






-
模型评估的方法
留出法
留出法是将原数据集分成互斥的两组,一组作为训练集,另一组作为测试集
交叉验证发
交叉验证(cross-validation 简称cv)将数据集分为k等份,对于每一份数据集,其中k-1份用作训练集,单独的那一份用作验证集。
通常情况下,留一法对模型的评估可能会不准确,一般采用xgboost.cv可以进行交叉验证
以下基于kaggle的heart-disease数据进行交叉验证
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split,StratifiedKFold,train_test_split,GridSearchCV
from sklearn.metrics import accuracy_score, confusion_matrix, mean_squared_error,roc_auc_score
from xgboost import plot_importance
from matplotlib import pyplot as plt
import xgboost as xgb
dataset=pd.read_csv('heart.csv')
dataset.head(5)
数据前五行如下:
利用straightkfold做交叉验证输出混淆矩阵
StratifiedKFold用法类似Kfold,但是他是分层采样,确保训练集,测试集中各类别样本的比例与原始数据集中相同
rng=np.random.RandomState(31337)
kf=StratifiedKFold(n_splits=3,shuffle=True,random_state=rng)#采用三折交叉验证
for train_index,test_index in kf.split(X,Y):
xgb_model = xgb.XGBClassifier().fit(X.iloc[train_index], Y.iloc[train_index])
predictions = xgb_model.predict(X.iloc[test_index])
actuals = Y.iloc[test_index]
print(confusion_matrix(actuals, predictions))
输出混淆矩阵
[[36 10]
[ 3 52]]
[[33 13]
[13 42]]
[[35 11]
[10 45]]
利用xgb.cv找出最优的树
#利用train_test_split方法,将X,y随机划分问,训练集(X_train),训练集标签(X_test),测试卷(y_train),
#测试集标签(y_test),训练集:测试集=7:3的
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.3, random_state=42)
#xgboost可以加载libsvm格式的文本数据,加载的数据格式可以为numpy的二维数组和xgboost的二进制的缓存文件。加载的数据存储在对象dmatrix中。
xgtrain = xgb.DMatrix(X_train, label=y_train)
clf = xgb.XGBClassifier(missing=9999999999,
max_depth = 7,
n_estimators=80,
learning_rate=0.1,
nthread=4,
subsample=1.0,
colsample_bytree=0.5,
min_child_weight = 3,
seed=1301)
xgb_param = clf.get_xgb_params()
#do cross validation
print ('Start cross validation')
cvresult = xgb.cv(xgb_param, xgtrain, num_boost_round=5000, nfold=5, metrics=['auc'],
early_stopping_rounds=50, stratified=True, seed=1301)
#交叉验证后最好的树
print('Best number of trees = {}'.format(cvresult.shape[0]))
clf.set_params(n_estimators=cvresult.shape[0])#把clf的参数设置成最好的树对应的参数
print('Fit on the trainingsdata')
clf.fit(X_train, y_train, eval_metric='auc')#训练clf
print('Overall AUC:', roc_auc_score(y_train, clf.predict_proba(X_train)[:,1]))#训练auc
print('Predict the probabilities based on features in the test set')
pred = clf.predict_proba(X_test, ntree_limit=cvresult.shape[0])
print('Fit on the testingsdata')
print('Overall AUC:', roc_auc_score(y_test, clf.predict_proba(X_test)[:,1]))#测试auc
#测试集上的概率
submission= pd.DataFrame({"ID":X_test.index, "TARGET":pred[:,1]})
submission.to_csv("submission.csv", index=False)
#测试集分类结果的预测
print('Fit on the testingsdata')
print('Overall AUC:', roc_auc_score(y_test, clf.predict(X_test)))#测试auc
其中cvresult的结果为
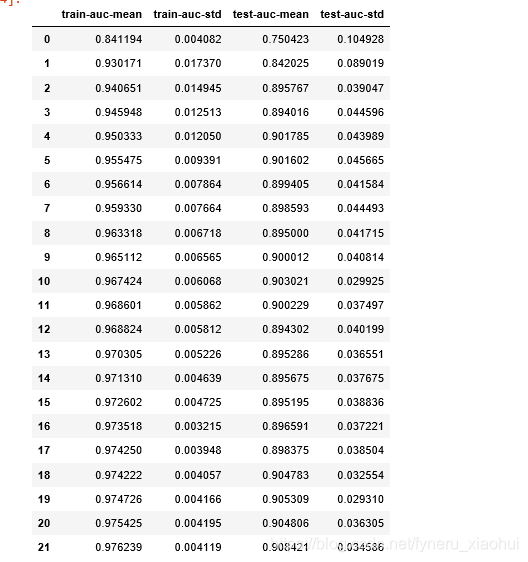
输出的结果如下
Start cross validation
Best number of trees = 22
Fit on the trainingsdata
Overall AUC: 0.9752577319587629
Predict the probabilities based on features in the test set
Fit on the testingsdata using predict_proba
Overall AUC: 0.888780487804878
Fit on the testingsdata using predict
Overall AUC: 0.8102439024390243

















 466
466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









