







pytorchOCR之PAN
主要思想
这篇文章主要是基于一个聚类的思想,将每一个单独的文本看做是一类。文章借鉴了CornerNet 中的思想,为每个像素点预测一个四维的向量。文本kernel中像素点的四维向量的均值,作为一个聚类中心,于是属于该类中心的像素的四维向量与聚类中心四维向量的距离应该尽可能小,并且每个聚类中心四维向量距离应该尽可能大。
模型架构

本文主要创新点在于提出了两个模块,FPEM和FFM,以及通过训练一个聚类的思想的四维相似向量。最后依旧通过相似向量聚合文本像素得到文本框。
FPEM

这里也很明显通过上采样和下采样,不断融合相邻的特征图,参见ptocr/model/head/det_FPEM_FFM_Head.py的FPEM类。
FFM

FFM就是将FPEM中得到的每个尺度的特征图,相同大小的特征图相加,进一步融合特征。最终将每个尺度特征图插值到同一大小进行concat,就得到最后的分割预测图。,参见ptocr/model/head/det_FPEM_FFM_Head.py的FFM类。
loss
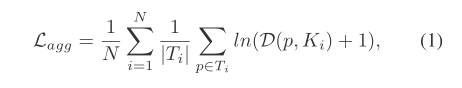
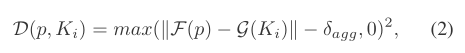
F
(
p
)
F(p)
F(p)代表代表像素p的四维向量,
g
(
k
i
)
g(k_i)
g(ki)代表第
k
i
k_i
ki个kernel的四维向量(这里的四维向量为属于kernel向量的像素的四维向量的均值)。两者求二范数减去一个实验定值
δ
a
g
g
δ_{agg}
δagg并和0作比较求最大。当像素p和kernel的四维向量越相似,公式二越趋向于0,代入公式1同样趋向于0。所以越相似loss越小
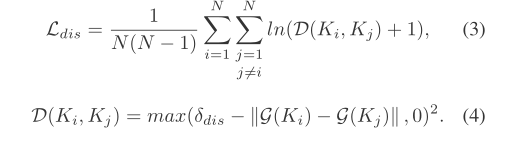
g
(
k
i
)
g(k_i)
g(ki)和
g
(
k
j
)
g(k_j)
g(kj)分别为第
k
i
k_i
ki和
k
j
k_j
kj个kernel的四维向量,
δ
d
i
s
δ_{dis}
δdis为实验常数。由公式4可知,当两者的四维向量越不相似,两者的范数越大,则
δ
d
i
s
−
∣
∣
g
(
k
i
)
−
g
(
k
j
)
∣
∣
δ_{dis}-||g(k_i)-g(k_j)||
δdis−∣∣g(ki)−g(kj)∣∣趋向于0或小于0,则整个式子趋向于0.代入公式3也趋向于0,所以kernel之间越不相似,loss越小。
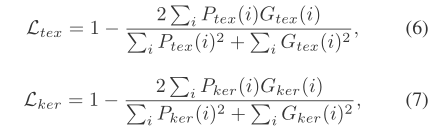
kernel和text的loss为dice loss,用作分割。
最终总的loss如下:
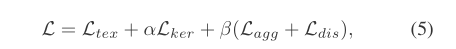
所有loss的代码在ptocr/model/loss/basical_loss.py,对应Agg_loss,Dis_loss,DiceLoss.
像素聚合
像素聚合和pse区别不大,只是加入了一个相似向量之间距离的约束,论文中设定了与kernel四维向量距离小于6的像素进行聚合。
说明:文中图均来自论文















 916
916











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









