






“当我们需要快速判断一个元素是否出现在集合里的时候,就要考虑哈希法。”
哈希表理论基础:Hash Table 哈希表是根据关键码的值而直接进行访问的数据结构。
直白来讲数组就是一张哈希表,关键码对应的是数组的索引下标,通过下表直接访问数组中的元素。
哈希表能够解决的问题:用来快速判断一个元素是否出现在集合里。枚举的话时间复杂度是O(1),但是如果使用哈希表,只需要O(1)就可以做到。
将内容映射到哈希表上就涉及到Hash Function,也就是哈希函数。
只需要把需要存储的内容转换成哈希表的索引,然后再查询时就可以通过查询索引下标快速查询内容是否在表中了。
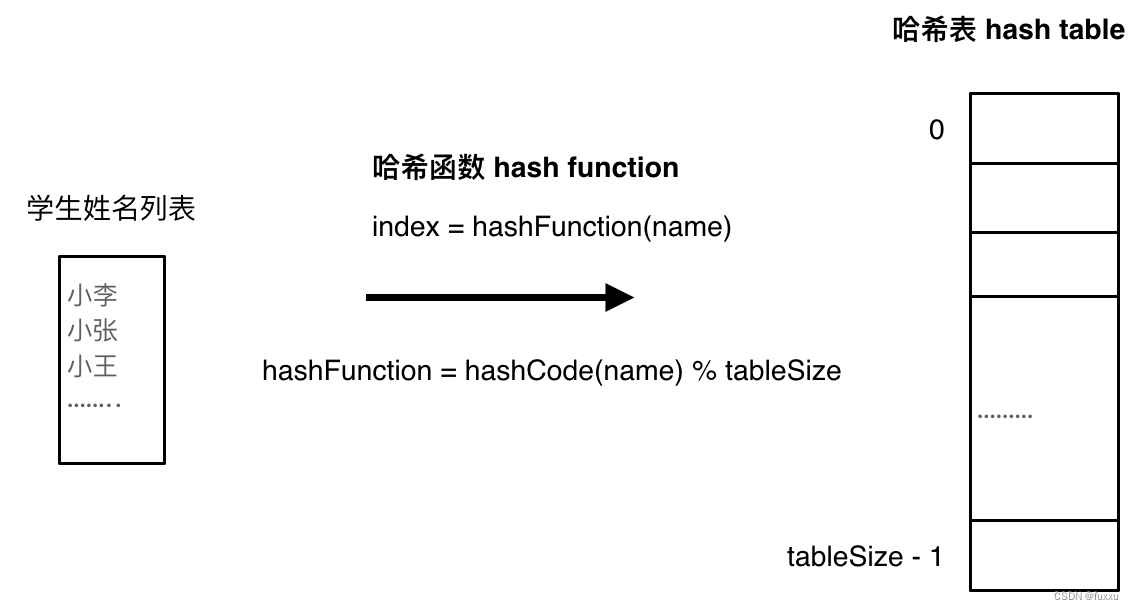
把内容转换成索引,涉及到哈希函数的使用。通过HashCode把内容转化为数值,一般HashCode是通过特定的编码方式,可以将其他数据格式转化为不同的数值,这样就可以把需要存储的内容应这位哈希表上的索引数字了。
接下来,我们得到了转换之后的数值,但是可出现数值大于HashTableSize的情况,如何解决?
为了保证映射出来的索引数值都落在哈希表上,我们会再对得到的数值做取模操作。
这时候又会出现一个问题, 如果需要存储的index数量大于HashTableSize,就会出现不同的index需要存储到同一个位置的情况,如何解决?
不同的内容映射到同一个索引下的现象叫做哈希碰撞Hash Collisions:

解决哈希碰撞有两种解决方法,拉链法和线性探测法。
拉链法:
A、B在索引1的位置发生了冲突,发生冲突的元素通过链表存储。这样我们就可以通过索引找到元素A、B了。
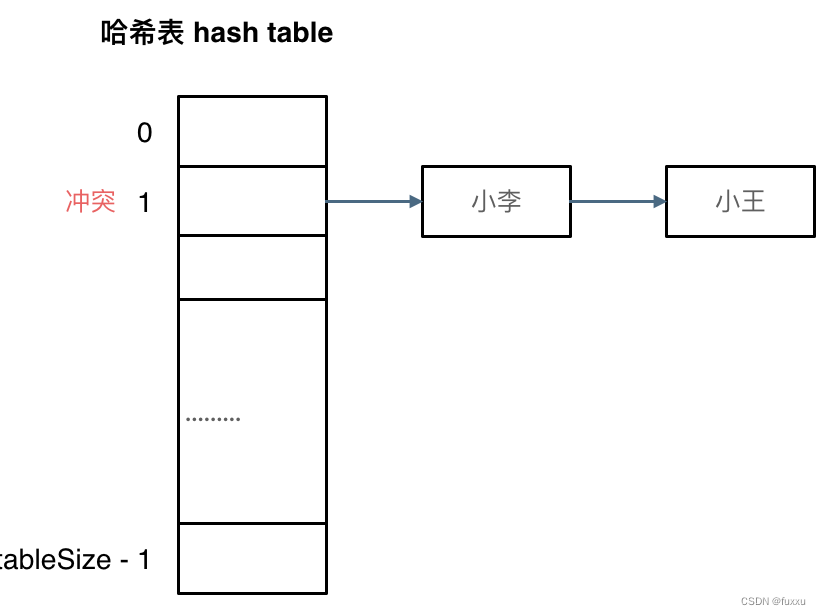
(数据规模是dataSize,哈希表的大小为tableSize)
拉链法需要选择适当的哈希表大小,这样既不会因为数组空置而浪费内存,也不会因为链表太长而在查找上浪费太多时间。
线性探测法:
保证HashTableSize大于DataSize。我们需要依靠哈希表中的空位来解决碰撞问题。
A、B位置冲突,向下寻找一个空位来存放B的信息,所以一定要保证HashTableSize大于DataSize。

常见的三种哈希结构 :
- 数组
- set(集合)
- map(映射)
在C++中,set和map分别提供一下三种数据结构,底层实现和优劣如下所示:
| 集合 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::set | 红黑树 | 有序 | 否 | 否 | O(log n) | O(log n) |
| std::multiset | 红黑树 | 有序 | 是 | 否 | O(logn) | O(logn) |
| std::unordered_set | 哈希表 | 无序 | 否 | 否 | O(1) | O(1) |
红黑树是一种平衡的二叉搜索树,所以key值是有序的,但是key不可以修改,改动key值会导致整棵树错乱,所以只能删除和增加。
| 映射 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| std::map | 红黑树 | key有序 | key不可重复 | key不可修改 | O(logn) | O(logn) |
| std::multimap | 红黑树 | key有序 | key可重复 | key不可修改 | O(log n) | O(log n) |
| std::unordered_map | 哈希表 | key无序 | key不可重复 | key不可修改 | O(1) | O(1) |
std::map和std::multimap的key是有序的。
使用集合来解决哈希问题时,优先使用unordered_set,因为它的查询和增删效率是最优的。如果需要集合是有序的,那么就用set。如果不仅要求有序还有重复数据的话,就用multiset。
在map中,对key是有限制的,对value是没有限制的,因为key的存储方式使用红黑树实现。
set、multiset、map、multimap虽然使用红黑树作为底层实现,但是使用时依然是哈希表的使用方式,即key和value。所以使用这些数据结构来解决映射问题的方法,依然被称为哈希法。
unordered_set在C++11的时候被引入标准库,hash_set,hash_map是C++11标准之前民间高手自发造的轮子。
总结:
需要快速判断一个元素是否出现在集合中时,考虑使用哈希法。
哈希法牺牲了空间换时间,使用额外的数组、set或map来存放数据,实现快速查找。
242. 有效的字母异位词
题目要求:给定两个字符串s和t,编写一个函数来判断t是否是s的字母异位词。
数组就是一个简单的哈希表,而且这道题的字符串中只有小写字符,可以定义一个数组来记录字符串中字符出现的次数。如果数组之间match的话,那么两个字符串就是异位的。
使用Hash Table需要一种映射的方法,这里可以采用ASCII的方法,把字符映射成为数组的下标。在遍历字符串s时,只需要将s[i]-'a'所在的元素做+1操作即可。这样就可以将字符串s中字符出现的次数统计出来了。
在遍历字符串t的时候,对t中出现的字符的映射在哈希表的所以上做数值-1操作。
最后检查,数组中的元素是否为0,全部为0,return true。如果有任意位置不为0,return false。
时间复杂度为O(n),空间上因为定义的是一个常量大小的数组,所以空间复杂度为O(1)。
C++:
class Solution {
public:
bool isAnagram(string s, string t) {
int record[26] = {0};
for (int i = 0; i < s.size(); i++){
record[s[i]-'a'] += 1;
}
for (int i = 0; i < t.size(); i++){
record[t[i]-'a'] -= 1;
}
for (int i = 0; i < 26; i++){
if (record[i] != 0){
return false;
}
}
return true;
}
};Python:
class Solution(object):
def isAnagram(self, s, t):
"""
:type s: str
:type t: str
:rtype: bool
"""
record = [0] * 26
for i in s:
record[ord(i)-ord("a")] += 1
for i in t:
record[ord(i)-ord("a")] -= 1
for i in range(26):
if record[i]!=0:
return False
return True
389. 两个数组的交集(看错题号了)
题目要求:给定两个字符串 s 和 t。 字符串 t 是通过随机打乱字符串 s 生成的,然后在随机位置再添加一个字母。 返回添加到 t 的字母。
翻译一下:求s和t数组不考虑顺序的交集。
延续上一题的思路,依然把record加s减t,然后返回最后剩下的元素的index,就是添加到t的字母。如果先加s再减t,最后剩下的为-1的index就是结果。因为t比s多一位,所以减的时候会把这一位减到-1。
C++:
class Solution {
public:
char findTheDifference(string s, string t) {
int record[26] = {0};
for (int i=0; i < s.size(); i++){
record[s[i]-'a'] += 1;
}
for (int i=0; i < t.size(); i++){
record[t[i]-'a'] -= 1;
}
for (int i=0; i < 26; i++){
if (record[i]==-1){
return static_cast<char>(i+'a');
}
}
return '\0';
}
};Python:
class Solution(object):
def findTheDifference(self, s, t):
"""
:type s: str
:type t: str
:rtype: str
"""
record = [0] * 26
for i in s:
record[ord(i)-ord("a")] += 1
for i in t:
record[ord(i)-ord("a")] -= 1
for i in range(26):
if (record[i]==-1):
return chr(i+ord('a'))
return None349. 两个数组的交集
题目要求:求两个数组的交集。
数组大小小于1000,理论上我们需要创建一个大小为1000的数组,就可以按照上面的方法解决。
但是这道题也可以尝试使用一种哈希数据结构:unordered_set。
题目特别说明:输出结果中的每个元素一定是唯一的,也就是说输出结果是去重的,同时可以不考虑输出结果的顺序。
(如果哈希值比较少、特别分散、跨度大,只用数组就造成空间的极大浪费。)
set和multiset底层实现都是红黑树,unordered_set底层实现是哈希表,使用unordered_set读写效率最高,并不需要对数据进行排序,而且去重,因此可以选择unordered_set。

C++:
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
std::unordered_set<int> result_set;
std::unordered_set<int> nums_set(nums1.begin(), nums1.end());
for (int num : nums2){
if (nums_set.find(num) != nums_set.end()){
// 如果num在num_set(即nums1的元素集合)中存在,
// find()函数将返回该元素的迭代器;否则,它返回end()。
result_set.insert(num);
}
}
return vector<int>(result_set.begin(), result_set.end());
}
};使用set的缺点:直接使用set不仅占用空间比数组大,而且速度比数组慢。set把数值映射到key上都要做hash计算的。在数据量大的情况下,这个差距是很明显的。
Python(使用集合):
class Solution(object):
def intersection(self, nums1, nums2):
"""
:type nums1: List[int]
:type nums2: List[int]
:rtype: List[int]
"""
return list(set(nums1) & set(nums2))
# set(nums1): 把列表nums1转换为集合。集合是一个无序的、不包含重复元素的数据结构。
# set(nums2): 把列表nums2也转换为集合。
# set(nums1) & set(nums2): 使用&运算符计算两个集合的交集。
# 该运算符返回一个新集合,其中包含两个输入集合中都存在的元素。Python(使用字典和集合):
class Solution(object):
def intersection(self, nums1, nums2):
"""
:type nums1: List[int]
:type nums2: List[int]
:rtype: List[int]
"""
# 初始化一个空的哈希表(或字典)
table = {}
for num in nums1:
table[num] = table.get(num, 0) + 1
# 初始化一个空的集合res
res = set()
for num in nums2:
# 如果存在,将该元素添加到集合res中,并从table中删除该元素(以防止重复添加)。
if num in table:
res.add(num)
del table[num]
return list(res)202. 快乐数
题目要求:编写一个算法来判断一个数n是不是快乐数。
「快乐数」定义为:对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和,然后重复这个过程直到这个数变为 1,也可能是 无限循环 但始终变不到 1。如果 可以变为 1,那么这个数就是快乐数。
无限循环:意味着求和过程中,sum会重复出现。如果sum重复出现了,就是false,反之则会找到sum=1.
C++:
class Solution {
public:
int getSum(int n){
int sum = 0;
while (n){
sum += (n % 10) * (n % 10);
n /= 10;
}
return sum;
}
bool isHappy(int n) {
unordered_set<int> set;
while (1){
int sum = getSum(n);
if (sum == 1){
return true;
}
if (set.find(sum) != set.end()){
return false;
} else{
set.insert(sum);
}
n = sum;
}
}
};Python:
class Solution(object):
def isHappy(self, n):
"""
:type n: int
:rtype: bool
"""
seen = set()
while n!=1:
n = sum(int(i) ** 2 for i in str(n))
if n in seen:
return False
seen.add(n)
return True1. 两数之和
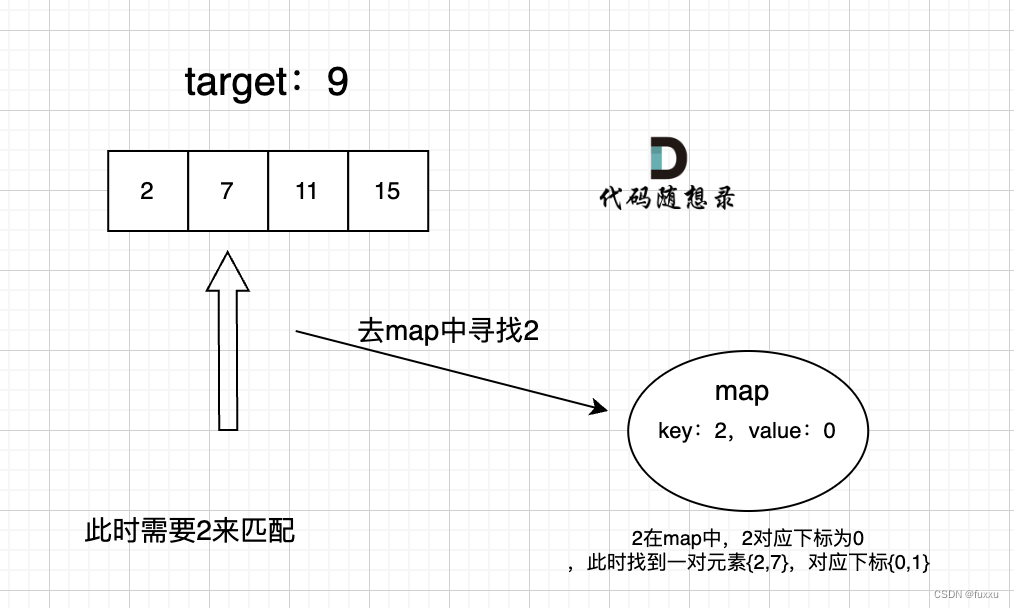
题目要求:求数组中两个元素之和为目标值的元素位置。
这道题目中并不需要key有序,选择std::unordered_map 效率更高。
这道题我们需要给出一个元素,判断这个元素是否出现过,如果出现过,返回这个元素的下标。(这种需要判断重复出现的问题考虑使用哈希表,把问题转化成重复出现问题)
那么判断元素是否出现,这个元素就要作为key,所以数组中的元素作为key,有key对应的就是value,value用来存下标。
所以map中的存储结构为 {key:数据元素,value:数组元素对应的下标}。
在遍历数组的时候,只需要向map去查询是否有和目前遍历元素匹配的数值,如果有,就找到的匹配对,如果没有,就把目前遍历的元素放进map中,因为map存放的就是我们访问过的元素。

C++:
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
std::unordered_map <int, int> map;
for (int i = 0; i < nums.size(); i++){
// 遍历当前元素,并在map中寻找是否有匹配的key,key对应的val就是key在数组nums中的位置
auto iter = map.find(target - nums[i]);
if (iter != map.end()){
// 如果iter存在,返回iter的val即对应的位置,以及i
return {iter->second, i};
}
// 如果没有找到对应元素,则把当前元素加到map中
map.insert(pair<int, int>(nums[i], i));
}
return {};
}
};Python(使用字典):
class Solution(object):
def twoSum(self, nums, target):
"""
:type nums: List[int]
:type target: int
:rtype: List[int]
"""
records = dict()
for index, value in enumerate(nums):
if target - value in records:
return [records[target - value], index]
else:
records[value] = index
return []Python(使用集合):
class Solution(object):
def twoSum(self, nums, target):
"""
:type nums: List[int]
:type target: int
:rtype: List[int]
"""
seen = set()
for i, num in enumerate(nums):
complement = target - num
if complement in seen:
return [nums.index(complement), i]
seen.add(num)
return []














 893
893











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









