







数据库类型
innoDB
- 结构文件
- 索引数据文件(索引和数据在一个文件中)
MyISAM
MyISAM索引文件和数据文件是分离的(非聚集)
- 结构文件
- 数据文件
- 索引文件
索引
索引是帮助MySql高效获取数据的
排好序的数据结构
索引结构
-
二叉树 (深度高,当插入的数据都是有序时,变成了链表)
-
红黑树 (动态二叉平衡树, 但是深度太高)
-
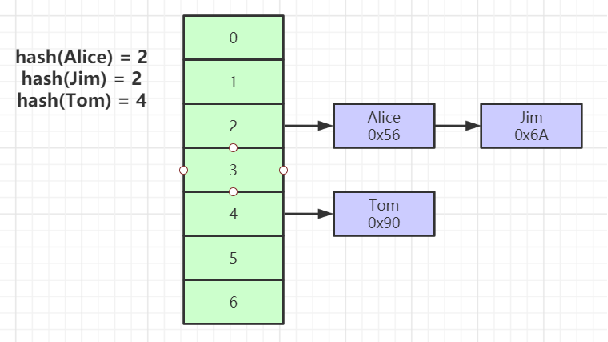
Hash表
-
对索引的key进行一次hash计算就可以定位出数据存储的位置
-
很多时候Hash索引要比B+ 树索引更高效
-
仅能满足 “=”,“IN”,不支持范围查询
-
hash冲突问题
-
-
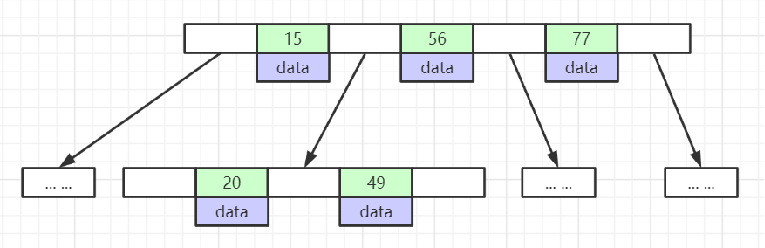
B-树
- 叶子节点具有相同的深度,叶子节点的指针为空
- 所有索引元素不重复
- 节点中的数据从左到右
递增排列
-
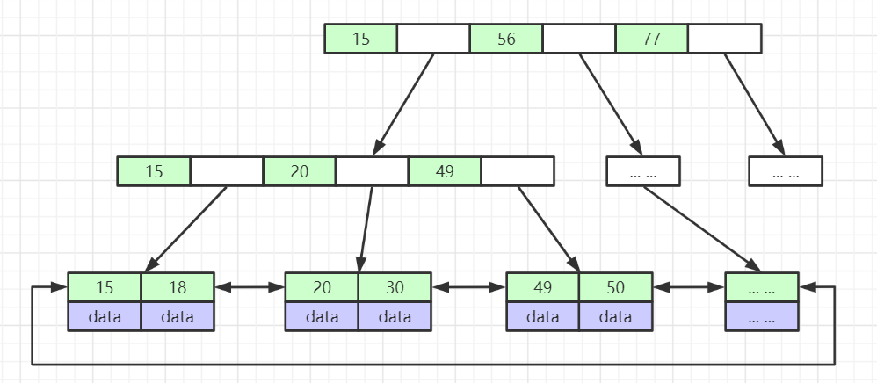
B+树(b-树变种)
-
非叶子节点不存储data,只存储索引(冗余),可以存放更多的索引
-
叶子节点包含所有索引字段
-
叶子节点用指针相连,提高区间访问的性能
-
索引类型
聚集(簇)索引 (InnoDB)
主键存在 - 使用主键索引
主键不存在 - 使用唯一键做索引
没有唯一索引 - mysql自动生成一个隐藏主键
-
建议建立主键
-
建议使用
整型递增索引 --整形大小比较快速,递增索引维护主键索引性能好 -
聚集索引的叶子节点存储是数据
非聚集索引
-
InnoDB
非主键索引, 查询索引以外的数据需要
回表- 叶子节点存储的是 聚集索引的key(主键值) -> 一致性和节省存储空间
-
MyISAM
所有的索引都是非聚集索引
- 每颗索引树的叶子节点存储的是对应的数据文件的地址。
匹配原理
基于索引
排好序的数据结构
-
全值匹配
-
最左前缀原理
-
不在索引列上做任何操作((计算、函数、(自动or手动)类型转换),会导致索引失效走全表扫描 (破坏了顺序结构)
-
存储引擎不能使用索引中范围条件右边的列
-
尽量使用
覆盖索引(二级索引直接返回结果,不用再次进行回表查询)
Explain工具

-
id
代表select的顺序,id越大执行优先级越高
-
select_type
代表查询类型(简单查询还是复杂查询)
- simple:简单查询,只有一个select语句
- primary:复杂查询中的最外层select
- subquery: 包含select的子查询 (不在from子句中)
- derived: 包含在from子句中的子查询。 mysql 会将结果放在一个临时表中
- union: 关联查询
-
table
表示访问的是哪个表
-
type - 关联类型或者访问类型 优(system > const > eq_ref > ref > range > index > ALL )差
-
system
整个表里面只有一条元组数据时,type 为system
-
const
用于
primary key或unique key的常数比较,整个表只有一个匹配行 -
eq_ref
primary key 或者 unique key 索引被连接使用, 最多只会返回一条符合条件的记录
-
ref
相比eq_ref,没有使用唯一索引, 而是使用普通索引,或者唯一索引的部分前缀(联合索引)
-
range
通过索引范围扫描,通常出现在范围查询语句中,
-
index
扫描全索引就能拿到结果,(二级索引,索引覆盖,不会发生回表)
-
All
全表查询,扫描聚簇索引的全部叶子节点
-
-
possible_keys
表示可能会用到的索引
-
key
显示mysql实际使用时哪个索引来优化对表的访问
-
Extra
-
Using index
使用覆盖索引
-
Using where
使用where语句来处理结果,并且查询的列未被索引覆盖 (没有对应索引)
-
Using index conditon
查询的列不完全被索引覆盖,where条件中是一个前导列的范围
-
Using temporary
mysql需要创建一张临时表来处理查询。出现这种情况一般是要进行优化的,首先是想到用索引来优化。
-
Using filesort
将用外部排序而不是索引排序,数据较小时从内存排序,否则需要在磁盘完成排序。这种情况下一般也是要考虑使用索引来优化的。
-














 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









