 理解各类排序算法的时间复杂度
理解各类排序算法的时间复杂度







 本文详细解析了冒泡排序、插入排序、合并排序、堆排序和快速排序的复杂度,从上届、渐进紧确、下届、非渐进紧确等多个角度深入分析,并对比了它们在不同情况下的表现。
本文详细解析了冒泡排序、插入排序、合并排序、堆排序和快速排序的复杂度,从上届、渐进紧确、下届、非渐进紧确等多个角度深入分析,并对比了它们在不同情况下的表现。
先列出一些算法复杂度的标识符号的意思, 最常用的是O,表示算法的上届,如 2n2 = O(n2 ), 而且有可能是渐进紧确的, 意思是g(n)乘上一个常数系数是可以等于f(n)的,就是所谓的a<=b。而o的区别就是非渐进紧确的,如2n = o(n2 ), o(n2 )确实可以作为2n的上届, 不过比较大, 就是所谓的a<b.
其他符号表示了下届,和非渐进紧确的下届, a>=b, a>b
还有既是上届也是下届, 就是a=b
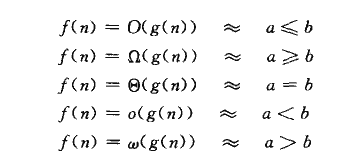
Bubble Sort
冒泡排序效率是最低的, 对于list中任意一点, 都必须遍历其后所有元素以找到最小元素, 这个耗费是n
所以对于完整的冒泡算法, 对list中n个点, 算法复杂度就是n2
Insert Sort
对于插入的任一个元素, 最差情况是需要遍历它之前的所有元素, 才能找到插入位置. 但这个是最差情况, 一般不需要.
所以他的复杂度同样是n2
, 但对于普通的排序, 效率要高于冒泡
Merge Sort
这个算法是基于二分法的递归算法, 把二分递归的过程图形化, 会形成一个递归树(对分析表示分治算法的递归式的复杂度时,递归树方法好用形象). 树高为logn, 对于树的每一层进行并归操作, 可以看出每层并归的耗费最大是n, 所以算法复杂度就是nlogn.
Merge Sort的缺点就是, 它不是inplace的, 需要耗费和输入同样大小的数据空间.
Heap Sort
堆排序首先是建堆, 建堆就是对所有非叶子节点进行堆化操作, 堆化的最大耗费是logn, 所以建堆的最大耗费是nlogn, 但是其实大部分的节点的高都远远没有logn, 这个可以计算出实际的最大耗费只有n.
最后排序的耗费n-1次堆化操作, 所以整个的复杂度为nlogn.
堆排序复杂度达到nlogn, 而且是inplace算法.
Quick Sort
快排在最差的情况下,即对于已经排好序的序列, 每次划分都是0和n-1, 这样的算法复杂度为n2
.这种情况下如果表示成递归树, 树高为n, 每层partition的耗费是n,所以复杂度为n*n
而在最好情况下就是, 序列为对称的, 每次为折半划分, 这个情况和并归排序一样, 耗费为nlogn
而在平均情况下, 可以证明是接近最好情况的, 即复杂度为nlogn,原因是任何一种按常数比例进行的划分都会产生深度为lgn的递归树
其他排序问题
对于普通的排序算法, 即比较排序算法, 复杂度的下限为nlogn, 不可能比这个更少
对于这个的理解是, 比较排序可以被抽象为决策树,
对于n个元素可能的排列为n!个, 所以树的叶子节点有n!个, 对于一个高h的树, 叶子节点最多有2h
个,
所以可以算出h的下限为nlogn
而对于比较排序而言, 任意两个元素的顺序都要通过一次比较来完成,
所以下限为需要两两比较的次数
如果要突破这个下限, 就必须基于某种假设, 而不可能是通用的比较算法.
比如计数排序,
假设输入由一个小范围内(小于k)的整数构成, 那排序方法很简单, 建立一个长度为k的数组A, 遍历输入, 并把输入i放入相应的A[i]中.
排序只要O(n)
如果是桶排序, 假设输入为均匀分布[0,1), 由一个随机过程产生. 把[0,1)区域均匀划分为n个子区域,
称为桶, 然后把输入分布到各个桶中. 用于输入是均匀分布的, 每个桶中的输入一定很少, 那么先在桶内排序, 然后把各个桶中的元素列出来即可.

















 2503
2503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









