







冒泡排序
实现思路:通过从列表一端迭代循环元素,再通过一个循环让这个元素之后的元素相邻两个比较,从而依次将最大值移动到最末端
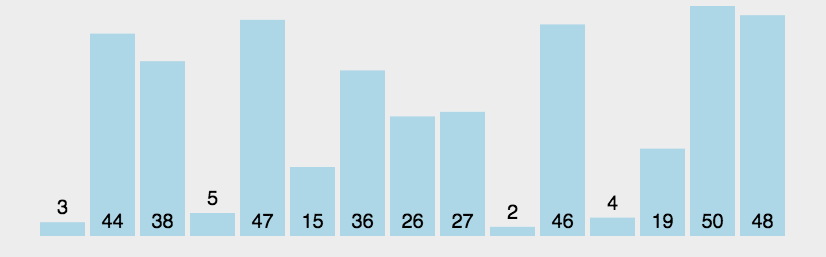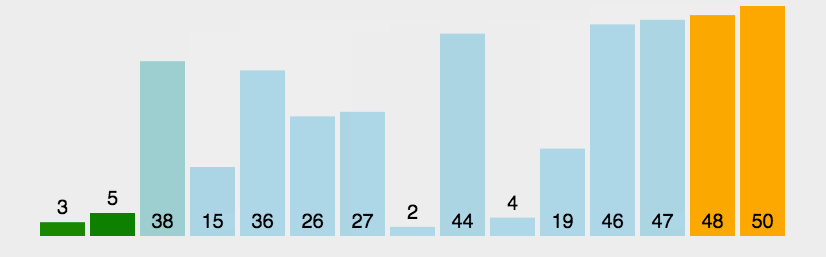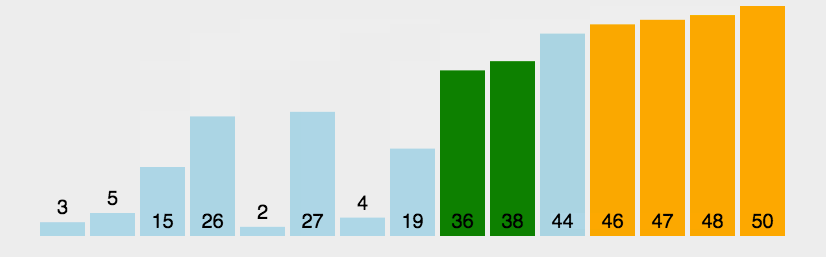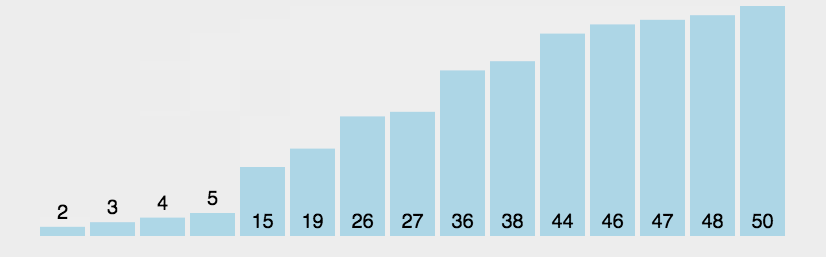
nums = [7, 4, 3, 67, 34, 1, 8]
def bubble_sort(nums):
for i in range(len(nums) - 1):
for j in range(len(nums) - i - 1):
if nums[j] > nums[j + 1]:
nums[j], nums[j + 1] = nums[j + 1], nums[j]
return nums
bubble_sort(nums)
print(nums) # [1, 3, 4, 7, 8, 34, 67]优化
写到这里我们发现,第一种写法,并没有带来性能的提升,想象一下,如果我们输入的本来就是一个有序序列,其实只需要一次循环就够了,所以我们需要针对特殊情况进行优化
def bubble_sort(nums):
for i in range(len(nums) - 1):
count = 0
for j in range(len(nums) - i - 1):
if nums[j] > nums[j + 1]:
nums[j], nums[j + 1] = nums[j + 1], nums[j]
count += 1
if count == 0:
continue
return nums选择排序
原理: 是把序列中的最小值或者最大值找出来放在起始位置,然后再从剩下的序列中找出极值放到起始位置之后,以此类推最后就完成排序。
完成这个过程大致思想:首先需要一个记录器,记录排序排到第几个位置了,然后在剩余的序列中找到极值下标,最后将记录器位置和极值位置元素交换,完成本次选择排序。
def selection_sort(arr):
for i in range(len(arr) - 1): # 第一层for表示循环选择的遍数
min_index = i # 将起始元素设为最小元素
for j in range(i + 1, len(arr)): # 第二层for表示最小元素和后面的元素逐个比较
if arr[j] < arr[min_index]:
min_index = j # 如果当前元素比最小元素小,则把当前元素角标记为最小元素角标
arr[min_index], arr[i] = arr[i], arr[min_index] # 查找一遍后将最小元素与起始元素互换
return arr关于选择排序的时间复杂度:
选择排序的交换操作介于 0 和 (n - 1)次之间。选择排序的比较操作为 n (n - 1) / 2 次之间。选择排序的赋值操作介于 0 和 3 (n - 1) 次之间。
比较次数O(n^2),比较次数与关键字的初始状态无关,总的比较次数N=(n-1)+(n-2)+...+1=n*(n-1)/2。交换次数O(n),最好情况是,已经有序,交换0次;最坏情况交换n-1次,逆序交换n/2次。交换次数比冒泡排序少多了,由于交换所需CPU时间比比较所需的CPU时间多,n值较小时,选择排序比冒泡排序快。
插入排序算法
插入排序,其原理是通过构建一个初始的有序序列,然后从无需序列中抽取元素,插入到有序序列的相对排序位置,就像将一堆编号混乱的书,一本一本的放到书架上,找到上下编号之间的位置插入,最后完成整理。
算法思想
- 从第二个元素开始和前面的元素进行比较,如果前面的元素比当前元素大,则将前面元素 后移,当前元素依次往前,直到找到比它小或等于它的元素插入在其后面
- 然后选择第三个元素,重复上述操作,进行插入
- 依次选择到最后一个元素,插入后即完成所有排序
python实现插入排序并不难,从第二个位置开始遍历,与它前面的元素相比较,如果比前面元素小就交换位置,实现如下:
def insertion_sort(arr):
for i in range(1, len(arr)): # 第一层for表示循环插入的遍数
current = arr[i] # 设置当前需要插入的元素
pre_index = i - 1 # 与当前元素比较的比较元素
while pre_index >= 0 and arr[pre_index] > current:
arr[pre_index + 1] = arr[pre_index] # 当比较元素大于当前元素则把比较元素后移
pre_index -= 1 # 往前选择下一个比较元素
arr[pre_index + 1] = current # 当比较元素小于当前元素,则将当前元素插入在 其后面
return arr
插入排序的可应用的场景:需要合并两个有序序列,并且合并后的序列依旧有序,此时插入排序可以排上用场。
快速排序
快排的实现方式多种多样,这里给大家写一种容易理解的:分治+迭代,只需要三步:
- 在数列之中,选择一个元素作为"基准"(pivot),或者叫比较值。
- 数列中所有元素都和这个基准值进行比较,如果比基准值小就移到基准值的左边,如果比基准值大就移到基准值的右边
- 以基准值左右两边的子列作为新数列,不断重复第一步和第二步,直到所有子集只剩下一个元素为止。
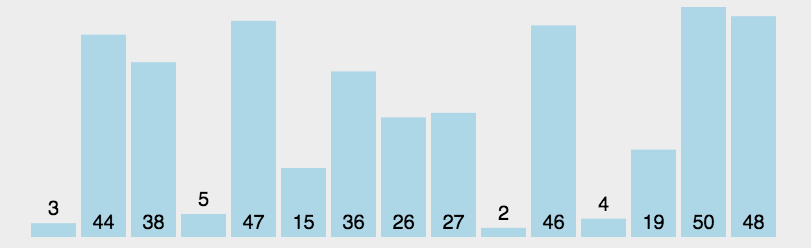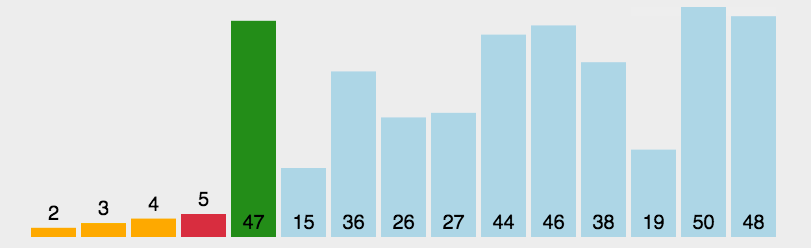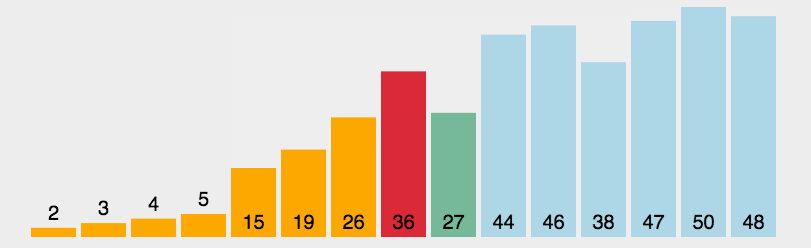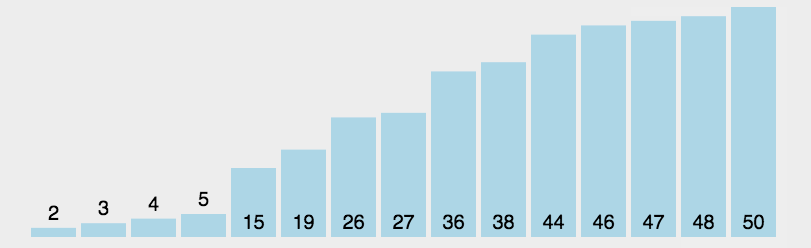
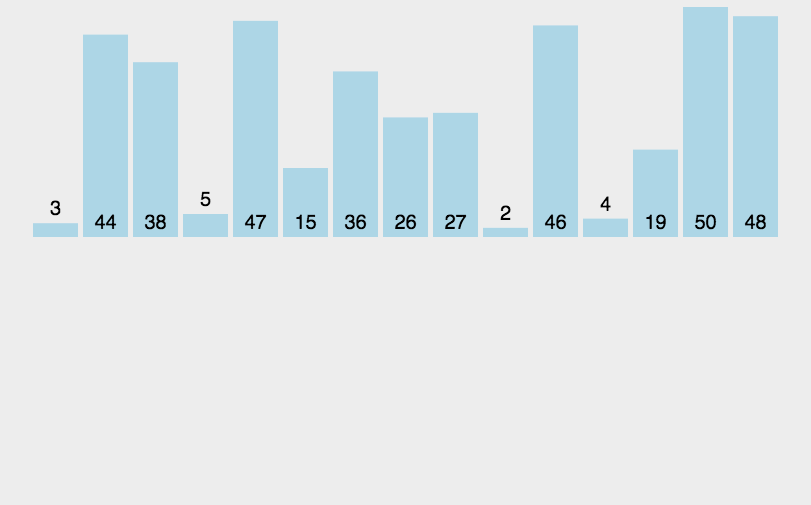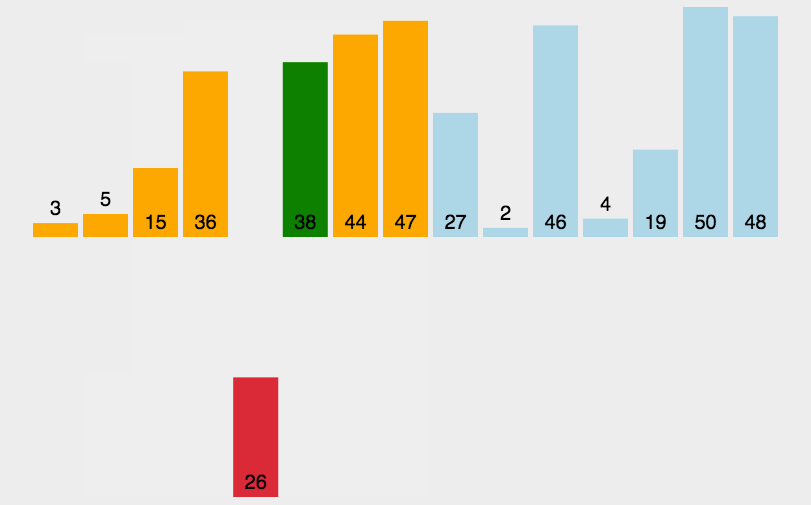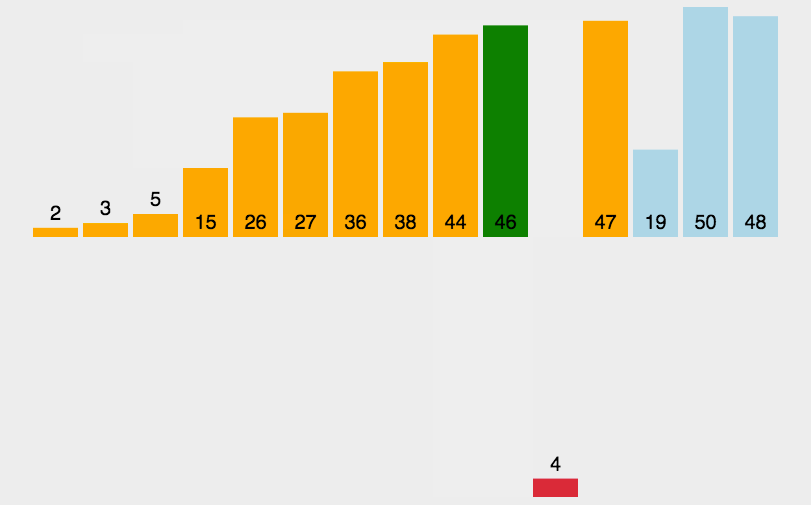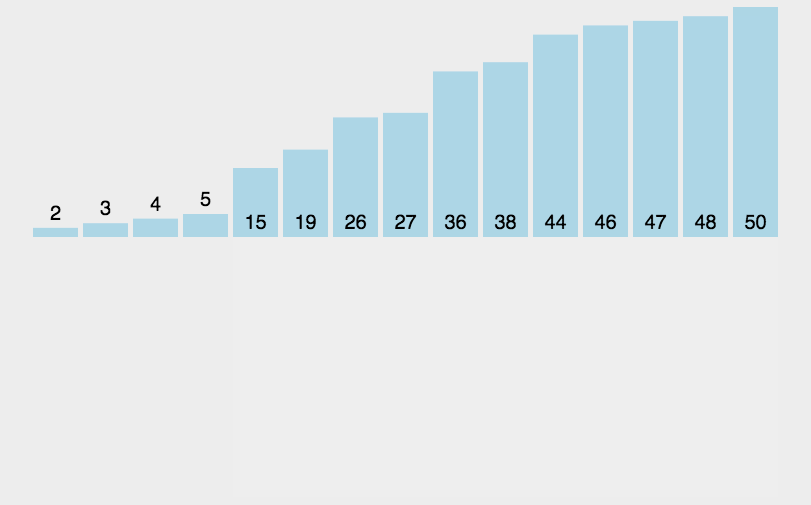
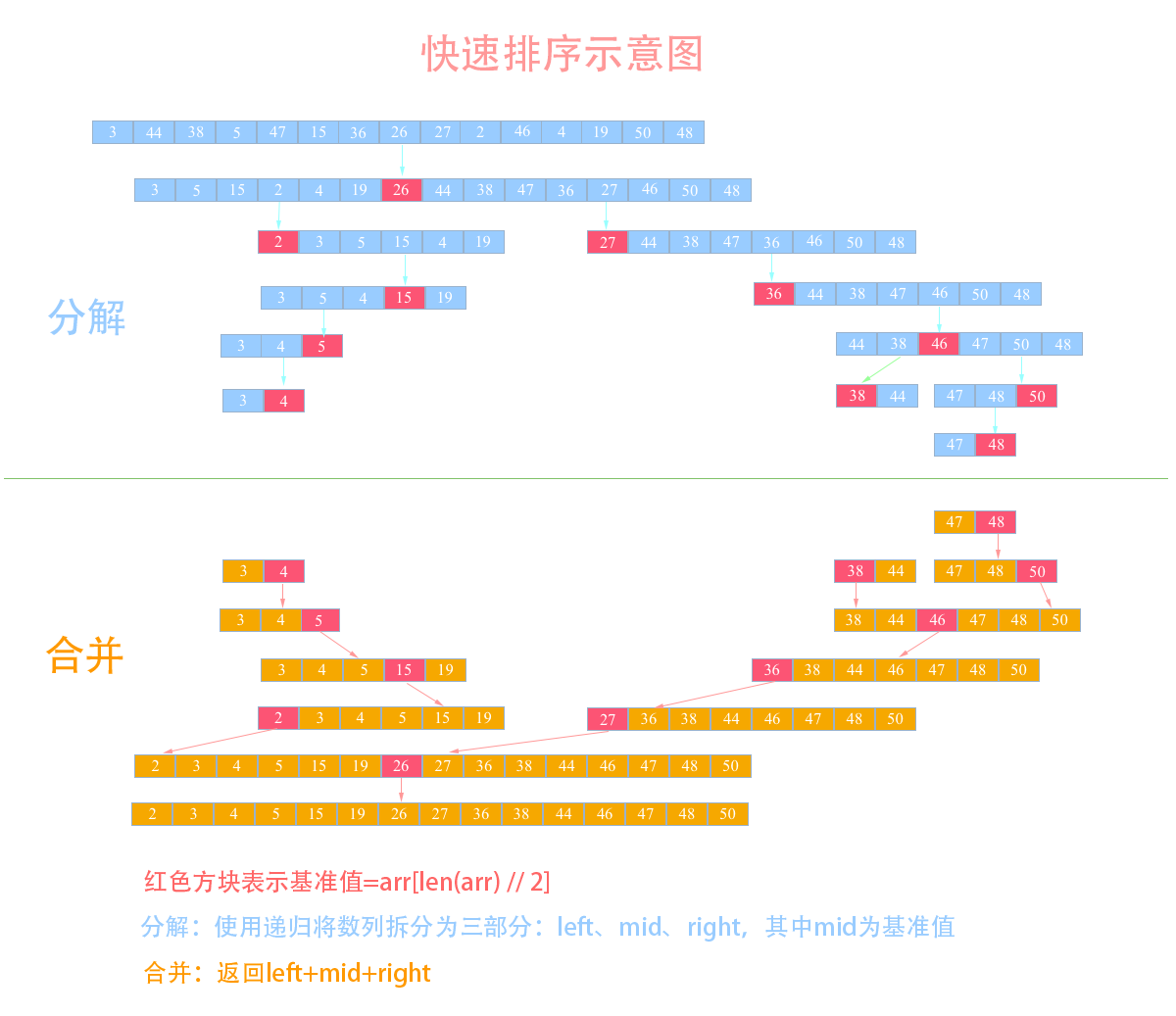
举个例子,假设我现在有一个数列需要使用快排来排序:{3, 44, 38, 5, 47, 15, 36, 26, 27, 2, 46, 4, 19, 50, 48},我们来看看使用快排的详细步骤:
- 选取中间的26作为基准值(基准值可以随便选)
- 数列从第一个元素3开始和基准值26进行比较,小于基准值,那么将它放入左边的分区中,第二个元素44比基准值26大,把它放入右边的分区中,依次类推就得到下图中的第二列。
- 然后依次对左右两个分区进行再分区,得到下图中的第三列,依次往下,直到最后只有一个元素
- 分解完成再一层一层返回,返回规则是:左边分区+基准值+右边分区
缺点 就是对于小规模的数据集性能不是很好。可能有人认为可以忽略这个缺点不计,因为大多数排序都只要考虑大规模的适应性就行了。但是快速排序算法使用了分治技术,最终来说大的数据集都要分为小的数据集来进行处理,所以快排分解到最后几层性能不是很好,所以我们就可以使用扬长避短的策略去优化快排:
- 先使用快排对数据集进行排序,此时的数据集已经达到了基本有序的状态
- 然后当分区的规模达到一定小时,便停止快速排序算法,而是改用插入排序,因为我们之前讲过插入排序在对基本有序的数据集排序有着接近线性的复杂度,性能比较好。
模拟面试
面试官:你了解快排吗?
你:略知一二
面试官:那你讲讲快排的算法思想吧
你:快排基本思想是:从数据集中选取一个基准,然后让数据集的每个元素和基准值比较,小于基准值的元素放入左边分区大于基准值的元素放入右边分区,最后以左右两边分区为新的数据集进行递归分区,直到只剩一个元素。
面试官:快排有什么优点,有什么缺点?
你:分治思想的排序在处理大数据集量时效果比较好,小数据集性能差些。
面试官:那该如何优化?
你:对大规模数据集进行快排,当分区的规模达到一定小时改用插入排序,插入排序在小数据规模时排序性能较好。
面试官:那你能手写一个快排吗?
一行代码实现快速排序
quick_sort = lambda array: array if len(array) <= 1 else quick_sort([item for item in array[1:] if item <= array[0]]) + [array[0]] + quick_sort([item for item in array[1:] if item > array[0]])
函数版
def quick_sort(arr):
if len(arr) < 2:
return arr
mid = arr[len(arr) // 2] # 选取基准,随便选哪个都可以,选中间的便于理解
left, right = [], [] # 定义基准值左右两个数列
arr.remove(mid) # 从原始数组中移除基准值
for item in arr:
if item >= mid: # 大于基准值放右边
right.append(item)
else:
left.append(item) # 小于基准值放左边
return quick_sort(left) + [mid] + quick_sort(right) # 使用迭代进行比较
二分查找算法
二分查找算法,是常见的搜索算法之一,适用于有序的序列,通过将序列不断的对折分为区间,从而确定查找值是否存在,优点是速度快。
首先,假设表中元素是按升序排列,将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成功;否则利用中间位置记录将表分成前、后两个子表,如果中间位置记录的关键字大于查找关键字,则进一步查找前一子表,否则进一步查找后一子表。重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功。
使用python递归实现其算法:
def binary_search(items: list, item: str) -> float:
if not len(items):
return False
if item > items[-1]:
return False
elif item < items[0]:
return False
n = len(items) // 2
if items[n] == item:
return True
else:
if items[n] < item:
return binary_search(items[n:], item)
else:
return binary_search(items[:n], item)二分查找是应用在数据量较大的场景中,如一些图片的RGB数组操作中,典型的是在滑块验证中使用二分法来确定最佳距离。
def match(self, target, template):
img_rgb = cv2.imread(target)
img_gray = cv2.cvtColor(img_rgb, cv2.COLOR_BGR2GRAY)
template = cv2.imread(template,0)
run = 1
w, h = template.shape[::-1]
print(w, h)
res = cv2.matchTemplate(img_gray,template,cv2.TM_CCOEFF_NORMED)
# 使用二分法查找阈值的精确值
L = 0
R = 1
while run < 20:
run += 1
threshold = (R + L) / 2
print(threshold)
if threshold < 0:
print('Error')
return None
loc = np.where( res >= threshold)
print(len(loc[1]))
if len(loc[1]) > 1:
L += (R - L) / 2
elif len(loc[1]) == 1:
print('目标区域起点x坐标为:%d' % loc[1][0])
break
elif len(loc[1]) < 1:
R -= (R - L) / 2
for pt in zip(*loc[::-1]):
cv2.rectangle(img_rgb, pt, (pt[0] + w, pt[1] + h), (7, 279, 151), 2)
cv2.imshow('Dectected', img_rgb)
cv2.waitKey(0)
cv2.destroyAllWindows()
return loc[1][0]















 113
113











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









