






这部分是选学内容,补充阅读:往年赛事方案分析与常用时序模型补充
一.往年天池赛——2022江苏气象AI算法挑战赛-AI助力强对流天气预报
赛事介绍:
强对流天气是气象学上所指发生突然、移动迅速、天气剧烈、破坏力强的中小尺度灾害性天气,通常伴有雷雨大风、冰雹、龙卷风、短时强降水等。由于空间尺度小、生命史短暂、并带有明显的突发性,就目前的预报方法和技术水平而言,对其进行“定点、定量、定时”的预报难度很大。江苏东部临海,地势平坦,域内江河湖泊水网交织,处于亚热带和暖温带的气候过渡地带,易积聚不稳定能量,导致强对流频发,对社会基础设施、公众生命安全产生较大威胁。因此,江苏地区的强对流天气预报一直是短临预报业务工作中的重点与难点。近年来,伴随计算机技术的不断发展,AI技术被广泛应用于短临天气预报中。
数据集详解:
该比赛采用的数据集为2019-2021年4-9月江苏省气象雷达及自动站观测要素数据,数据集由江苏省气象台制作,以灰度图形式存储(格式为PNG)。该比赛是一项时间序列预测大赛,需要基于过去已发生的气象时间序列数据,也就是过去发生的气象雷达影像和自动站观测到的气象要素结构化数据,预测未来两小时的气象雷达影像和自动站观测到的气象要素结构化数据。
【气象雷达数据集】
气象雷达数据集是雷达回波数据的时间序列,其物理含义为3公里等高面的基本反射率因子。大气中的水滴含量越高,则雷达基本反射率越高。本数据集是对江苏多部S波段气象雷达质量控制及组网拼图后得到的,覆盖整个江苏省区域面积。数据取值范围为0-70(单位:dBZ),水平分辨率为0.01°(约1公里),时间分辨率为6分钟,单时次数据(即单张图片)的网格尺寸为480×560像素。
【自动站观测要素数据集】
自动站观测要素数据集包含降水和平均风要素,通过将江苏及其周边地区气象自动观测站数据插值到均匀网格后得到。其中降水要素为自动站6分钟累积降水量,即截至当前时刻6分钟内降水观测量的累加值,取值范围为0-10(单位:mm)。平均风要素由自动站观测得到,取值范围为0-35(单位m/s)。数据集的水平分辨率为0.01°(约1公里),时间分辨率为6分钟,单时次数据(即单张图片)的网格数为480×560像素。
方案解析:
1.改进之后的Unet模型:
模型: SmaAt-Unet, 链接为: https://arxiv.org/abs/2007.04417。 SmaAt-Unet模型是由 Trebing 等提出的降水短临预报模型,模型基于原始UNet模型做了一定的修改,原始UNet模型效果较好,但模型参数量大, 需要消耗非常多的计算资源, 同时, 在本次模型里面又使用了深度可分离卷积,可以使用更少的数学运算和更少的参数,对硬件要求降低同时也能达到复杂模型近似的效果。此外, 作者还将其中的卷积操作替换为attention操作, 以放大重要特征(针对此次比赛也就是强回波区,强降水,大风等重要特征)并抑制相应图像尺度上不重要的特征。
SmaAt-Unet的基本架构如下所示:

SmaAt-Unet的伪代码如下:
import torch
import torch.nn as nn
class SmaAt_UNet(nn.Module):
def __init__(self, n_channels, n_classes, kernels_per_layer=2, bilinear=True, reduction_ratio=16):
super(SmaAt_UNet, self).__init__()
# 在此处定义编码器、解码器、注意力模块等
def forward(self, x):
# 定义前向传播流程
return prediction数据: 雷达回波,降水,风速三个特征之间有强相关,所以将以上三种数据作为三种特征一起输入模型,让模型学习其中的关系。因此,首先将雷达回波,降水数据,风速数据依据每次天气过程头20张一起读取,组成(60,480,560)的输入数据,然后再与该次天气过程的后20张目标数据进行对比,计算损失函数。
损失函数: 使用MAE+MSE混合的函数
均方误差(Mean Squared Error, MSE)和平均绝对误差(Mean Absolute Error, MAE)都是常用的损失函数。MSE 是预测值与真实值之间差值平方的平均值。MAE 是预测值与真实值之间差值绝对值的平均值。
2.Conv-TT-LSTM模型: https://tianchi.aliyun.com/forum/post/408834
模型:Conv-TT-LSTM
Conv-TT-LSTM(Convolutional Tensor Train LSTM)是一种结合了卷积神经网络(CNN)和长短期记忆网络(LSTM)特性的深度学习模型,旨在处理具有时空相关性的序列数据。

一个简化的 Conv-TT-LSTM 模型的 PyTorch 实现示例:
import torch
import torch.nn as nn
from tensor_train import TTLayer # 假设这是一个自定义或第三方库提供的 TT 层实现
class ConvTT_LSTM(nn.Module):
def __init__(self, input_channels, hidden_channels, num_layers, tt_rank):
super(ConvTT_LSTM, self).__init__()
self.input_channels = input_channels
self.hidden_channels = hidden_channels
self.num_layers = num_layers
self.conv = nn.Sequential(
nn.Conv2d(input_channels, hidden_channels, kernel_size=3, padding=1),
nn.ReLU()
)
self.tt_lstm = nn.ModuleList([
TTLayer(hidden_channels, hidden_channels, rank=tt_rank)
for _ in range(num_layers)
])
self.fc = nn.Linear(hidden_channels, 1) # 假设最后输出为单个数值
def forward(self, x):
x = self.conv(x)
h = x
for layer in self.tt_lstm:
h = layer(h)
x = self.fc(h.squeeze())
return x
# 创建 Conv-TT-LSTM 实例
input_channels = 3 # 输入通道数
hidden_channels = 64 # 隐藏层通道数
num_layers = 2 # LSTM 层数
tt_rank = 4 # Tensor Train 的秩
model = ConvTT_LSTM(input_channels, hidden_channels, num_layers, tt_rank)
# 假设输入数据形状为 (batch_size, channels, height, width)
input_data = torch.randn(1, input_channels, 64, 64)
output = model(input_data)
print(output.shape)损失函数: 加权的MSE, 根据值不同需设置不同的权重
针对数据分布极不平衡的特点,结合赛事方给出的分级设置,我们采用分级加权MSE作为训练损失函数,定义如下:
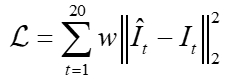
其中权重w为分级函数,对应赛事方给出四个评估分级,例如雷达为0-30,30-40,40-50,50-70四个分级,我们设置权重分别为1,5,10,50。特别地,对于降水要素除采用单帧MSE损失外,我们还额外计算了小时累积降水MSE损失。
3.模型:SimVP + MIM,分别抽取空间和时序上的特征。
此为季军比赛攻略: https://tianchi.aliyun.com/forum/post/408250
SimVP (Simple but Effective Video Prediction) 是一种用于视频预测的轻量级深度学习模型。
一个简化的 SimVP 模型的 PyTorch 实现示例:
import torch
import torch.nn as nn
class ConvLSTMCell(nn.Module):
def __init__(self, input_dim, hidden_dim, kernel_size, bias):
super(ConvLSTMCell, self).__init__()
self.input_dim = input_dim
self.hidden_dim = hidden_dim
self.kernel_size = kernel_size
self.padding = kernel_size // 2
self.bias = bias
self.conv = nn.Conv2d(in_channels=self.input_dim + self.hidden_dim,
out_channels=4 * self.hidden_dim,
kernel_size=self.kernel_size,
padding=self.padding,
bias=self.bias)
def forward(self, input_tensor, cur_state):
h_cur, c_cur = cur_state
combined = torch.cat([input_tensor, h_cur], dim=1)
combined_conv = self.conv(combined)
cc_i, cc_f, cc_o, cc_g = torch.split(combined_conv, self.hidden_dim, dim=1)
i = torch.sigmoid(cc_i)
f = torch.sigmoid(cc_f)
o = torch.sigmoid(cc_o)
g = torch.tanh(cc_g)
c_next = f * c_cur + i * g
h_next = o * torch.tanh(c_next)
return h_next, c_next
def init_hidden(self, batch_size, image_size):
height, width = image_size
return (torch.zeros(batch_size, self.hidden_dim, height, width, device=self.conv.weight.device),
torch.zeros(batch_size, self.hidden_dim, height, width, device=self.conv.weight.device))
class SimVP(nn.Module):
def __init__(self, input_dim, hidden_dim, kernel_size, num_layers, bias=True):
super(SimVP, self).__init__()
self._check_kernel_size_consistency(kernel_size)
kernel_size = self._extend_for_multilayer(kernel_size, num_layers)
hidden_dim = self._extend_for_multilayer(hidden_dim, num_layers)
if not len(kernel_size) == len(hidden_dim) == num_layers:
raise ValueError('Inconsistent list length.')
self.cell_list = nn.ModuleList()
for i in range(0, num_layers):
cur_input_dim = input_dim if i == 0 else hidden_dim[i - 1]
self.cell_list.append(ConvLSTMCell(input_dim=cur_input_dim,
hidden_dim=hidden_dim[i],
kernel_size=kernel_size[i],
bias=bias))
def forward(self, input_tensor, hidden_state=None):
b, seq_len, _, h, w = input_tensor.size()
# Initialize hidden states
if hidden_state is None:
hidden_state = self._init_hidden(batch_size=b, image_size=(h, w))
layer_output_list = []
last_state_list = []
seq_output = torch.zeros(b, seq_len, self.hidden_dim[-1], h, w, device=input_tensor.device)
seq_cur = input_tensor
for t in range(seq_len):
cur_layer_input = seq_cur
for i, cell in enumerate(self.cell_list):
output_inner = []
h, c = hidden_state[i]
for j in range(cur_layer_input.size(1)):
h, c = cell(input_tensor=cur_layer_input[:, j, ...], cur_state=[h, c])
output_inner.append(h)
layer_output = torch.stack(output_inner, dim=1)
cur_layer_input = layer_output
layer_output_list.append(layer_output)
last_state_list.append([h, c])
seq_output[:, t, ...] = layer_output[:, -1, ...]
# Return the last state and the sequence of outputs
return seq_output, last_state_list
def _init_hidden(self, batch_size, image_size):
init_states = []
for i in range(self.num_layers):
init_states.append(self.cell_list[i].init_hidden(batch_size, image_size))
return init_states
@staticmethod
def _check_kernel_size_consistency(kernel_size):
if not (isinstance(kernel_size, tuple) or
(isinstance(kernel_size, list) and all([isinstance(elem, tuple) for elem in kernel_size]))):
raise ValueError('`kernel_size` must be tuple or list of tuples')
@staticmethod
def _extend_for_multilayer(param, num_layers):
if not isinstance(param, list):
param = [param] * num_layers
return param
# 创建 SimVP 实例
input_dim = 3 # 输入通道数
hidden_dim = [64, 64] # 每个 ConvLSTM 层的隐藏单元数
kernel_size = (3, 3) # 卷积核大小
num_layers = 2 # ConvLSTM 层数
bias = True # 是否使用偏置项
model = SimVP(input_dim, hidden_dim, kernel_size, num_layers, bias)
# 假设输入数据形状为 (batch_size, seq_length, channels, height, width)
input_data = torch.randn(1, 10, input_dim, 64, 64)
output, last_state = model(input_data)
print(output.shape)MIM(Motion and Intensity Memory)模型是一种用于视频预测的深度学习模型,它结合了卷积神经网络(CNN)和长短期记忆网络(LSTM)的特性,旨在处理视频序列中的时空动态变化。
一个简化的 MIM 模型的 PyTorch 实现示例:
import torch
import torch.nn as nn
class MotionIntensityMemory(nn.Module):
def __init__(self, input_channels, hidden_channels, num_layers):
super(MotionIntensityMemory, self).__init__()
self.input_channels = input_channels
self.hidden_channels = hidden_channels
self.num_layers = num_layers
# Motion Stream
self.motion_stream = nn.Sequential(
nn.Conv2d(input_channels, hidden_channels, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(hidden_channels, hidden_channels, kernel_size=3, padding=1)
)
# Intensity Stream
self.intensity_stream = nn.Sequential(
nn.Conv2d(input_channels, hidden_channels, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(hidden_channels, hidden_channels, kernel_size=3, padding=1)
)
# LSTM Cells
self.lstm_motion = nn.LSTM(input_size=hidden_channels, hidden_size=hidden_channels, num_layers=num_layers)
self.lstm_intensity = nn.LSTM(input_size=hidden_channels, hidden_size=hidden_channels, num_layers=num_layers)
# Fusion Module
self.fusion_module = nn.Sequential(
nn.Conv2d(hidden_channels * 2, hidden_channels, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(hidden_channels, input_channels, kernel_size=3, padding=1)
)
def forward(self, input_sequence):
batch_size, seq_len, channels, height, width = input_sequence.size()
# 初始化 LSTM 状态
h0_motion = torch.zeros(self.num_layers, batch_size, self.hidden_channels, height, width).to(input_sequence.device)
c0_motion = torch.zeros(self.num_layers, batch_size, self.hidden_channels, height, width).to(input_sequence.device)
h0_intensity = torch.zeros(self.num_layers, batch_size, self.hidden_channels, height, width).to(input_sequence.device)
c0_intensity = torch.zeros(self.num_layers, batch_size, self.hidden_channels, height, width).to(input_sequence.device)
predictions = []
for t in range(seq_len):
frame = input_sequence[:, t, ...]
# 分离流
motion_features = self.motion_stream(frame)
intensity_features = self.intensity_stream(frame)
# 更新 LSTM 状态
lstm_input_motion = motion_features.permute(0, 2, 3, 1).contiguous().view(-1, self.hidden_channels)
lstm_input_intensity = intensity_features.permute(0, 2, 3, 1).contiguous().view(-1, self.hidden_channels)
lstm_output_motion, (h0_motion, c0_motion) = self.lstm_motion(lstm_input_motion, (h0_motion.view(self.num_layers, -1, self.hidden_channels), c0_motion.view(self.num_layers, -1, self.hidden_channels)))
lstm_output_intensity, (h0_intensity, c0_intensity) = self.lstm_intensity(lstm_input_intensity, (h0_intensity.view(self.num_layers, -1, self.hidden_channels), c0_intensity.view(self.num_layers, -1, self.hidden_channels)))
lstm_output_motion = lstm_output_motion.view(batch_size, height, width, self.hidden_channels).permute(0, 3, 1, 2)
lstm_output_intensity = lstm_output_intensity.view(batch_size, height, width, self.hidden_channels).permute(0, 3, 1, 2)
# 融合
fused_features = torch.cat([lstm_output_motion, lstm_output_intensity], dim=1)
prediction = self.fusion_module(fused_features)
predictions.append(prediction)
# 返回预测序列
return torch.stack(predictions, dim=1)
# 创建 MIM 模型实例
input_channels = 3 # 输入通道数
hidden_channels = 64 # 隐藏层通道数
num_layers = 2 # LSTM 层数
model = MotionIntensityMemory(input_channels, hidden_channels, num_layers)
# 假设输入数据形状为 (batch_size, seq_length, channels, height, width)
input_data = torch.randn(1, 10, input_channels, 64, 64)
output = model(input_data)
print(output.shape)二.首届世界科学智能大赛 - AI + 大气科学
赛事介绍:
本次比赛是基于AI的区域天气预测大赛,提供10年的再分析数据,输入历史2个时刻的多个大气变量,输出未来1-5天逐6小时的5个地面变量。
解题思路:
本题任务是预测未来1-5天逐6小时的5个地面变量,属于典型的回归问题,输入数据为历史大气变量信息,输出5个变量结果,分别为2米温度、10米纬向风、10米经向风、平均海平面气压、6小时累积降水。针对这类时间序列预测问题方法比较灵活,传统的时序模型、机器学习、深度学习方法均可以使用。
1、统计策略:使用最近时刻的结果进行均值、中位数、时间衰减等方式直接统计得到未来结果,这种方式比较简单,可以快速得到结果;
2、时序模型:比较常用的方法有指数平滑法、灰色预测模型、ARIMA预测、季节Sarima模型、VAR模型等,仅能刻画序列信息,无法加入其他信息进行训练,比如离散类特征;
3、机器学习模型:常见的为lightgbm、xgboost、catboost,需要构建大量时序相关特征;
4、深度学习模型:常见为rnn、lstm、cnn、transformer这类模型,可以直接输入序列信息,不需要构建大量的人工特征;
基础baseline:
baseline1:统计学习方法baseline
1.导入模块
到入相关的模块
2.数据探索
可参考下图的流程

3.数据清洗

baseline2:机器学习baseline
1.导入模块
导入机器学习所需要的xgboost,lightgbm,catboost等库。
XGBoost(Extreme Gradient Boosting)是一个强大的机器学习库,用于实现梯度提升决策树算法。
LightGBM 是一个高性能的梯度提升决策树框架,由 Microsoft 开发。它专为解决大规模数据集上的机器学习问题而设计,尤其适用于具有大量特征的数据集。
CatBoost(Categorical Boosting)是由 Yandex 开发的一个高性能的梯度提升决策树框架,特别适合处理具有大量类别特征的数据集。CatBoost 的设计目的是为了克服其他梯度提升框架(如 XGBoost 和 LightGBM)在处理类别特征时的一些局限性,它能够自动处理类别特征,无需进行预处理如独热编码(One-Hot Encoding)。
2.加载数据
3.构建训练样本
4.训练模型
5.测试集预测
baseline的优化方向
更多的优化方向,可以参考:1)扩大使用的训练数据;2)参数优化,学习率和迭代次数;3)特征优化
Top方案解析:
1.MAE+SwinTransformer,模型融合;
MAE(Masked Autoencoder)是一种基于Transformer架构的自监督学习方法。MAE 的核心思想是通过对图像进行随机遮挡(masking),然后利用未被遮挡的部分来重建被遮挡的部分,从而学习到强大的视觉表示。MAE的工作原理:1.输入图像处理;2.随机遮挡;3.解码器;4.损失计算。
下面是一个简化的 MAE 模型的 PyTorch 实现示例:
import torch
import torch.nn as nn
import torch.nn.functional as F
class MAE(nn.Module):
def __init__(self, encoder, decoder, mask_ratio=0.75):
super(MAE, self).__init__()
self.encoder = encoder
self.decoder = decoder
self.mask_ratio = mask_ratio
def forward(self, x):
# 编码
encoded_x = self.encoder(x)
# 随机遮挡
B, N, _ = encoded_x.shape
mask = torch.rand(B, N) < self.mask_ratio
mask = mask.to(x.device)
masked_encoded_x = encoded_x * (1 - mask.unsqueeze(-1))
# 解码
decoded_x = self.decoder(masked_encoded_x)
# 损失计算
loss = F.mse_loss(decoded_x[mask], encoded_x[mask])
return loss
# 创建一个简单的编码器
class SimpleEncoder(nn.Module):
def __init__(self):
super(SimpleEncoder, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1)
self.conv2 = nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1)
self.pool = nn.MaxPool2d(2, 2)
def forward(self, x):
x = F.relu(self.conv1(x))
x = self.pool(x)
x = F.relu(self.conv2(x))
x = self.pool(x)
return x
# 创建一个简单的解码器
class SimpleDecoder(nn.Module):
def __init__(self):
super(SimpleDecoder, self).__init__()
self.deconv1 = nn.ConvTranspose2d(128, 64, kernel_size=2, stride=2)
self.deconv2 = nn.ConvTranspose2d(64, 3, kernel_size=2, stride=2)
def forward(self, x):
x = F.relu(self.deconv1(x))
x = F.relu(self.deconv2(x))
return x
# 创建 MAE 实例
encoder = SimpleEncoder()
decoder = SimpleDecoder()
mae = MAE(encoder, decoder)
# 假设输入数据形状为 (batch_size, channels, height, width)
input_data = torch.randn(1, 3, 64, 64)
loss = mae(input_data)
print(loss.item())Swin Transformer 是一种基于 Transformer 架构的计算机视觉模型,由微软亚洲研究院 (MSRA) 提出。Swin Transformer 在视觉任务中展示了卓越的性能,尤其是在目标检测和实例分割等领域。它通过引入窗口注意力机制解决了传统 Transformer 在处理图像数据时面临的计算效率和内存消耗问题。Swin Transformer的特点:1.窗口注意力机制;2.层次结构;3.可扩展性;4.高效性;5.多尺度处理。Swin Transformer 的架构组成:1.Patch Embedding;2.Transformer Blocks;3.Shifted Window Attention;4.多尺度特征提取;5.自注意力替换
下面是一个简化的 Swin Transformer 模型的 PyTorch 实现示例:
import torch
import torch.nn as nn
import torch.nn.functional as F
class PatchEmbedding(nn.Module):
def __init__(self, in_channels, embed_dim, patch_size):
super(PatchEmbedding, self).__init__()
self.patch_size = patch_size
self.proj = nn.Conv2d(in_channels, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
_, _, H, W = x.shape
assert H % self.patch_size == 0 and W % self.patch_size == 0, "Image size must be divisible by patch size"
x = self.proj(x)
x = x.flatten(2).transpose(1, 2)
return x
class WindowAttention(nn.Module):
def __init__(self, dim, window_size, num_heads):
super(WindowAttention, self).__init__()
self.dim = dim
self.window_size = window_size
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim ** -0.5
self.qkv = nn.Linear(dim, dim * 3, bias=True)
self.softmax = nn.Softmax(dim=-1)
self.proj = nn.Linear(dim, dim)
def forward(self, x, mask=None):
B, N, C = x.shape
qkv = self.qkv(x).reshape(B, N, 3, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
q, k, v = qkv[0], qkv[1], qkv[2]
attn = (q @ k.transpose(-2, -1)) * self.scale
if mask is not None:
nW = mask.shape[0]
attn = attn.view(B // nW, nW, self.num_heads, N, N) + mask.unsqueeze(1).unsqueeze(0)
attn = attn.view(-1, self.num_heads, N, N)
attn = self.softmax(attn)
else:
attn = self.softmax(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
return x
class SwinTransformerBlock(nn.Module):
def __init__(self, dim, num_heads, window_size=7, mlp_ratio=4., qkv_bias=False, drop=0., attn_drop=0., drop_path=0.):
super(SwinTransformerBlock, self).__init__()
self.norm1 = nn.LayerNorm(dim)
self.attn = WindowAttention(dim, window_size=window_size, num_heads=num_heads)
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = nn.LayerNorm(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=nn.GELU, drop=drop)
def forward(self, x, mask_matrix):
B, L, H, W = x.shape
shortcut = x
x = self.norm1(x)
x = x.view(B, H, W, -1)
# pad feature maps to multiples of window size
pad_l = pad_t = 0
pad_r = (self.attn.window_size - W % self.attn.window_size) % self.attn.window_size
pad_b = (self.attn.window_size - H % self.attn.window_size) % self.attn.window_size
x = F.pad(x, (0, 0, pad_l, pad_r, pad_t, pad_b))
_, Hp, Wp, _ = x.shape
# cyclic shift
if mask_matrix is not None:
shifted_x = torch.roll(x, shifts=(-mask_matrix.shape[-2] // 2, -mask_matrix.shape[-1] // 2), dims=(1, 2))
else:
shifted_x = x
# partition windows
x_windows = window_partition(shifted_x, self.attn.window_size) # nW*B, window_size, window_size, C
x_windows = x_windows.view(-1, self.attn.window_size * self.attn.window_size, C) # nW*B, window_size*window_size, C
# W-MSA/SW-MSA
attn_windows = self.attn(x_windows, mask=self.attn_mask) # nW*B, window_size*window_size, C
# merge windows
attn_windows = attn_windows.view(-1, self.attn.window_size, self.attn.window_size, C)
shifted_x = window_reverse(attn_windows, self.attn.window_size, Hp, Wp) # B H' W' C
# reverse cyclic shift
if mask_matrix is not None:
x = torch.roll(shifted_x, shifts=(mask_matrix.shape[-2] // 2, mask_matrix.shape[-1] // 2), dims=(1, 2))
else:
x = shifted_x
if pad_r > 0 or pad_b > 0:
x = x[:, :H, :W, :].contiguous()
x = x.view(B, H * W, C)
# FFN
x = shortcut + self.drop_path(x)
x = x + self.drop_path(self.mlp(self.norm2(x)))
return x
class SwinTransformer(nn.Module):
def __init__(self, img_size=224, in_channels=3, embed_dim=96, depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24]):
super(SwinTransformer, self).__init__()
self.patch_embed = PatchEmbedding(in_channels=in_channels, embed_dim=embed_dim, patch_size=4)
self.layers = nn.ModuleList()
for i in range(len(depths)):
layer = nn.ModuleList()
for j in range(depths[i]):
layer.append(SwinTransformerBlock(dim=int(embed_dim * 2 ** i), num_heads=num_heads[i]))
self.layers.append(layer)
def forward(self, x):
x = self.patch_embed(x)
for layer in self.layers:
for block in layer:
x = block(x)
return x
# 创建 Swin Transformer 实例
model = SwinTransformer()
# 假设输入数据形状为 (batch_size, channels, height, width)
input_data = torch.randn(1, 3, 224, 224)
output = model(input_data)
print(output.shape)2.并行时间编码自回归,3D-U形框架,编码,解码,ViT,多模型集成;
ViT(Vision Transformer)是一种基于Transformer架构的计算机视觉模型,ViT 将传统的Transformer模型,原本用于自然语言处理(NLP)领域的成功经验,扩展到了计算机视觉领域,并在图像识别任务上取得了显著的效果。
ViT的工作原理:1.Patch Embedding;2.Positional Encoding;3.Transformer Encoder Layers;4.Classification Token;5.输出。
ViT的特点:1.自注意力机制;2.灵活性;3.高效性;4.可扩展性;5.多任务能力。
下面是一个简化的 ViT 模型的 PyTorch 实现示例:
import torch
import torch.nn as nn
import math
class PatchEmbedding(nn.Module):
def __init__(self, in_channels, patch_size, embed_dim):
super(PatchEmbedding, self).__init__()
self.patch_size = patch_size
self.proj = nn.Conv2d(in_channels, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
_, _, H, W = x.shape
assert H % self.patch_size == 0 and W % self.patch_size == 0, "Image size must be divisible by patch size"
x = self.proj(x)
x = x.flatten(2).transpose(1, 2)
return x
class PositionalEncoding(nn.Module):
def __init__(self, max_length, embed_dim):
super(PositionalEncoding, self).__init__()
self.pe = nn.Parameter(torch.zeros(1, max_length, embed_dim))
def forward(self, x):
x = x + self.pe[:, :x.size(1)]
return x
class MultiHeadSelfAttention(nn.Module):
def __init__(self, embed_dim, num_heads):
super(MultiHeadSelfAttention, self).__init__()
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = embed_dim // num_heads
self.query = nn.Linear(embed_dim, embed_dim)
self.key = nn.Linear(embed_dim, embed_dim)
self.value = nn.Linear(embed_dim, embed_dim)
self.out = nn.Linear(embed_dim, embed_dim)
def forward(self, x):
B, N, C = x.shape
q = self.query(x).view(B, N, self.num_heads, self.head_dim).transpose(1, 2)
k = self.key(x).view(B, N, self.num_heads, self.head_dim).transpose(1, 2)
v = self.value(x).view(B, N, self.num_heads, self.head_dim).transpose(1, 2)
attn = (q @ k.transpose(-2, -1)) * (self.head_dim ** -0.5)
attn = attn.softmax(dim=-1)
out = (attn @ v).transpose(1, 2).reshape(B, N, C)
out = self.out(out)
return out
class TransformerEncoderLayer(nn.Module):
def __init__(self, embed_dim, num_heads, mlp_ratio, dropout):
super(TransformerEncoderLayer, self).__init__()
self.norm1 = nn.LayerNorm(embed_dim)
self.mhsa = MultiHeadSelfAttention(embed_dim, num_heads)
self.norm2 = nn.LayerNorm(embed_dim)
self.mlp = nn.Sequential(
nn.Linear(embed_dim, int(embed_dim * mlp_ratio)),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(int(embed_dim * mlp_ratio), embed_dim),
nn.Dropout(dropout)
)
def forward(self, x):
x = x + self.mhsa(self.norm1(x))
x = x + self.mlp(self.norm2(x))
return x
class VisionTransformer(nn.Module):
def __init__(self, img_size=224, in_channels=3, patch_size=16, embed_dim=768, num_heads=12, depth=12, mlp_ratio=4., num_classes=1000):
super(VisionTransformer, self).__init__()
self.patch_embed = PatchEmbedding(in_channels, patch_size, embed_dim)
self.pos_encoding = PositionalEncoding((img_size // patch_size) ** 2 + 1, embed_dim)
self.class_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.layers = nn.ModuleList([TransformerEncoderLayer(embed_dim, num_heads, mlp_ratio, 0.1) for _ in range(depth)])
self.norm = nn.LayerNorm(embed_dim)
self.fc = nn.Linear(embed_dim, num_classes)
def forward(self, x):
x = self.patch_embed(x)
class_token = self.class_token.expand(x.shape[0], -1, -1)
x = torch.cat([class_token, x], dim=1)
x = self.pos_encoding(x)
for layer in self.layers:
x = layer(x)
x = self.norm(x)
x = self.fc(x[:, 0])
return x
# 创建 ViT 实例
model = VisionTransformer()
# 假设输入数据形状为 (batch_size, channels, height, width)
input_data = torch.randn(1, 3, 224, 224)
output = model(input_data)
print(output.shape)3.SwinTransformer,自回归方法;
4.Video Swin Transformer(VST);
Video Swin Transformer (VST) 是一种基于 Swin Transformer 的扩展模型,专门设计用于处理视频数据。它继承了Swin Transformer的核心思想,即利用窗口注意力机制来提高计算效率,同时通过引入时间维度来处理视频中的动态信息。
写完了,喜欢的小伙伴,点赞收藏加关注吧。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









