






 本文详细解读了Lua中用于UTF-8编码字符串解码的函数`utf8_decode`,包括其工作原理、参数处理和严格模式检查,以及如何使用灵码工具配合中文注释进行学习。
本文详细解读了Lua中用于UTF-8编码字符串解码的函数`utf8_decode`,包括其工作原理、参数处理和严格模式检查,以及如何使用灵码工具配合中文注释进行学习。
接上篇,为什么用灵码先从注释开始,因为接下来的解释代码结合着中文的注释,就能更好地理解代码。
我换了一个文件,是Lua原代码里的UTF-8的转换代码的原码作为例子。原码如下,这样的原码对新手是有阅读压力的。
/*
** Decode one UTF-8 sequence, returning NULL if byte sequence is
** invalid. The array 'limits' stores the minimum value for each
** sequence length, to check for overlong representations. Its first
** entry forces an error for non-ascii bytes with no continuation
** bytes (count == 0).
*/
static const char *utf8_decode (const char *s, utfint *val, int strict) {
static const utfint limits[] =
{~(utfint)0, 0x80, 0x800, 0x10000u, 0x200000u, 0x4000000u};
unsigned int c = (unsigned char)s[0];
utfint res = 0; /* final result */
if (c < 0x80) /* ascii? */
res = c;
else {
int count = 0; /* to count number of continuation bytes */
for (; c & 0x40; c <<= 1) { /* while it needs continuation bytes... */
unsigned int cc = (unsigned char)s[++count]; /* read next byte */
if (!iscont(cc)) /* not a continuation byte? */
return NULL; /* invalid byte sequence */
res = (res << 6) | (cc & 0x3F); /* add lower 6 bits from cont. byte */
}
res |= ((utfint)(c & 0x7F) << (count * 5)); /* add first byte */
if (count > 5 || res > MAXUTF || res < limits[count])
return NULL; /* invalid byte sequence */
s += count; /* skip continuation bytes read */
}
if (strict) {
/* check for invalid code points; too large or surrogates */
if (res > MAXUNICODE || (0xD800u <= res && res <= 0xDFFFu))
return NULL;
}
if (val) *val = res;
return s + 1; /* +1 to include first byte */
}接着上通义灵码,先将它注释成中文。选择以上代码,点右键(为什么不直接点灵码图标,因为灵码图标没有包含代码段上方的英文注释。直接框选后点右键就可以省了翻译的过程)
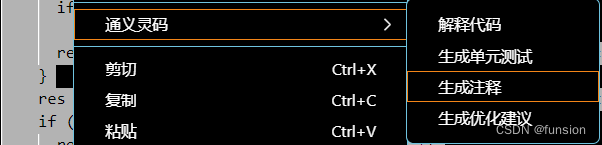
成生的注释如下:
/*
** 解码一个UTF-8序列,如果字节序列无效则返回NULL。数组'limits'存储了每个序列长度的最小值,
** 用于检查过长表示。其第一个条目强制对于没有后续字节的非ASCII字节(计数为0)报错。
**
** @param s 指向要解码的UTF-8字符串的指针。
** @param val 如果非NULL,解码后的Unicode码点将存储在此参数指向的变量中。
** @param strict 如果为1,则采用严格的验证,会检查是否存在无效的Unicode码点(例如代理对)。
** @return 返回解码后的字符的下一个位置指针。如果解码失败或遇到无效字符,则返回NULL。
*/
static const char *utf8_decode (const char *s, utfint *val, int strict) {
/* 定义UTF-8序列长度的最小值数组,用于检测过长的编码形式 */
static const utfint limits[] =
{~(utfint)0, 0x80, 0x800, 0x10000u, 0x200000u, 0x4000000u};
unsigned int c = (unsigned char)s[0]; /* 第一个字节 */
utfint res = 0; /* 存储最终解码结果 */
if (c < 0x80) /* 如果是ASCII字符 */
res = c;
else {
int count = 0; /* 计算后续字节的数量 */
for (; c & 0x40; c <<= 1) { /* 当需要后续字节时... */
unsigned int cc = (unsigned char)s[++count]; /* 读取下一个字节 */
if (!iscont(cc)) /* 如果不是后续字节 */
return NULL; /* 无效的字节序列 */
res = (res << 6) | (cc & 0x3F); /* 将后续字节的低6位添加到结果中 */
}
res |= ((utfint)(c & 0x7F) << (count * 5)); /* 将第一个字节的值添加到结果中 */
if (count > 5 || res > MAXUTF || res < limits[count])
return NULL; /* 无效的字节序列 */
s += count; /* 跳过已读取的后续字节 */
}
if (strict) {
/* 严格检查无效的码点:过大或为代理区码点 */
if (res > MAXUNICODE || (0xD800u <= res && res <= 0xDFFFu))
return NULL;
}
if (val) *val = res; /* 如果val非NULL,将解码结果存储在val中 */
return s + 1; /* 返回下一个待解码字节的位置(包含第一个字节) */
}现在看起来是不是很详细了呢?
接下来才是标题所说的解释代码
然后还是框选已经备注好中文注释的这段代码,点右键(也可以直接点编辑框中灵码的图标),使用灵码的解释代码功能。

结合这个中文的代码解释,你看懂这段代码了吗?
好吧,如果你是老鸟,已经懂了,就到这吧。
学废了吗?还不行…………,还好,在灵码的底部还有一个更详细的按键,接着按它。
该函数
utf8_decode的主要功能是从UTF-8编码的字符串中解码出一个Unicode字符,并在必要时将解码结果存储到传入的变量val中。以下是详细的步骤描述:
初始化:定义了一个静态常量数组
limits[],用于检查UTF-8编码序列是否过长(即超过Unicode编码的最大范围)。同时初始化变量c为输入字符串s的第一个字节,res为最终要存放解码后Unicode值的变量。ASCII字符处理:如果第一个字节
c的值小于0x80,则表示它是单字节的ASCII字符,直接将其作为Unicode值赋给res。多字节UTF-8编码处理:若第一个字节不满足ASCII条件,则进行多字节UTF-8编码解析:
- 初始化计数器
count来统计需要读取的后续字节数。- 使用循环逐个检查每个后续字节的有效性(通过判断字节是否为合法的后续字节,即是否满足UTF-8编码规则)。
- 将每个合法的后续字节的低6位累加到
res中,以构建完整的Unicode码点。- 将第一个字节的部分信息合并到
res中,并根据实际读取的后续字节数调整其位置。- 检查计算得到的
res是否超出Unicode的有效范围或不符合UTF-8编码格式,如超出长度限制、超出Unicode最大值等。如果是,则返回NULL表示遇到无效的字节序列。严格模式检查:如果
strict参数为真,进一步检查解码得到的Unicode码点res是否过大(超过MAXUNICODE)或位于代理区(0xD800u至0xDFFFu之间),这些都属于无效的Unicode码点,此时也返回NULL。存储解码结果:如果输入参数
val非空,将解码得到的Unicode码点res存入val指向的变量。返回值:最后,函数返回指向下一个待解码字节的位置,以便于连续调用此函数对整个UTF-8编码的字符串进行解码。返回值包含已处理过的第一个字节。
到这里,基本有入门级水平的,应该可以看个半懂了。















 927
927











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









