







文章目录
1.分析网页
1.1为什么要分析网页
我们需要从一个网页中爬取东西时,如果对网页中有什么东西、网页如何构成都不清楚,我们是很难进行爬取的,所以这一步是为了后面爬取的方便实施。
1.2如何分析网页
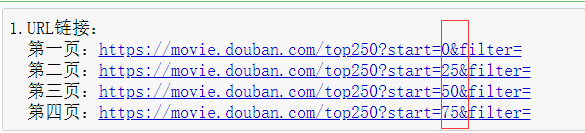
在这里,我要爬取的是豆瓣Top250上的东西。首先,我们得进入该网页,查看它的网页结构。点击【下一页】,查看网页的URL(也就是它的链接),多换几页之后会发现有如下图所示规律:
1.3打开编辑环境
首先我们需要安装jupyter,使用Win+R,弹出一个框,输入cmd之后弹出一个黑框(控制台),然后使用pip install jupyter命令安装jupyter,安装成功后在电脑的G盘中执行以下步骤即可打开编辑环境:
- 新建文件夹
- 在文件夹导航栏输入cmd回车
- 在弹出的黑框(控制台)中输入 jupyter notebook
1.4生成链接
利用我们发现的规律,使用for循环,生成链接,然后对生成的链接随便找几个来测试是否和原网页链接相同
for page in range(0,226,25):
url= 'https://movie.douban.com/top250?start=%s&filter='%page

2.请求网页
接下来就是向服务器发出请求了,我们先选择第一个链接来进行测试,完成本页所有内容的获取,然后再获取其他所有页面的信息
2.1导入包
这里需要用到requests这个,没有安装的话需要安装这个包,安装步骤如下:#pip安装 pip install requests-------->win+r,运行--------->cmd,回车-------->输入pip install requests
2.2设置浏览器代理
在网页中点击右键,打开检查,选择Network,All,刷新网页,选择第一个文件,双击,选择headers

设置的浏览器代理必须为字典型,如:
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.87 Safari/537.36'
}
2.3请求服务器
请求源代码,向服务器发出请求,200代表成功,使用get()获取
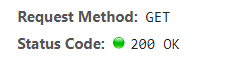
test_url 是一个链接,第二个 headers 是用来做浏览器代理的内容
response=requests.get(url=test_url,headers=headers).text
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1412
1412











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









