







【深度模型】OpenVoice: 多才多艺的即时语音克隆
目录
论文信息
OpenVoice: 多才多艺的即时语音克隆

https://arxiv.org/abs/2312.01479
摘要
OpenVoice是一种多才多艺的即时语音克隆方法,它只需要来自参考说话者的短音频剪辑就能复制他们的声音,并在多种语言中生成语音。这项技术在语音风格控制和零样本跨语言语音克隆方面取得了显著进展。与传统方法相比,OpenVoice在计算效率上也有显著提升,成本远低于市面上的API,同时提供了更好的性能。为了推动该领域的研究,研究者们已经将源代码和训练好的模型公开,并在演示网站上提供了定性结果。
研究背景
即时语音克隆(IVC)是文本到语音(TTS)合成的一个分支,它允许TTS模型在不需要对参考说话者进行额外训练的情况下复制其声音。这种技术在媒体内容创作、定制聊天机器人和人机或大型语言模型之间的多模态交互等实际应用中具有巨大价值。尽管之前的研究已经取得了一些进展,但现有方法在灵活控制语音风格(如情感、口音、节奏、停顿和语调)方面存在限制,并且在跨语言语音克隆方面需要大量的多语言、多说话者数据集。
问题与挑战
- 灵活的语音风格控制:现有方法无法在克隆后灵活操控语音风格。
- 零样本跨语言语音克隆:现有方法通常需要针对所有语言的大规模多说话者多语言(MSML)数据集,而OpenVoice能够在没有该语言的大规模训练数据的情况下克隆声音。
- 实时推理的超快速度:在不降低质量的前提下实现实时推理,这对于大规模商业生产环境至关重要。
如何解决
OpenVoice通过将语音的各个组成部分(如语言、音色和其他重要的声音特征)尽可能解耦来解决上述问题。这种设计允许在不标记MSML训练集中的任何语音风格的情况下,灵活操控个别语音风格和语言类型。此外,OpenVoice避免了自回归或扩散组件,以加快推理速度。
创新点
- 解耦框架:将语音风格和语言控制与音色克隆分离,这是OpenVoice的核心设计原则。
- 零样本跨语言能力:与需要所有语言数据的现有方法不同,OpenVoice能够泛化到MSML训练集之外的完全未见过的语言。
- 计算效率:由于结构解耦,减少了对模型大小和计算复杂性的需求,避免了使用大型模型来学习所有内容。
算法模型
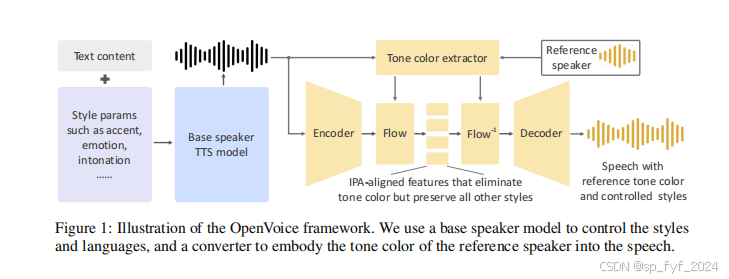
OpenVoice主要由两个组件构成:基础说话者TTS模型和音色转换器。
-
基础说话者TTS模型:可以是单说话者或多说话者模型,允许控制风格参数(如情感、口音、节奏、停顿和语调)和语言。该模型生成的声音被传递给音色转换器,后者将基础说话者的音色转换为参考说话者的音色。
-
音色转换器:是一个编码器-解码器结构,中间有一个可逆的归一化流。编码器是一个一维卷积神经网络,它接受X(LI, SI, CI)的短时傅里叶变换谱作为输入。音色提取器是一个简单的二维卷积神经网络,它处理输入声音的mel频谱图,并输出一个编码音色信息的特征向量。
实验效果
OpenVoice在多个方面展现了出色的性能:
-
音色克隆的准确性:OpenVoice能够准确克隆参考说话者的音色,并在多种语言和口音中生成语音。
-
对语音风格的灵活控制:音色转换器能够仅修改音色并保留所有其他风格和声音属性,使得通过简单地操控基础说话者TTS模型就能控制语音风格。
-
跨语言语音克隆的便捷性:OpenVoice能够在没有使用任何大规模说话者数据的情况下实现近零样本跨语言语音克隆。
-
快速推理和低成本:OpenVoice是一个前馈结构,没有任何自回归组件,因此实现了非常高的推理速度。实验表明,优化后的OpenVoice能够在单个A10G GPU上实现12倍实时性能,即生成一秒语音只需85毫秒。
推荐阅读指数:★★★★☆
推荐理由:
- 创新性:OpenVoice提出了一种新颖的解耦框架,将音色克隆与语音风格和语言控制分离,这在语音合成领域是一个重要的创新。
- 实用性:该技术在多个实际应用中具有潜在价值,如媒体内容创作、定制聊天机器人等。
- 开放性:研究者们公开了源代码和训练好的模型,这有助于推动该领域的进一步研究和应用。
- 性能:OpenVoice在音色克隆的准确性、对语音风格的灵活控制以及跨语言语音克隆的便捷性方面展现了出色的性能。
- 效率:与市面上的API相比,OpenVoice在计算效率上有显著提升,成本更低。
代码
https://github.com/myshell-ai/OpenVoice?tab=readme-ov-file
Voice Style Control Demo
import os
import torch
from openvoice import se_extractor
from openvoice.api import BaseSpeakerTTS, ToneColorConverter
Initialization
ckpt_base = 'checkpoints/base_speakers/EN'
ckpt_converter = 'checkpoints/converter'
device="cuda:0" if torch.cuda.is_available() else "cpu"
output_dir = 'outputs'
base_speaker_tts = BaseSpeakerTTS(f'{ckpt_base}/config.json', device=device)
base_speaker_tts.load_ckpt(f'{ckpt_base}/checkpoint.pth')
tone_color_converter = ToneColorConverter(f'{ckpt_converter}/config.json', device=device)
tone_color_converter.load_ckpt(f'{ckpt_converter}/checkpoint.pth')
os.makedirs(output_dir, exist_ok=True)
Obtain Tone Color Embedding
The source_se is the tone color embedding of the base speaker. It is an average of multiple sentences generated by the base speaker. We directly provide the result here but the readers feel free to extract source_se by themselves.
source_se = torch.load(f'{ckpt_base}/en_default_se.pth').to(device)
The reference_speaker.mp3 below points to the short audio clip of the reference whose voice we want to clone. We provide an example here. If you use your own reference speakers, please make sure each speaker has a unique filename. The se_extractor will save the targeted_se using the filename of the audio and will not automatically overwrite.
reference_speaker = 'resources/example_reference.mp3' # This is the voice you want to clone
target_se, audio_name = se_extractor.get_se(reference_speaker, tone_color_converter, target_dir='processed', vad=True)
Inference
save_path = f'{output_dir}/output_en_default.wav'
# Run the base speaker tts
text = "This audio is generated by OpenVoice."
src_path = f'{output_dir}/tmp.wav'
base_speaker_tts.tts(text, src_path, speaker='default', language='English', speed=1.0)
# Run the tone color converter
encode_message = "@MyShell"
tone_color_converter.convert(
audio_src_path=src_path,
src_se=source_se,
tgt_se=target_se,
output_path=save_path,
message=encode_message)
Try with different styles and speed. The style can be controlled by the speaker parameter in the base_speaker_tts.tts method. Available choices: friendly, cheerful, excited, sad, angry, terrified, shouting, whispering. Note that the tone color embedding need to be updated. The speed can be controlled by the speed parameter. Let's try whispering with speed 0.9.
source_se = torch.load(f'{ckpt_base}/en_style_se.pth').to(device)
save_path = f'{output_dir}/output_whispering.wav'
# Run the base speaker tts
text = "This audio is generated by OpenVoice."
src_path = f'{output_dir}/tmp.wav'
base_speaker_tts.tts(text, src_path, speaker='whispering', language='English', speed=0.9)
# Run the tone color converter
encode_message = "@MyShell"
tone_color_converter.convert(
audio_src_path=src_path,
src_se=source_se,
tgt_se=target_se,
output_path=save_path,
message=encode_message)
Try with different languages. OpenVoice can achieve multi-lingual voice cloning by simply replace the base speaker. We provide an example with a Chinese base speaker here and we encourage the readers to try demo_part2.ipynb for a detailed demo.
ckpt_base = 'checkpoints/base_speakers/ZH'
base_speaker_tts = BaseSpeakerTTS(f'{ckpt_base}/config.json', device=device)
base_speaker_tts.load_ckpt(f'{ckpt_base}/checkpoint.pth')
source_se = torch.load(f'{ckpt_base}/zh_default_se.pth').to(device)
save_path = f'{output_dir}/output_chinese.wav'
# Run the base speaker tts
text = "今天天气真好,我们一起出去吃饭吧。"
src_path = f'{output_dir}/tmp.wav'
base_speaker_tts.tts(text, src_path, speaker='default', language='Chinese', speed=1.0)
# Run the tone color converter
encode_message = "@MyShell"
tone_color_converter.convert(
audio_src_path=src_path,
src_se=source_se,
tgt_se=target_se,
output_path=save_path,
message=encode_message)
Tech for good. For people who will deploy OpenVoice for public usage: We offer you the option to add watermark to avoid potential misuse. Please see the ToneColorConverter class. MyShell reserves the ability to detect whether an audio is generated by OpenVoice, no matter whether the watermark is added or not.
后记
如果您对我的博客内容感兴趣,欢迎三连击 ( 点赞、收藏和关注 )和留下您的评论,我将持续为您带来计算机人工智能前沿技术(尤其是AI相关的大语言模型,深度学习和计算机视觉相关方向)最新学术论文及工程实践方面的内容分享,助力您更快更准更系统地了解 AI前沿技术。



















 541
541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











