






MLR(mixed logistic regression)算法
参考https://zhuanlan.zhihu.com/p/77798409?utm_source=wechat_session
盖坤ppt : https://wenku.baidu.com/view/b0e8976f2b160b4e767fcfdc.html
原文:《Learning Piece-wise Linear Models from Large Scale Data for Ad Click Prediction》
MLR算法创新地提出并实现了直接在原始空间学习特征之间的非线性关系
MLR算法模型,这是一篇来自阿里盖坤团队的方案(LS-PLM),发表于2017年,但实际在2012年就已经提出并应用于实际业务中(膜拜ing),当时主流仍然是我们上一篇提到过的的LR模型,而本文作者创新性地提出了MLR(mixed logistic regression, 混合逻辑斯特回归)算法,引领了广告领域CTR预估算法的全新升级。
1.背景
CTR预估(click-through-rate prediction)是广告行业比较常见的问题,根据用户的历史行为来判断用户对广告点击的可能性。在常见工业场景中,该问题的输入往往是数以万计的稀疏特征向量,在进行特征交叉后会维数会更高,比较常见的就是采用逻辑回归模型加一些正则化,因为逻辑回归模型计算开销小且容易实现并行。之前提到的facebook的一篇论文(LR+GBDT)中先用树模型做分类之后再加一个逻辑回归模型,最后得出效果出奇的好,应该也是工业界比较常用的方法,同时树模型的选择或者说是再构造特征的特性也逐渐被大家所关注。另一种比较有效的就是因子分解模型系列,包括FM及其的其他变种,它们的主要思想就是构造交叉特征或者是二阶的特征来一起进行训练。
作者主要提出了一种piece-wise的线性模型,并且给出了其在大规模数据上的训练算法,称之为LS-PLM(Large Scale Piecewise Linear Model),LS-PLM采用了分治的思想,先分成几个局部再用线性模型拟合,这两部都采用监督学习的方式,来优化总体的预测误差,总的来说有以下优势:
- 端到端的非线性学习
从模型端自动挖掘数据中蕴藏的非线性模式,省去了大量的人工特征设计,这 使得MLR算法可以端到端地完成训练,在不同场景中的迁移和应用非常轻松。通过分区来达到拟合非线性函数的效果; - 可伸缩性(scalability)
与逻辑回归模型相似,都可以很好的处理复杂的样本与高维的特征,并且做到了分布式并行; - 稀疏性
对于在线学习系统,模型的稀疏性较为重要,所以采用了 L 1 L_1 L1 和 L 2 L_2 L2 正则化,模型的学习和在线预测性能更好。当然,目标函数非凸非光滑为算法优带来了新的挑战。
MLR方法
思想;分而治之,由很多个LR模型组合而成。用分片线性模式来拟合高维空间的非线性模式,形式化表述如下:
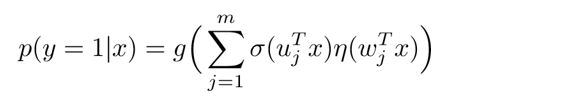
当我们将softmax函数作为分割函数
σ
(
x
)
\sigma(x)
σ(x),将sigma函数作为拟合函数
η
(
x
)
\eta(x)
η(x)的时候,该模型为:
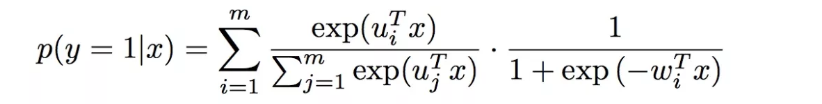
目标损失函数为
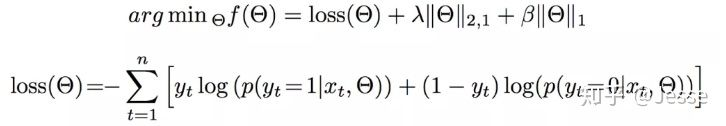
同时MLR还引入了结构化先验、分组稀疏、线性偏置、模型级联、增量训练、Common Feature Trick来提升模型性能。
结构化先验
MLR中非常重要的就是如何划分原始特征空间。
通过引入结构化先验,我们使用用户特征来划分特征空间,使用广告特征来进行基分类器的训练,减小了模型的探索空间,收敛更容易。
同时,这也是符合我们认知的:不同的人群具有聚类特性,同一类人群具有类似的广告点击偏好。
增量训练
实验证明,MLR利用结构先验(用户特征进行聚类,广告特征进行分类)进行pretrain,然后再增量进行全空间参数寻优训练,会使得收敛步数更少,收敛更稳定。

模型级联
盖坤在PPT讲解到,MLR支持与LR的级联式训练。有点类似于Wide & Deep,一些强Feature配置成级联形式能够提高模型的收敛性。例如典型的应用方法是:以统计反馈类特征构建第一层模型,输出FBctr级联到第二级大规模稀疏ID特征中去,能得到更好的提升效果。
此外盖坤还提出了带

代码实现
import numpy as np
import pandas as pd
import time
import tensorflow as tf
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import roc_auc_score
#数据处理
def data_concat(train,test):
train['type']=1
test['type'] =2
all_columns=['age','workclass','fnlwgt','education','education-num','marital-status',
'occupation','relationship','race','sex','capital-gain','capital-loss',
'hours-per-week','native-country','label','type']
all_data=pd.concat([train,test],axis=0)
all_data.columns=all_columns
return all_data
def data_processing(train,test):
df=data_concat(train,test)
continus_columns=['age','fnlwgt','education-num','capital-gain','capital-loss','hours-per-week']
category_columns=['workclass','education','marital-status','occupation','relationship','race','sex','native-country']
#类别变量做one_hot_encoding
df=pd.get_dummies(df,columns=category_columns)
#连续数据标准化
for col in continus_columns:
ss=StandardScaler()
df[col]=ss.fit_transform(df[[col]])
df['label']=df['label'].apply(lambda x: 1 if x.strip()=='>50K' else 0)
return df
os.getcwd()
train_data=pd.read_table(r'E:/996/推荐系统/DATA/recsys-data/MLR/adult.data',header=None,delimiter=',')
test_data=pd.read_table(r'E:/996/推荐系统/DATA/recsys-data/MLR/adult.txt',header=None,delimiter=',')
test_data[14]=test_data[14].apply(lambda x: x[:-1])
df= data_processing(train_data,test_data)
train_data=df[df['type']==1].drop(['type'],axis=1)
test_data=df[df['type']==2].drop(['type'],axis=1)
#mlr模型训练及测试
print(tf.__path__)
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
def train_and_test(train_data,test_data,m=2,learning_rate=0.1):
#m=2#分片参数为2
#learning_rate#学习率为0.3
train_y= train_data['label']
train_x=train_data.drop('label',axis=1)
test_y= test_data['label']
test_x=test_data.drop('label',axis=1)
x=tf.placeholder(tf.float32,shape=[None,108])#特征向量维度为108
y=tf.placeholder(tf.float32,shape=[None])
u=tf.Variable(tf.random_normal([108,m],0.0,0.5),name='u')
w=tf.Variable(tf.random_normal([108,m],0.0,0.5),name='w')
U=tf.matmul(x,u)
p1=tf.nn.softmax(U)
W=tf.matmul(x,w)
p2=tf.nn.softmax(W)
pred=tf.reduce_sum(tf.multiply(p1,p2),axis=1)
cost1=tf.reduce_sum(tf.nn.sigmoid_cross_entropy_with_logits(logits=pred,labels=y))
cost=tf.add_n([cost1])
train_opt=tf.train.FtrlOptimizer(learning_rate).minimize(cost)
time_start=time.time()
#会话
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())#初始化
train_dict={x:train_x,y:train_y}
for epoch in range(500):
_,cost_train,pred_train=sess.run([train_opt,cost,pred],feed_dict=train_dict)
train_auc=roc_auc_score(train_y,pred_train)
time_end=time.time()
test_dict={x:test_x,y:test_y}
result=[]
if epoch %100==0:
_,cost_test,pred_test=sess.run([train_opt,cost,pred],feed_dict=test_dict)
test_auc=roc_auc_score(test_y,pred_test)
print("epoch:%d,time:%d,train_auc:%f,test_auc:%f"%(epoch,(time_end-time_start),train_auc,test_auc))
result.append([epoch,pred_test,train_auc,test_auc])
return result
train_and_test(train_data,test_data,m=2,learning_rate=0.1)

















 643
643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









