"操作的结果就是散列值的高位全部归零,只保留低位,用来做数组下标访问:

可以看到,当我们的length为16的时候,哈希码(字符串“abcabcabcabcabc”的key对应的哈希码)对(16-1)与操作,对于多个key生成的hashCode,只要哈希码的后4位为0,不论不论高位怎么变化,最终的结果均为0。也就是说,如果支取后四位(低位)的话,这个时候产生"碰撞"的几率就非常大(当然&运算中产生碰撞的原因很多,这里只是举个例子)。为了解决低位与操作碰撞的问题,于是便有了第二步中高16位异或低16位的“扰动函数”。
右移16位,自己的高半区和低半区异或,就是为了混合原始哈希码的高位和低位,以此来加大低位随机性。
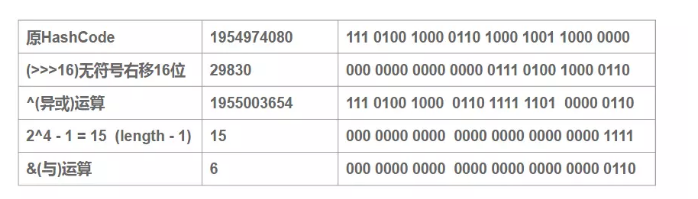
可以看到: 扰动函数优化前:1954974080 % 16 = 1954974080 & (16 - 1) = 0 扰动函数优化后:1955003654 % 16 = 1955003654 & (16 - 1) = 6 很显然,减少了碰撞的几率。
总结:
是为了方便公式运算(公式:a%(2^n) 等价于 a&(2^n-1)),因为在计算机中&运算要快于%运算,正好取二的倍数是为了提高效率。
2.1、再来看看另外一个博主的解释
HashMap的容量为什么是2的n次幂,和这个(n - 1) & hash的计算方法有着千丝万缕的关系,符号&是按位与的计算,这是位运算,计算机能直接运算,特别高效,按位与&的计算方法是,只有当对应位置的数据都为1时,运算结果也为1,当HashMap的容量是2的n次幂时,(n-1)的2进制也就是1111111***111这样形式的,这样与添加元素的hash值进行位运算时,能够充分的散列,使得添加的元素均匀分布在HashMap的每个位置上,减少hash碰撞,下面举例进行说明。
当HashMap的容量是16时,它的二进制是10000,(n-1)的二进制是01111,与hash值得计算结果如下:
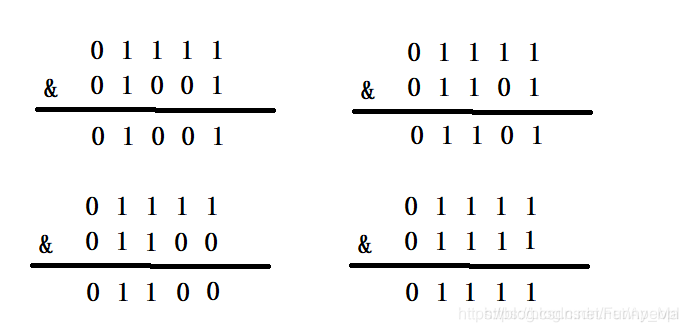
上面四种情况我们可以看出,不同的hash值,和(n-1)进行位运算后,能够得出不同的值,使得添加的元素能够均匀分布在集合中不同的位置上,避免hash碰撞。
下面就来看一下HashMap的容量不是2的n次幂的情况,当容量为10时,二进制为01010,(n-1)的二进制是01001,向里面添加同样的元素,结果为:

可以看出,有三个不同的元素进过&运算得出了同样的结果,严重的hash碰撞了。
终上所述,HashMap计算添加元素的位置时,使用的位运算,这是特别高效的运算;另外,HashMap的初始容量是2的n次幂,扩容也是2倍的形式进行扩容,是因为容量是2的n次幂,可以使得添加的元素均匀分布在HashMap中的数组上,减少hash碰撞,避免形成链表的结构,使得查询效率降低!
原文链接:https://blog.csdn.net/apeopl/article/details/88935422
总结
其实他们两个的原理都是为了减少hash碰撞,计算机中&运算要比%运算快。
3、为什么hashmap的扩容都是原有大小的两倍
假设现在有几个key要放到hashmap里面去:“name”,“age”,“email”,“phone”,当前的哈希表容量是8
1. 通过java的hashCode() 函数可以计算出哈希码
2. 计算对应tab的下标 , (n-1) & hash
“name”字符串的哈希码是3373707(十进制),1100110111101010001011(二进制) & 00000111 = 0011,下标:3
“phone”字符串的哈希码是194811(十进制),101111100011110011(二进制)& 00000111 = 0011,下标:3
“age”字符串的哈希码是96511(十进制), 10111100011111111(二进制)& 00000111 = 0111,下标:7
“email”字符串的哈希码是96619420(十进制),101110000100100101110011100(二进制)& 00000111 = 0100,下标:4
所以目前对应的结构是:

3.此时来扩容,n << 1 新tab 长度就是16,
重新再来计算新的下标,这里就拿name和phone为例:
“name”字符串的哈希码是3373707(十进制),1100110111101010001011 & 00001111 = 1011,下标:11
“phone”字符串的哈希码是194811(十进制),101111100011110011 & 00001111 = 0011,下标:3
name的与7运算结果 是 0011 ,与15运算结果是1011 发现首位高一位,所以离开原有的节点, 那么新的位置 正好就是 原下标 + 原tab长度 = 3 + 8 = 11;
phone的与7运算结果 是 0011 ,与15运算结果是0011 发现首位没有变化,so所有并没变化下标值。
这就是扩大一倍的好处:
当初容量是8,8-1=7,7的二进制是111;
现在容量是16,16-1=15,15的二进制是1111
因为他们都是全为1的形态,而扩大一倍后只是高位加了一个1,所以会留有大概一半的key在原来的空格,
而有一半的key到相同的别的空格中,比如都是从3号位置到了11号位置中,这样也便于复制。通过位运算,代替了模运算!
参考链接:https://blog.csdn.net/saratanglei/article/details/100563788
总结
总结来说还是为了方便运算和复制
4、为什么hashmap的负载因子是0.75
Ideally, under random hashCodes, the frequency of
-
nodes in bins follows a Poisson distribution
-
(http://en.wikipedia.org/wiki/Poisson_distribution) with a
-
parameter of about 0.5 on average for the default resizing
-
threshold of 0.75, although with a large variance because of
-
resizing granularity. Ignoring variance, the expected
-
occurrences of list size k are (exp(-0.5) * pow(0.5, k) /
-
factorial(k)). The first values are:
-
0: 0.60653066
-
1: 0.30326533
-
2: 0.07581633
-
3: 0.01263606
-
4: 0.00157952
-
5: 0.00015795
-
6: 0.00001316
-
7: 0.00000094
-
8: 0.00000006
-
more: less than 1 in ten million
在理想情况下,使用随机哈希吗,节点出现的频率在hash桶中遵循泊松分布,同时给出了桶中元素的个数和概率的对照表。
从上表可以看出当桶中元素到达8个的时候,概率已经变得非常小,也就是说用0.75作为负载因子,每个碰撞位置的链表长度超过8个是几乎不可能的。
hash容器指定初始容量尽量为2的幂次方。
HashMap负载因子为0.75是空间和时间成本的一种折中。
解释:如果负载因子是0.5,那么会浪费很大的空间。如果是负载因子是1,那么会造成很大的hash冲突,因此折中取了0.75
5、为什么hashmap初始化大小会选择16
在《HashMap中傻傻分不清楚的那些概念》文章中,我们介绍了HashMap中和容量相关的几个概念,
简单介绍了一下HashMap的扩容机制。
文中我们提到,默认情况下HashMap的容量是16,但是,如果用户通过构造函数指定了一个数字作为容量,
那么Hash会选择大于该数字的第一个2的幂作为容量。(3->4、7->8、9->16)
本文,延续上一篇文章,我们再来深入学习下,到底应不应该设置HashMap的默认容量?
如果真的要设置HashMap的初始容量,我们应该设置多少?
为什么要设置HashMap的初始化容量
阿里巴巴的java开发手册建议设置初始化大小

那么,为什么要这么建议?你有想过没有。
我们先来写一段代码在JDK 1.7 (jdk1.7.0_79)下面来分别测试下,在不指定初始化容量和指定初始化容量的情况下性能情况如何。(jdk 8 结果会有所不同,我会在后面的文章中分析)
public static void main(String[] args) {
int aHundredMillion = 10000000;
Map<Integer, Integer> map = new HashMap<>();
long s1 = System.currentTimeMillis();
for (int i = 0; i < aHundredMillion; i++) {
map.put(i, i);
}
long s2 = System.currentTimeMillis();
System.out.println("未初始化容量,耗时 : " + (s2 - s1));
Map<Integer, Integer> map1 = new HashMap<>(aHundredMillion / 2);
long s5 = System.currentTimeMillis();
for (int i = 0; i < aHundredMillion; i++) {
map1.put(i, i);
}
long s6 = System.currentTimeMillis();
System.out.println("初始化容量"+aHundredMillion / 2+",耗时 : " + (s6 - s5));
Map<Integer, Integer> map2 = new HashMap<>(aHundredMillion);
long s3 = System.currentTimeMillis();
for (int i = 0; i < aHundredMillion; i++) {
map2.put(i, i);
}
long s4 = System.currentTimeMillis();
System.out.println("初始化容量为"+aHundredMillion+",耗时 : " + (s4 - s3));
Map<Integer, Integer> map3 = new HashMap<>(16);
long s7 = System.currentTimeMillis();
for (int i = 0; i < aHundredMillion; i++) {
map3.put(i, i);
}
long s8 = System.currentTimeMillis();
System.out.println("初始化容量为16,耗时 : " + (s8 - s7));
}
以上代码不难理解,我们创建了4个HashMap,分别使用默认的容量、使用元素个数的一半(5百万)作为初始容量、使用元素个数(一千万)、使用默认元素个数(16)作为初始容量进行初始化。然后分别向其中put一千万个KV。
输出结果:
未初始化容量,耗时 : 8110
初始化容量5000000,耗时 : 4597
初始化容量为10000000,耗时 : 3414
初始化容量为16,耗时 : 3964
从结果中,我们可以知道,在已知HashMap中将要存放的KV个数的时候,设置一个合理的初始化容量可以有效的提高性能。
当然,以上结论也是有理论支撑的。我们上一篇文章介绍过,HashMap有扩容机制,就是当达到扩容条件时会进行扩容。HashMap的扩容条件就是当HashMap中的元素个数(size)超过临界值(threshold)时就会自动扩容。在HashMap中,threshold = loadFactor * capacity。
所以,如果我们没有设置初始容量大小,随着元素的不断增加,HashMap会发生多次扩容,而HashMap中的扩容机制决定了每次扩容都需要重建hash表,是非常影响性能的。
从上面的代码示例中,我们还发现,同样是设置初始化容量,设置的数值不同也会影响性能,那么当我们已知HashMap中即将存放的KV个数的时候,容量设置成多少为好呢?
5.1、HashMap中容量的初始化
这里有一个例子
Map<String, String> map = new HashMap<String, String>(1);
map.put("hahaha", "hollischuang");
Class<?> mapType = map.getClass();
Method capacity = mapType.getDeclaredMethod("capacity");
capacity.setAccessible(true);
System.out.println("capacity : " + capacity.invoke(map));
初始化容量设置成1的时候,输出结果是2。在jdk1.8中,如果我们传入的初始化容量为1,实际上设置的结果也为1,上面代码输出结果为2的原因是代码中map.put(“hahaha”, “hollischuang”);导致了扩容,容量从1扩容到2。
那么,话题再说回来,当我们通过HashMap(int initialCapacity)设置初始容量的时候,HashMap并不一定会直接采用我们传入的数值,而是经过计算,得到一个新值,目的是提高hash的效率。(1->1、3->4、7->8、9->16)
在Jdk 1.7和Jdk 1.8中,HashMap初始化这个容量的时机不同。jdk1.8中,在调用HashMap的构造函数定义HashMap的时候,就会进行容量的设定。而在Jdk 1.7中,要等到第一次put操作时才进行这一操作。
不管是Jdk 1.7还是Jdk 1.8,计算初始化容量的算法其实是如出一辙的,主要代码如下:
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
上面的代码挺有意思的,一个简单的容量初始化,Java的工程师也有很多考虑在里面。
上面的算法目的挺简单,就是:根据用户传入的容量值(代码中的cap),通过计算,得到第一个比他大的2的幂并返回。
聪明的读者们,如果让你设计这个算法你准备如何计算?如果你想到二进制的话,那就很简单了。举几个例子看一下:
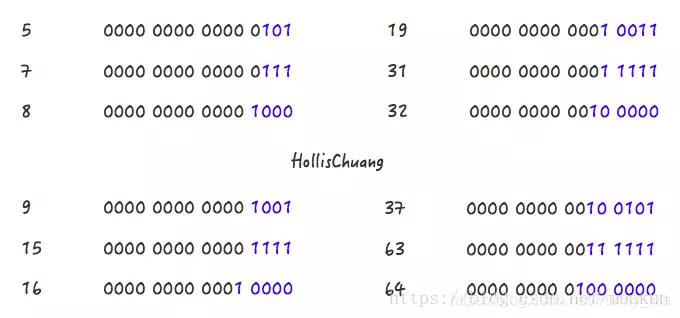
Step 1,5->7
Step 2,7->8
Step 1,9->15
Step 2,15->16
Step 1,19->31
Step 2,31->32
对应到以上代码中,Step1:
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
对应到以上代码中,Step2:
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
Step 2 比较简单,就是做一下极限值的判断,然后把Step 1得到的数值+1。
Step 1 怎么理解呢?其实是对一个二进制数依次向右移位,然后与原值取或。其目的对于一个数字的二进制,从第一个不为0的位开始,把后面的所有位都设置成1。
随便拿一个二进制数,套一遍上面的公式就发现其目的了:
1100 1100 1100 >>>1 = 0110 0110 0110
1100 1100 1100 | 0110 0110 0110 = 1110 1110 1110
1110 1110 1110 >>>2 = 0011 1011 1011
1110 1110 1110 | 0011 1011 1011 = 1111 1111 1111
1111 1111 1111 >>>4 = 1111 1111 1111
1111 1111 1111 | 1111 1111 1111 = 1111 1111 1111
通过几次无符号右移和按位或运算,我们把1100 1100 1100转换成了1111 1111 1111 ,再把1111 1111 1111加1,就得到了1 0000 0000 0000,这就是大于1100 1100 1100的第一个2的幂。
好了,我们现在解释清楚了Step 1和Step 2的代码。就是可以把一个数转化成第一个比他自身大的2的幂。(可以开始佩服Java的工程师们了,使用无符号右移和按位或运算大大提升了效率。)
但是还有一种特殊情况套用以上公式不行,这些数字就是2的幂自身。如果数字4 套用公式的话。得到的会是 8 :
Step 1:
0100 >>>1 = 0010
0100 | 0010 = 0110
0110 >>>1 = 0011
0110 | 0011 = 0111
Step 2:
0111 + 0001 = 1000
为了解决这个问题,JDK的工程师把所有用户传进来的数在进行计算之前先-1,就是源码中的第一行:
int n = cap - 1;
至此,再来回过头看看这个设置初始容量的代码,目的是不是一目了然了:
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
5.2、HashMap中初始容量的合理值
当我们使用HashMap(int initialCapacity)来初始化容量的时候,jdk会默认帮我们计算一个相对合理的值当做初始容量。那么,是不是我们只需要把已知的HashMap中即将存放的元素个数直接传给initialCapacity就可以了呢?
关于这个值的设置,在《阿里巴巴Java开发手册》有以下建议:

这个值,并不是阿里巴巴的工程师原创的,在guava(21.0版本)中也使用的是这个值。
public static <K, V> HashMap<K, V> newHashMapWithExpectedSize(int expectedSize) {
return new HashMap<K, V>(capacity(expectedSize));
}
/**
* Returns a capacity that is sufficient to keep the map from being resized as long as it grows no
* larger than expectedSize and the load factor is ≥ its default (0.75).
*/
static int capacity(int expectedSize) {
if (expectedSize < 3) {
checkNonnegative(expectedSize, "expectedSize");
return expectedSize + 1;
}
if (expectedSize < Ints.MAX_POWER_OF_TWO) {
// This is the calculation used in JDK8 to resize when a putAll
// happens; it seems to be the most conservative calculation we
// can make. 0.75 is the default load factor.
return (int) ((float) expectedSize / 0.75F + 1.0F);
}
return Integer.MAX_VALUE; // any large value
}
在return (int) ((float) expectedSize / 0.75F + 1.0F);上面有一行注释,说明了这个公式也不是guava原创,参考的是JDK8中putAll方法中的实现的。感兴趣的读者可以去看下putAll方法的实现,也是以上的这个公式。
虽然,当我们使用HashMap(int initialCapacity)来初始化容量的时候,jdk会默认帮我们计算一个相对合理的值当做初始容量。但是这个值并没有参考loadFactor的值。
也就是说,如果我们设置的默认值是7,经过Jdk处理之后,会被设置成8,但是,这个HashMap在元素个数达到 8*0.75 = 6的时候就会进行一次扩容,这明显是我们不希望见到的。
如果我们通过expectedSize / 0.75F + 1.0F计算,7/0.75 + 1 = 10 ,10经过Jdk处理之后,会被设置成16,这就大大的减少了扩容的几率。
当HashMap内部维护的哈希表的容量达到75%时(默认情况下),会触发rehash,而rehash的过程是比较耗费时间的。所以初始化容量要设置成expectedSize/0.75 + 1的话,可以有效的减少冲突也可以减小误差。
所以,我可以认为,当我们明确知道HashMap中元素的个数的时候,把默认容量设置成expectedSize / 0.75F + 1.0F 是一个在性能上相对好的选择,但是,同时也会牺牲些内存。
5.3、总结
简单的来说,设置16是为了拥有更好的效率,也可以避免hash碰撞!
参考自: https://blog.csdn.net/l18848956739/article/details/85998121#HashMap%E4%B8%AD%E5%88%9D%E5%A7%8B%E5%AE%B9%E9%87%8F%E7%9A%84%E5%90%88%E7%90%86%E5%80%BC














 2270
2270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









