









转载请注明本文出自文韬_武略的博客(http://blog.csdn.net/fwt336/article/details/60761277),请尊重他人的辛勤劳动成果,谢谢!
对于C/C++代码中参数类型的解释,请参考文章:http://blog.csdn.net/fwt336/article/details/59540356
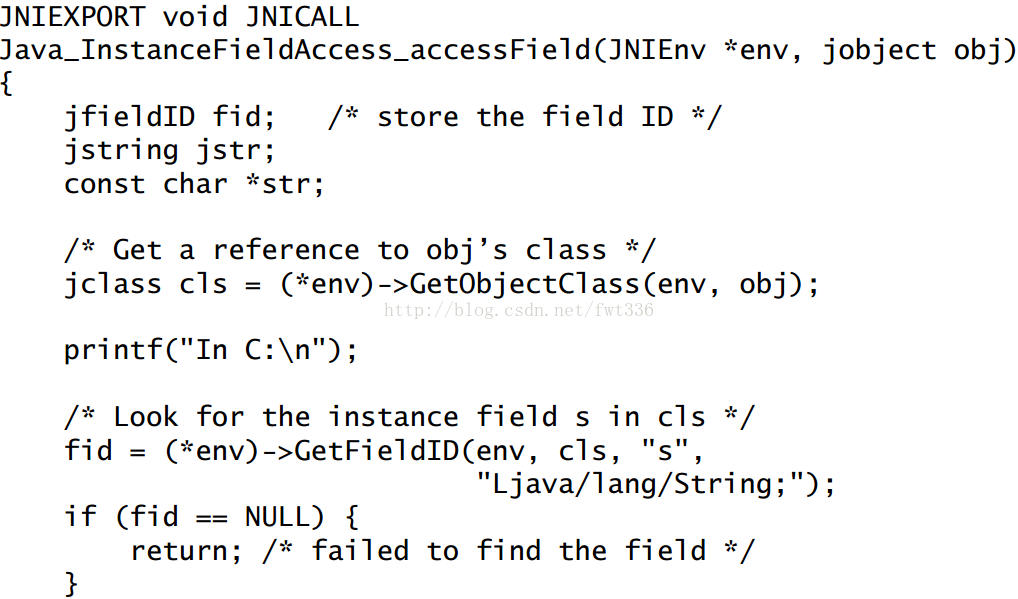
1.访问非静态成员变量
java代码:

c代码:

结果:
In C:
c.s = "abc"
In Java:
c.s = "123"
主要通过这个方法来获取成员变量:
//获取Object类引用
jclass cls = (*env)->GetObjectClass(env, obj);
//获取MethodID
fid = (*env)->GetFieldID(env, cls, "s", "Ljava/lang/String;");
//设置变量
(*env)->SetObjectField(env, obj, fid, jstr);
2.访问静态成员变量
Java代码:
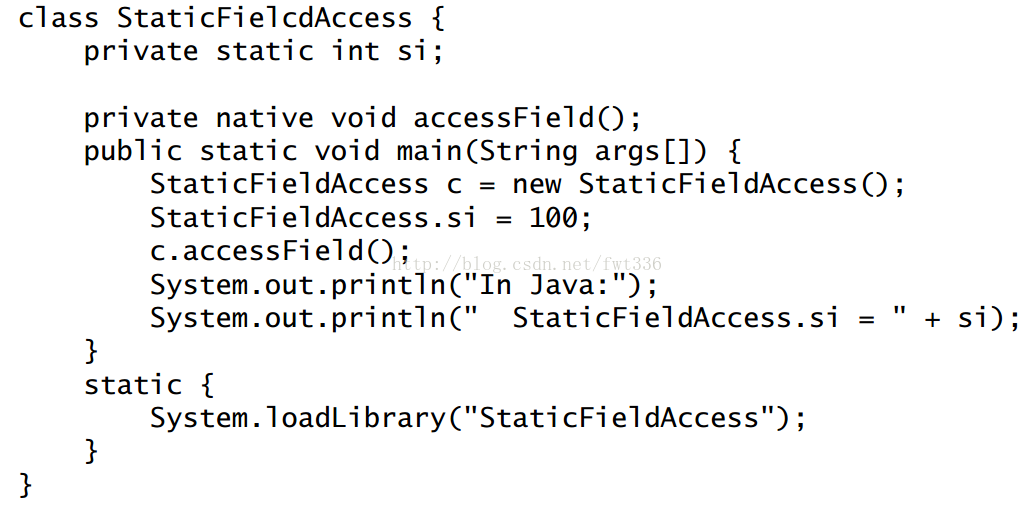
C代码:

打印结果:

与获取非静态方法不同的是,这里的GetStaticFieldID方法,添加了一个static关键字,而在获取具体的变量是GetStaticIntField,也添加了static关键字,还指明了具体的类型int。而它的set方法与get方法也类似。
3.访问非静态方法
Java代码:

C代码:
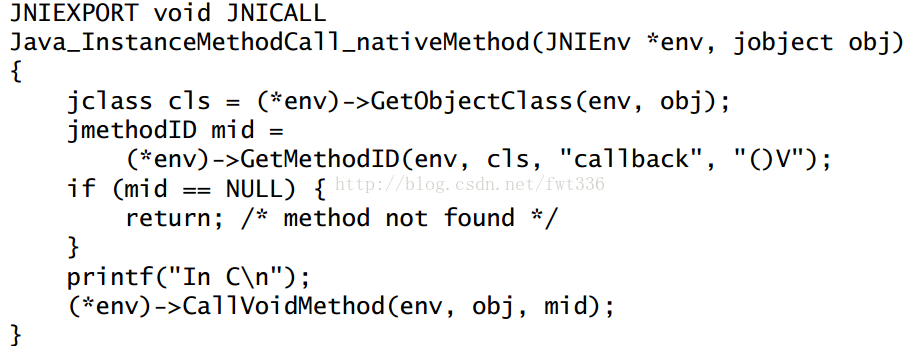
打印结果:
In C
In Java
代码很简单,直接调用GetMethodID方法获取到MethodId,然后调用Call<Type>Method方法即可。
4.访问静态方法
Java代码:

C代码:
与调用非静态方法很相似,只是多了个static而已。

5.调用父类的方法
通过CallNonvirtual<Type>Method 方法,可以调用被重写了的父类的方法。通过是通过GetMethodID或者GetStaticMethodID来获取MedthodID。但是使用的类名确是superclass。
6.调用构造方法


当然下面这个方法可以取代上面的方法:
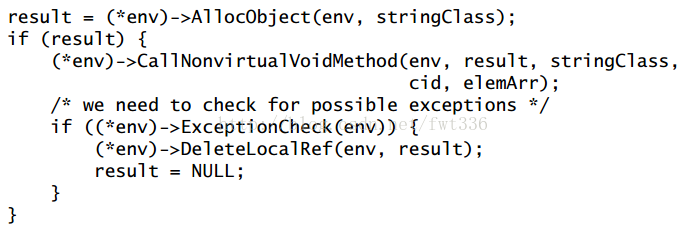
通过AllocObject方法可以创建一个未初始化的类,然后必须通过构造方法来初始化该Object,但是不要多次调用构造方法。















 789
789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









